Видео @Databases Meetup: Percona, Postgres Pro, Tarantool и MCS
2 мин

Всем привет! 25 июня прошел второй митап серии @Databases, организованный Mail.ru Cloud Solutions совместно с Tarantool. Переход в онлайн никого не обходит стороной, но даже на удаленке нам удалось собрать вместе более 400 участников, чтобы обсудить актуальные проблемы современных производительных баз данных.
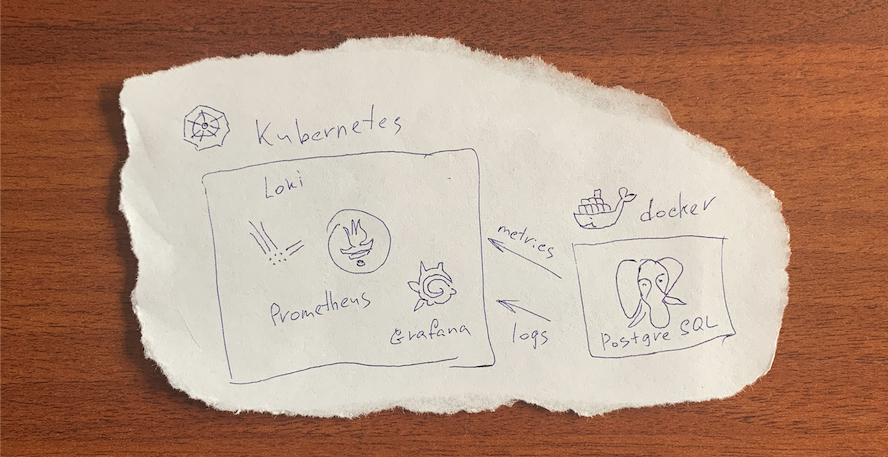
Под катом видео выступлений: Percona о том, как собрать гибридное облако с помощью K8s, которое заменит DBaaS; Postgres Pro сразу с двумя докладами — рассказали все о JSON[b] в Postgres, а также поделились стратегическими планами по развитию базы данных; а Mail.ru Cloud Solutions — как S3-хранилище эволюционировало за свои три года в проде и вместе с ним менялся подход к Tarantool в его архитектуре.