
DetectNet: Deep Neural Network для Object Detection в DIGITS
Привет Хабр. В последнее время мне очень нравится читать статьи на тему deep learning, сверточные сети, обработка изображений и т.д. Действительно, тут есть очень крутые статьи, которые поражают и вдохновляют на собственные "более скромные" подвиги. Итак, хочу представить вниманию русскоязычной публики перевод статьи от Nvidia, написанной 11 августа 2016, в которой представлен их новый инструмент DIGITS и сеть DetectNet для обнаружения объектов на изображениях. Оригинальная статья, конечно, может показаться вначале немного рекламной, да и сеть DetectNet ничего "революционного" не представляет, но комбинация инструмента DIGITS и сети DetectNet, мне кажется, может быть интересной для всех.
Сегодня с помощью NVIDIA Deep Learning GPU Training System (DIGITS) исследователи-аналитики имеют в своем распоряжении всю мощью глубокого обучения (deep learning) для решения самых общих задач в этой области, таких как: подготовка данных, определение сверточной сети, параллельное обучение нескольких моделей, наблюдение за процессом обучения в реальном времени, а также выбор лучшей модели. Полностью интерактивный инструмент DIGITS избавляет вас от программирования и отладки и вы занимаетесь только дизайном и обучением сети.
 В свободном доступе появилась реализация интересных графических или анимированных QR кодов.
В свободном доступе появилась реализация интересных графических или анимированных QR кодов.





 В этой статье речь пойдет о проверке еще одного известного open source проекта — векторного графического редактора Inkscape 0.92. Проект развивается уже более 12 лет и предоставляет множество возможностей по работе с различными форматами векторных иллюстраций. За это время его кодовая база выросла до 600 тысяч строк, и пришло время проверить его с помощью статического анализатора PVS-Studio.
В этой статье речь пойдет о проверке еще одного известного open source проекта — векторного графического редактора Inkscape 0.92. Проект развивается уже более 12 лет и предоставляет множество возможностей по работе с различными форматами векторных иллюстраций. За это время его кодовая база выросла до 600 тысяч строк, и пришло время проверить его с помощью статического анализатора PVS-Studio.
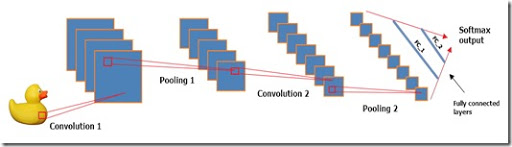




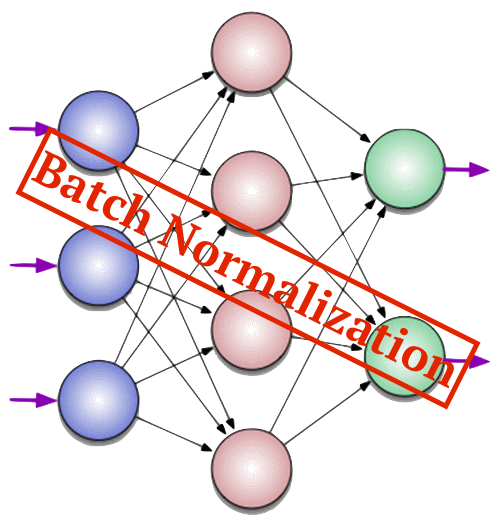
 Но для начала – маленькое отступление. Систему распознавания текста в наших продуктах можно описать очень просто. У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы. Задача сегментации ставится примерно так: есть страница, надо её декомпозировать на текстовые и нетекстовые элементы.
Но для начала – маленькое отступление. Систему распознавания текста в наших продуктах можно описать очень просто. У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы. Задача сегментации ставится примерно так: есть страница, надо её декомпозировать на текстовые и нетекстовые элементы. 