Сегодня в магазине Google Play пестрят цветами одинаковые прямоугольники со скругленными углами, под каждым из которых очередное тач-приложение, где нужно тыкать пальцем в три кнопки, играя в игры а ля тауэр-дефэнс, а ля катапульты с физикой, а ля более навороченные 3D проекты с видом сверху в изометрии, где крошишь одной кнопкой мобов по десять штук в секунду огромным мечом, а ля аналогичные проекты с мирной постройкой зданий раз в N минут и донатом в кристаллы, за которые здания строятся быстрее…
Там же в дальнем углу гугл-плэя лежат Утилиты, которые либо по 300-500(-700) рублей пылятся в ожидании покупателя, либо урезанные демо-версии/версии с рекламой со всех сторон.
Но так было не всегда. 10 лет назад веселое сообщество разработчиков мобильных приложений производило тонны полезных программ. В те времена не было Андроида, а царила везде Java 2 Microedition — урезанная версия явы для слабых мобильных устройств.
В те времена был не 4G LTE интернет, а, в основном, медленный GPRS (2G, 5 килобайт в секунду, как диалап модем по скорости) и появляющийся модный EDGE (2,5G, 30 килобайт в секунду!).
В те времена не было рекламы в приложениях, поэтому приложения делали не те, кто хочет навариться на пользователях, вставляя рекламу во всех местах где нужно и не нужно, а те, кто хочет принести пользу и создать забавные вещи, которые будут полезны людям. Конечно, приложения и игры продавали через всяческие сервисы «отправь смс на номер...», но защиты почти никакой не было и исполняемые JAR файлы мобильных ява-приложений валялись всюду в интернете.
На мелком экранчике типа 101х80 или 128х128, а затем на 132х176 и 240х320, людьми использовалась масса всевозможных утилит. На забитом приложениями телефоне (с объемом внутренней флешки всего около 1-5 Мбайт) обязательно стоял:
— email клиент,
— ftp клиент,
— текстовый/html редактор,
— качающий через GRPS веб-страницы и парсящий их html браузер (Оперы Мини еще не было),
— редактор MIDI мелодий,
— фото-редактор (для маломощных мобильных камер типа 0,3 мегапикселя или 640х480 точек, обычно в телефоне с камерой стояло подобное родное приложение для правки яркости/контраста/наложения рамок на фото),
— мобильный бейсик, в нем можно было писать программы для телефона, а потом запаковать внутрь исполняемого JAR (ZIP) файла бейсика свою прогу с ресурсами так, что при запуске этого JAR сразу будет ее автозапуск. Таким образом, можно было делать свои программы на своем же телефоне, а потом распространять их через интернет.
Многие пользователи делали свои сайты на бесплатных хостингах, писали html код, вставляли туда картинки, анимации, потом через ftp клиент выкладывали все это на хостинг, загружая туда же свои программы на мобильном бейсике, а также коллекции обоев, мелодий, звуков, видео для телефона.
И это было только на поверхности уровня пользователя. (ниже были ребята, которые прошивали телефоны спецпрошивками и могли запускать программы особенного формата сразу на процессоре телефона, разумеется, они работали быстрее явы.)
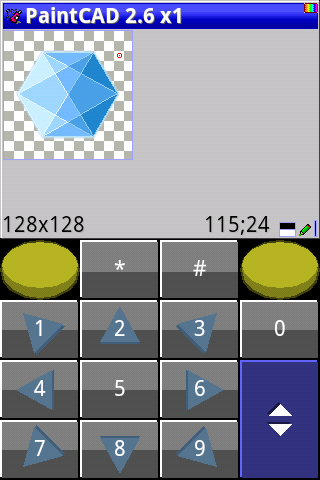
В этой обучающей статье я расскажу вам, как сегодня можно рисовать пиксель арт на одном из динозавров из той эпохи j2me — PaintCAD Mobile. Вам потребуется телефон на Android 2.3 или новее. С помощью этой программы вы сможете нарисовать любые картинки, например, для мобильного/компьютерного сайта или графику для игры, сделать GIF анимации для сайта, использовать растровые PCF шрифты на своих картинках (и даже сделать эти шрифты сами). В этой статье рассмотрим самые простые функции: рисование, инструменты, палитру, немного эффектов.










 При съемке книжного разворота с помощью камеры мобильного устройства неизбежно возникают некоторые из нижеперечисленных дефектов (а возможно, что и все сразу):
При съемке книжного разворота с помощью камеры мобильного устройства неизбежно возникают некоторые из нижеперечисленных дефектов (а возможно, что и все сразу):

