В интернетах не прекращается хайп вокруг чат-ботов (в частности, Telegram) благодаря шуму в СМИ, неоспоримых достоинствах платформы, политике продвижения, средствам разработки и т.д.

Смотришь новости: ну
жизни нет без чат-ботов!
Да если их не будет, поезда с рельс сойдут, упадут самолеты, погибнут люди от тоски, когда не смогут найти картинки с котиками.
Но давайте положим руку на сердце: когда последний раз вы что-то заказывали в интернет-магазине
через чат-бот?
Кто все эти люди, которые заказывают разработку ботов для своих магазинов?
Типичный чат-бот магазина Vasya Limited:
>> автоматизирует
поток водопад заявок из
5 человек в день,
>> сливает 4 из 5 заявок, кровью добытых через Яндекс-Директ,
>> если повезет, человек найдет номер телефона и позвонит,
>> но, вероятней всего, «Эээ, куда жать?», а потом закроет и уйдет гуглить дальше.
Чем занят владелец, когда продажи «автоматизированы»:
>> вносит заказы в excel-таблицу
>> заполняет почтовые бланки на посылках
>> стоит в очереди на почте с кучей посылок (каждый день!)
>> вносит трек номера в excel-таблицу, затем рассылает клиентам
Может, хватит на ровном месте встраивать «технологии» туда, где действительно нужен человек, в то время как люди загружены рутиной для роботов?




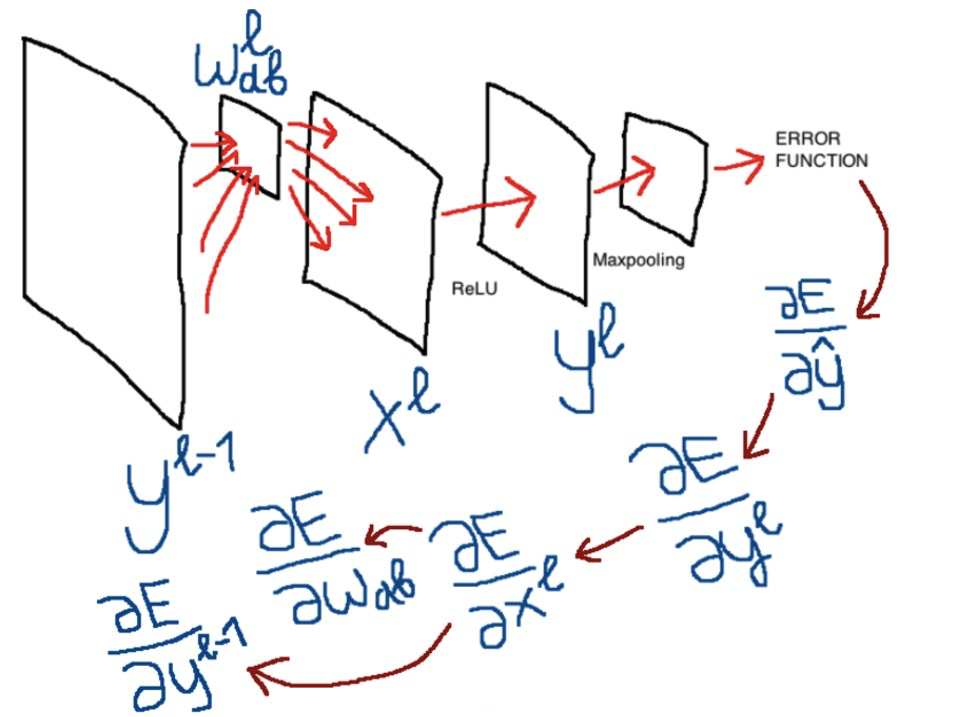

 Apple начала использовать глубинное обучение для определения лиц начиная с iOS 10. С выпуском фреймворка Vision разработчики теперь могут использовать в своих приложениях эту технологию и многие другие алгоритмы машинного зрения. При разработке фреймворка пришлось преодолеть значительные проблемы, чтобы сохранить приватность пользователей и эффективно работать на железе мобильного устройства. В статье обсуждаются эти проблемы и описывается, как работает алгоритм.
Apple начала использовать глубинное обучение для определения лиц начиная с iOS 10. С выпуском фреймворка Vision разработчики теперь могут использовать в своих приложениях эту технологию и многие другие алгоритмы машинного зрения. При разработке фреймворка пришлось преодолеть значительные проблемы, чтобы сохранить приватность пользователей и эффективно работать на железе мобильного устройства. В статье обсуждаются эти проблемы и описывается, как работает алгоритм.