Добрый день! В этой статье я расскажу, как наши заказчики используют ПЛИС в полунатурных стендах и стендовых испытаниях.
В центре инженерных технологий и моделирования «Экспонента» уже много лет мы занимаемся продвижением модельно-ориентированного проектирования в России. Поэтому наш опыт сконцентрирован вокруг инструментов модельно-ориентированного проектирования — то есть различных сред моделирования и симуляции — и применения их в инженерных разработках.
Эта статья написана совместно с нашими хорошими партнерами — компанией «РИТМ». Компания занимается разработкой полунатурных стендов и комплексов полунатурного моделирования «РИТМ» (КПМ «РИТМ»), которые используются нашими заказчиками.
КПМ «РИТМ» представляет собой программно-аппаратное решение для тестирования в реальном времени. Спектр его применений широкий: от быстрого прототипирования алгоритмов управления до полунатурного моделирования объекта управления (Hardware-in-the-Loop или HIL тестирование). РИТМ применяется нашими заказчиками в различных инженерных областях: от авиастроения и ВПК до автомобилестроения и электроэнергетики.
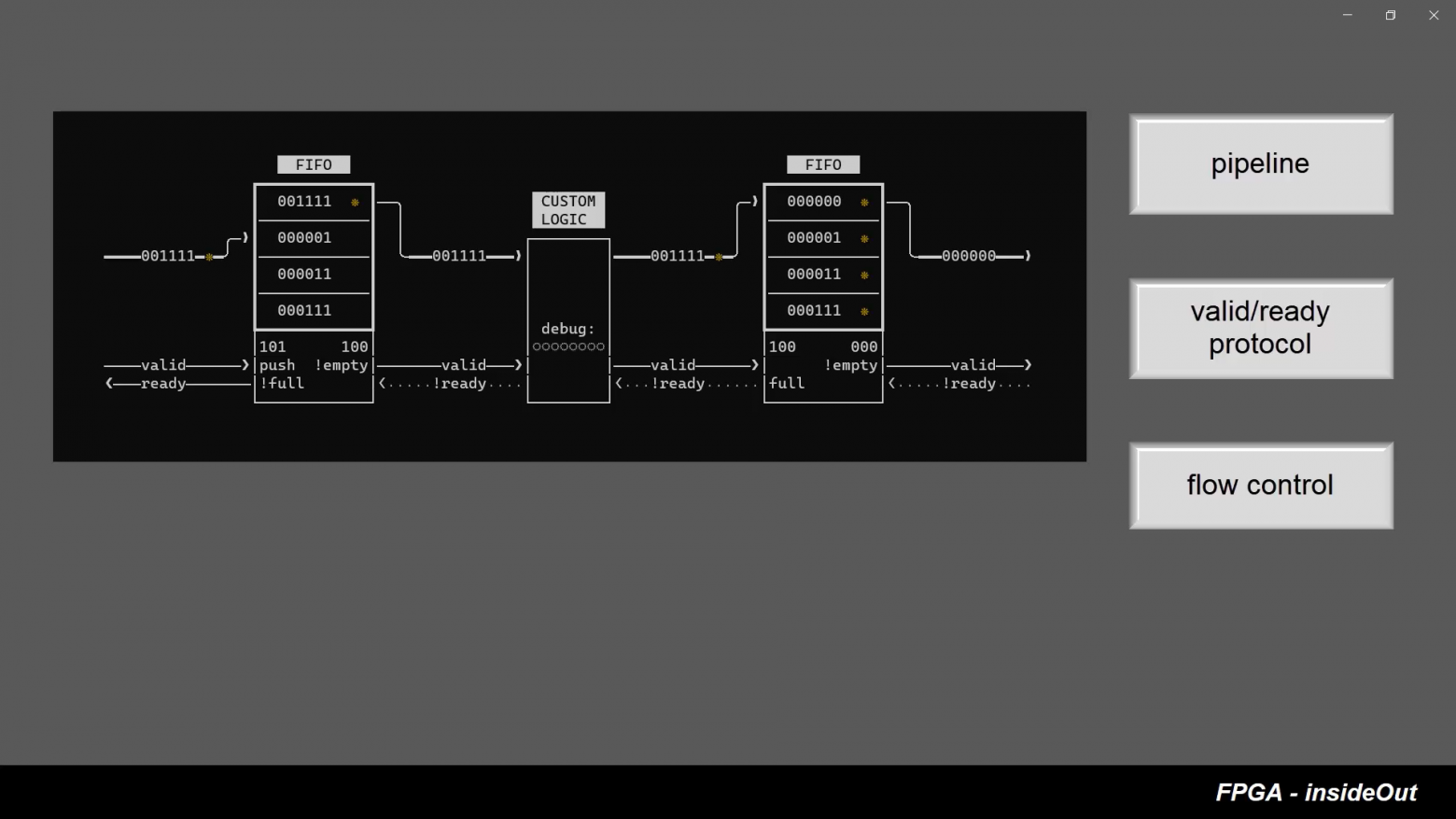
КПМ «РИТМ» поставляется настроенным «под ключ» под задачи проекта или стенда, и оснащен всеми необходимыми модулями ввода-вывода (аналоговыми, цифровыми, специализированными интерфейсами и протоколами). Пользователи могут быстро и бесшовно запускать свои модели в реальном времени (содержащие алгоритмы или модели объекта управления) и подключать их к реальным устройствам (например, блоку управления или исполнительным механизмам) через модули ввода-вывода.
