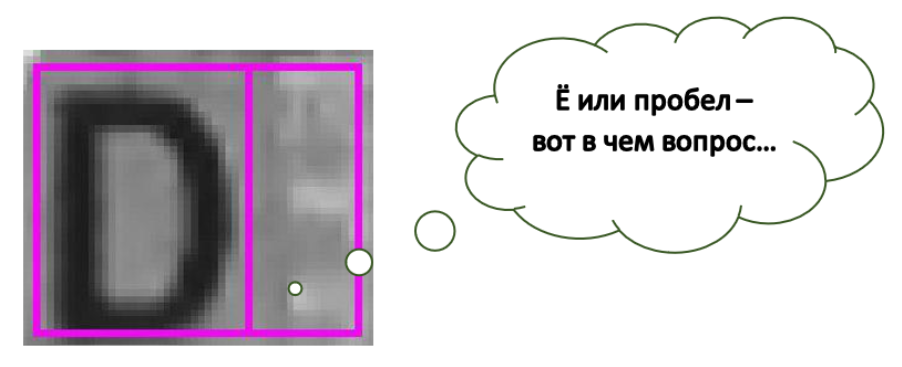
Спецификация по отзывчивым изображениям — это фантастический документ, в котором описано множество вариантов использования таких изображений. Но опыт подсказывает мне, что чаще всего при работе с ними нужно знать лишь о том, как отдавать клиенту копии одного и того же изображения разного размера, выбирая их в зависимости от ширины области просмотра страницы. Мы называем это «переключением разрешения». Для решения этой задачи можно воспользоваться атрибутами
srcset и
sizes.
Вывод отзывчивых изображений предусматривает применение достаточно сложной логики. Сюда, кроме прочего, входит определение того, изображение какого размера будет выведено, а также выяснение того, работает ли пользователь с экраном высокого разрешения. К счастью, браузеры лучше, чем люди, умеют определять то, какие именно изображения лучше всего подходят каждому конкретному пользователю. Всё, что нам нужно — это дать им некоторые подсказки. Атрибут
srcset даёт браузеру список графических ресурсов, из которых он может выбирать наиболее подходящее изображение. Атрибут
sizes позволяет сообщить браузеру о том, изображение какого размера нужно показать в том или ином случае.

И, кстати, пользуясь отзывчивыми изображениями можно не беспокоиться о браузерной поддержке этой технологии. Интересующие нас атрибуты пользуются
прекрасной поддержкой браузеров. И, кроме того, в нашем распоряжении имеется резервный механизм, предназначенный для старых браузеров вроде IE11.

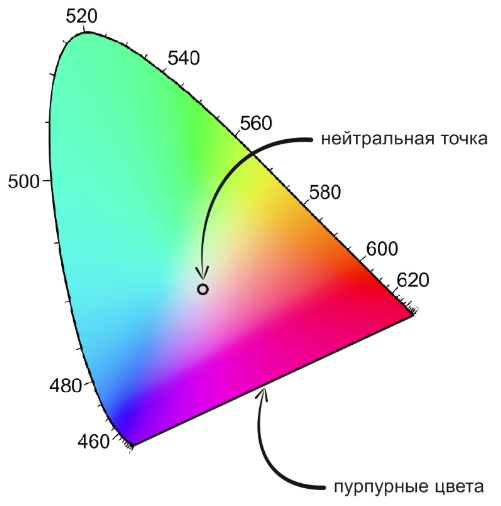 Больше пяти лет мы публикуем на Хабре статьи на различные темы компьютерного зрения. Чаще всего они связаны с распознаванием документов, потому что нам всегда очень не терпится поделиться с вами всем крутым и новым, что мы сделали в Smart IDReader. Хотя мы честно стараемся изложить наши знания в «универсальном» ключе, чтобы вы, наши читатели Хабра, могли легко их использовать в своих проектах и стартапах. Сегодня мы решили пойти дальше и представить широкой аудитории фундаментальный математически стройный материал на тему цвета, изложенный простыми словами.
Больше пяти лет мы публикуем на Хабре статьи на различные темы компьютерного зрения. Чаще всего они связаны с распознаванием документов, потому что нам всегда очень не терпится поделиться с вами всем крутым и новым, что мы сделали в Smart IDReader. Хотя мы честно стараемся изложить наши знания в «универсальном» ключе, чтобы вы, наши читатели Хабра, могли легко их использовать в своих проектах и стартапах. Сегодня мы решили пойти дальше и представить широкой аудитории фундаментальный математически стройный материал на тему цвета, изложенный простыми словами.