Привет, Хабр! Представляю вам перевод статьи.
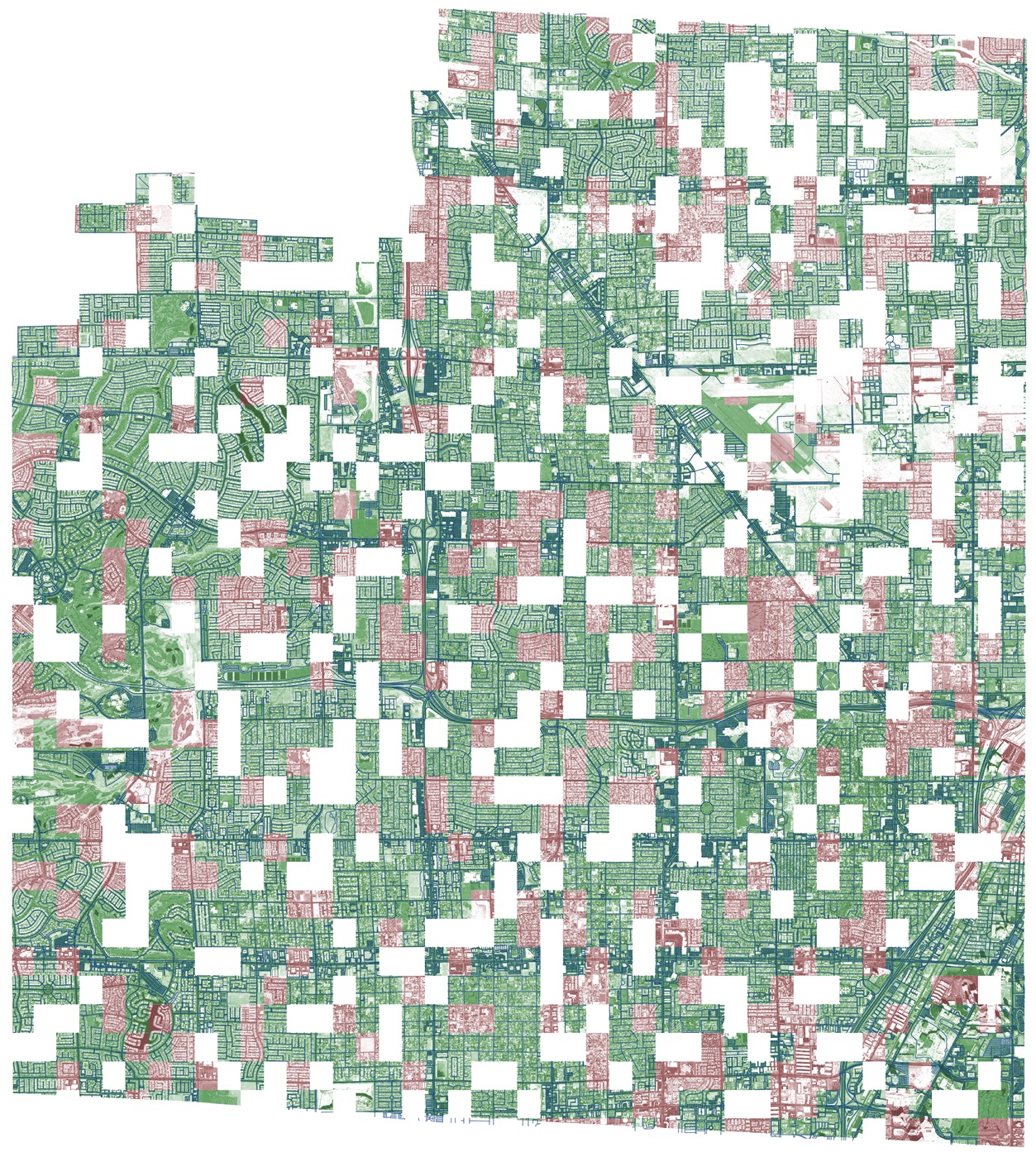
Это Вегас с предоставленной разметкой, тестовым датасетом и вероятно белые квадраты — это отложенная валидация (приват). Выглядит прикольно. Правда эта панорама лучшая из всех четырех городов, так вышло из-за данных, но об этом чуть ниже.
0. TLDR
Ссылка на соревнование и подробное описание.
Быстрая картинка сайта, кому лень ходить.
Мы закончили предварительно на 9-м месте, но позиция может измениться после дополнительного тестирования сабмитов организаторами.
Также я потратил некоторое время на написание хорошего читаемого кода на PyTorch и генераторов данных. Его можно без застенчивости использовать для своих целей (только поставьте плюсик). Код максимально простой и модульный, плюс читайте дальше про best practices для семантической сегментации.