Наши заказчики успешно используют этот подход уже многие годы, но в некоторых узких задачах сталкиваются со следующими проблемами:
• Необходимо существенно сократить шаг расчета алгоритма;
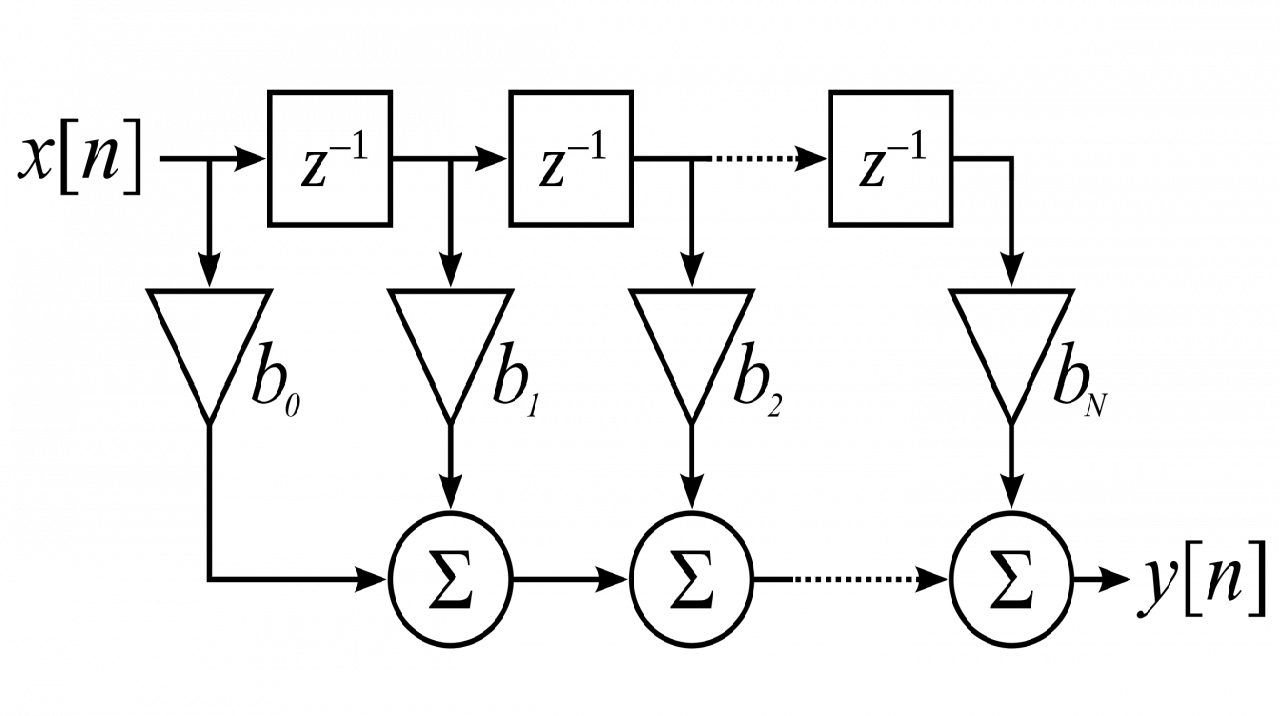
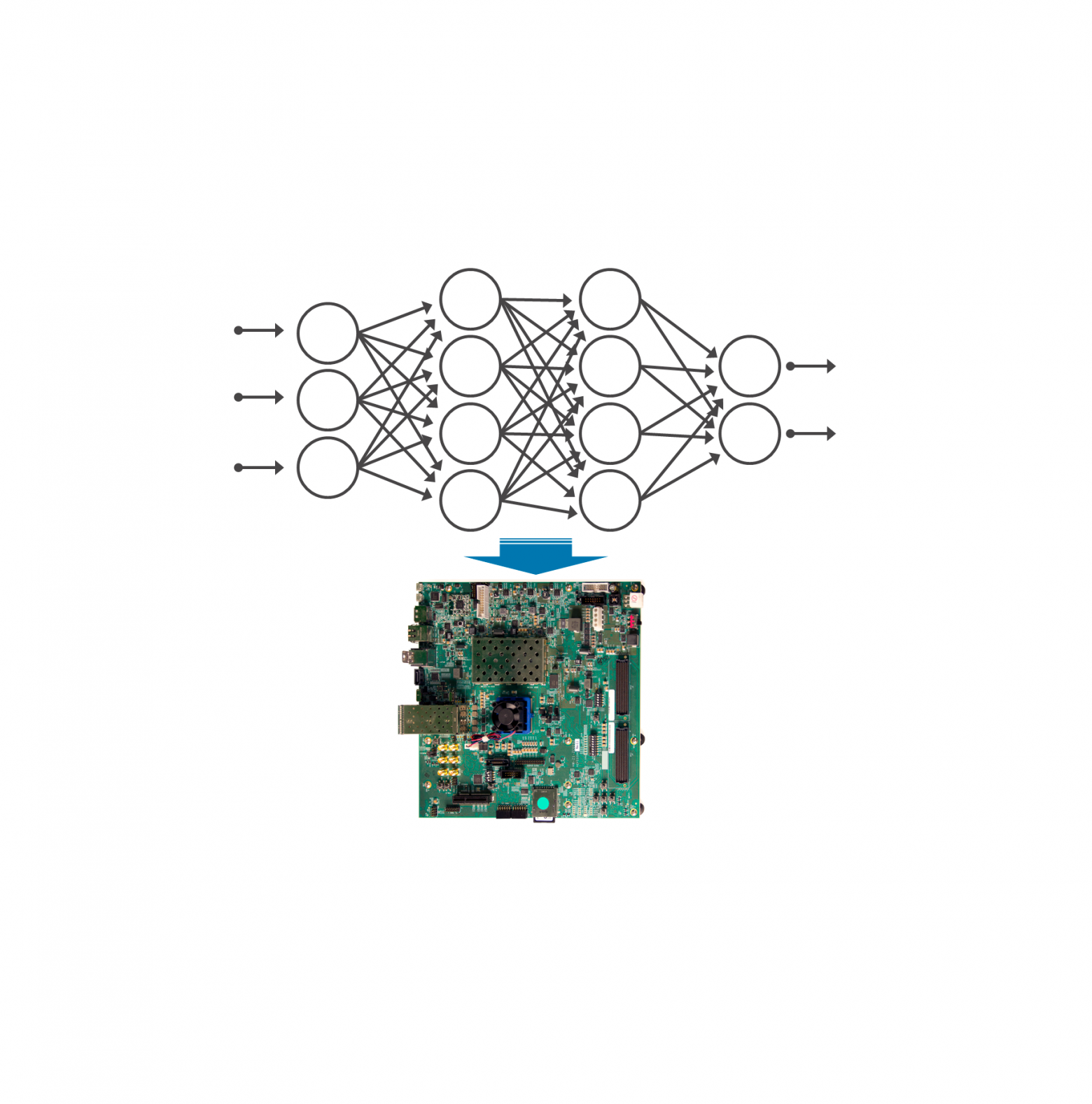
• Не хватает вычислительных ресурсов для решения задачи в реальном времени на процессоре;
• Требуется подключить к алгоритму высокоскоростные цифровые, аналоговые или другие интерфейсы;
• Требуется поддержать заказные интерфейсы или протоколы обмена.
Если вы тоже сталкиваетесь с такими проблемами, то добро пожаловать под кат — даже если вы раньше никогда не слышали о модельно-ориентированном проектировании или ПЛИС.