Кроме того, не исключено, что мы напишем пост про понимание и разбор Skeleton Network, которую в итоге использовали все финалисты в топе соревнования для преобразования маски изображения в граф.
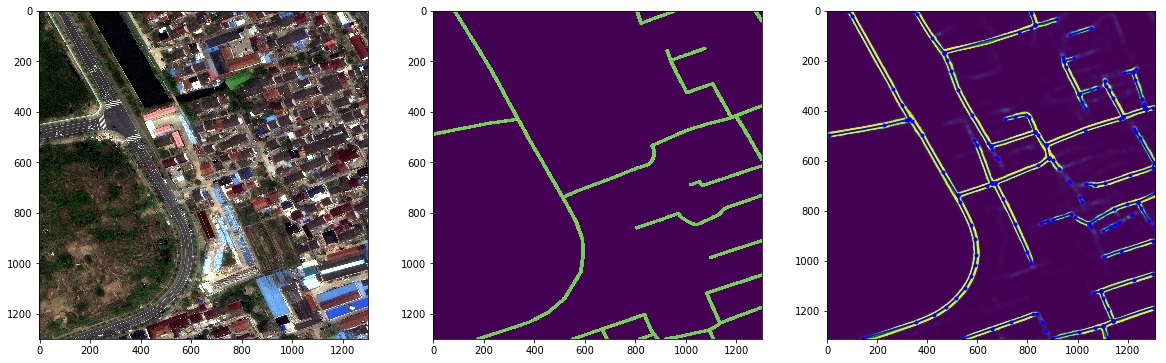
Суть соревнования на 1 картинке

 , и добро пожаловать под кат.
, и добро пожаловать под кат. С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
 В последнее время машины одержали ряд убедительных побед над людьми: они уже лучше играют в го, шахматы и даже в Dota 2. Алгоритмы сочиняют музыку и пишут стихи. Учёные и предприниматели всего мира дают прогнозы по поводу будущего, в котором искусственный интеллект сильно превзойдёт человека. С большой вероятностью через несколько десятков лет мы будем жить в мире, в котором роботы не только водят автомобили и работают на заводах, но и развлекают нас. Одна из важных составляющих нашей жизни — юмор. Принято считать, что только человек может придумывать шутки. Несмотря на это, многие ученые, инженеры и даже простые обыватели задаются вопросом: можно ли научить компьютер шутить?
В последнее время машины одержали ряд убедительных побед над людьми: они уже лучше играют в го, шахматы и даже в Dota 2. Алгоритмы сочиняют музыку и пишут стихи. Учёные и предприниматели всего мира дают прогнозы по поводу будущего, в котором искусственный интеллект сильно превзойдёт человека. С большой вероятностью через несколько десятков лет мы будем жить в мире, в котором роботы не только водят автомобили и работают на заводах, но и развлекают нас. Одна из важных составляющих нашей жизни — юмор. Принято считать, что только человек может придумывать шутки. Несмотря на это, многие ученые, инженеры и даже простые обыватели задаются вопросом: можно ли научить компьютер шутить? 









 Если отвлечься от съемки с помощью беспилотных летательных аппаратов (БПЛА) свадеб, торжеств и юбилеев, то становится очевидным, что в арсенале специалистов по картографированию территорий, экологов и военных появился мощный инструмент в работе — промышленные беспилотные аппараты, которые способны решать различные задачи по построению качественной картографической информации, подробных ортофотопланов территорий, лесов, сельскохозяйственных угодий и городских территорий. Учитывая тот факт, что получить качественный фотографический материал для построения 3D моделей местности только с первого взгляда кажется простым делом, в действительности — задача имеет массу всяческих особенностей. Захотелось поделиться собственным опытом организации промышленной аэрофотосъемки, местом расположения граблей, на которые пришлось наступить, а вернее — на которые пришлось налететь. За всеми подробностями прошу под кат.
Если отвлечься от съемки с помощью беспилотных летательных аппаратов (БПЛА) свадеб, торжеств и юбилеев, то становится очевидным, что в арсенале специалистов по картографированию территорий, экологов и военных появился мощный инструмент в работе — промышленные беспилотные аппараты, которые способны решать различные задачи по построению качественной картографической информации, подробных ортофотопланов территорий, лесов, сельскохозяйственных угодий и городских территорий. Учитывая тот факт, что получить качественный фотографический материал для построения 3D моделей местности только с первого взгляда кажется простым делом, в действительности — задача имеет массу всяческих особенностей. Захотелось поделиться собственным опытом организации промышленной аэрофотосъемки, местом расположения граблей, на которые пришлось наступить, а вернее — на которые пришлось налететь. За всеми подробностями прошу под кат. 

