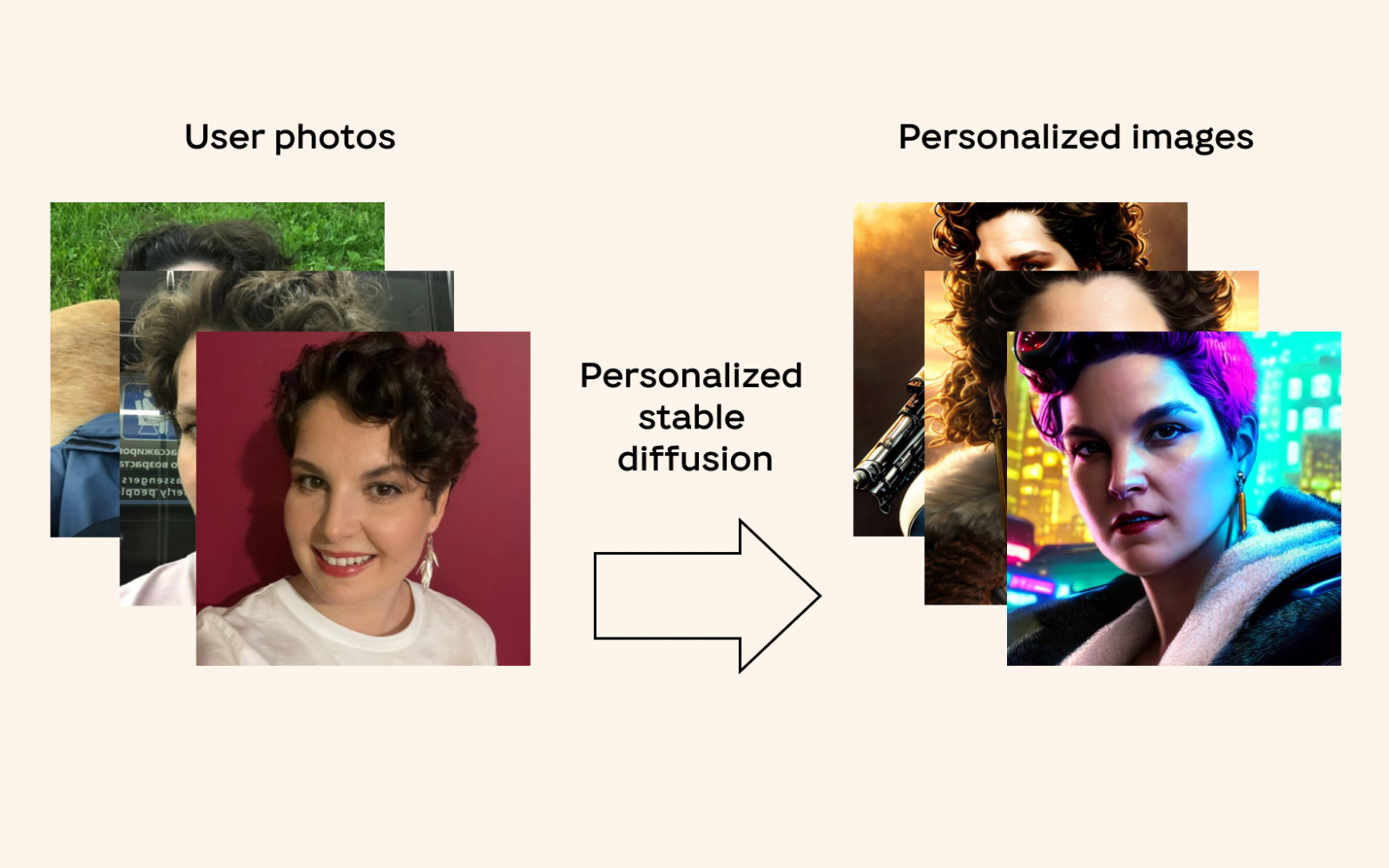
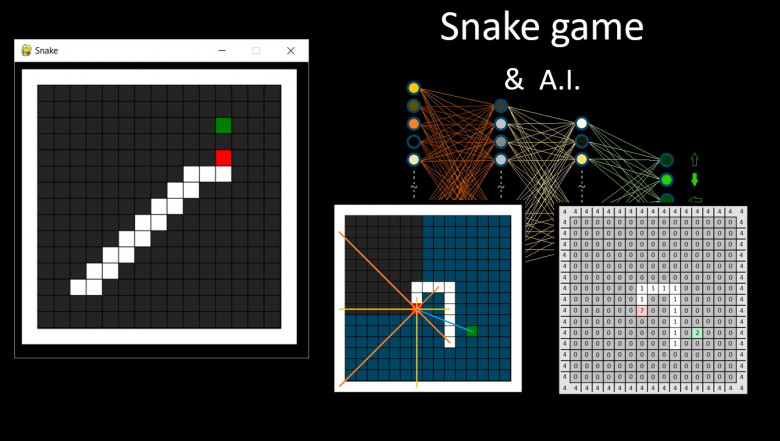
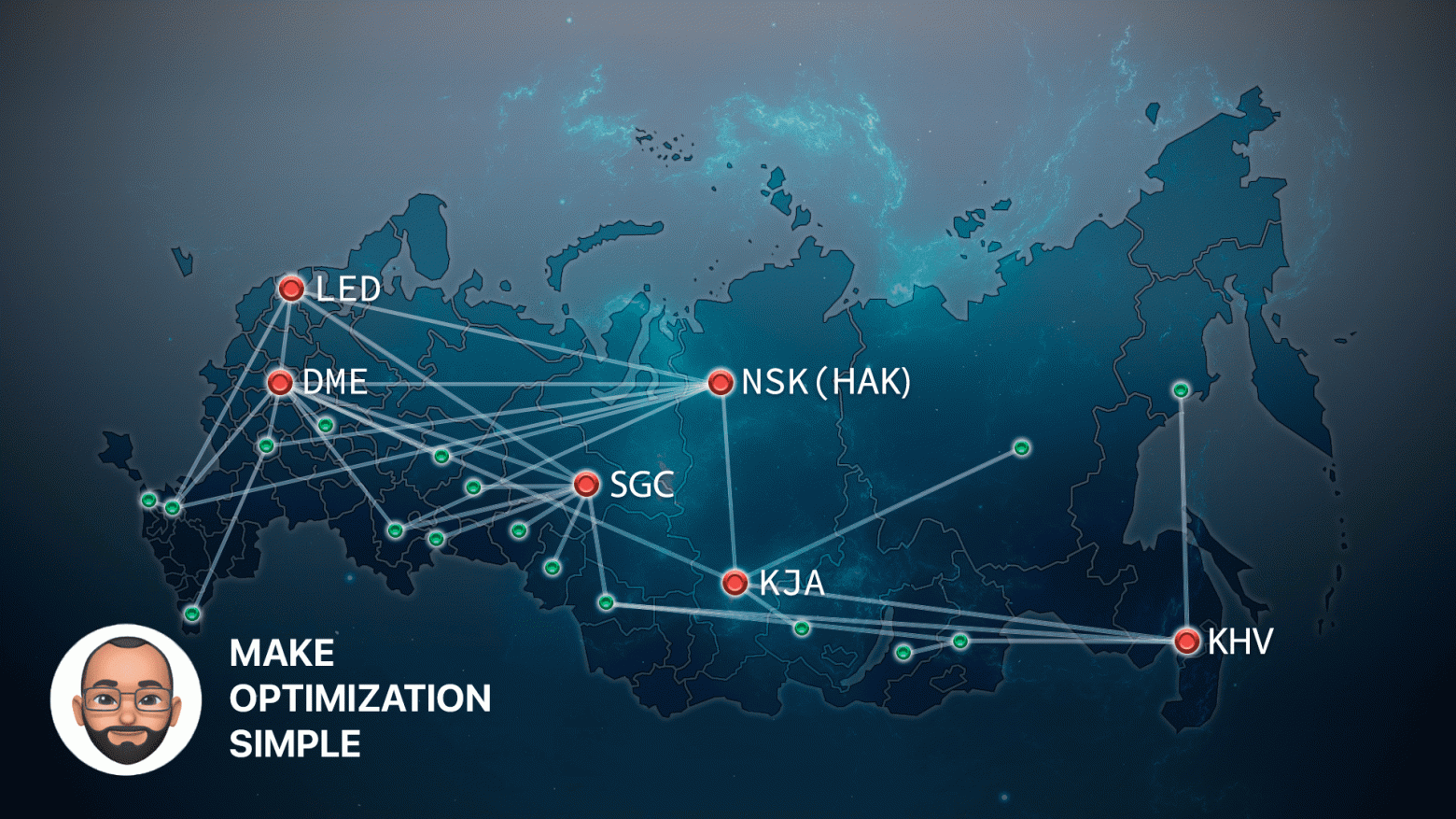
Введение в архитектуру MLOps

Привет, Хабр!
MLOps, или Machine Learning Operations, это практика объединения машинного обучения и операционных процессов. Она направлена на упрощение и ускорение цикла разработки, тестирования, развертывания и мониторинга моделей машинного обучения. В MLOps применяются принципы DevOps, такие как автоматизация, непрерывная интеграция и доставка, для создания более эффективных и масштабируемых решений в области машинного обучения.
Объемы данных растут экспоненциально, способность быстро и эффективно обрабатывать эти данные становится ключевой для успеха. MLOps позволяет не просто создавать модели машинного обучения, но и быстро адаптироваться к изменениям, обновлять модели и поддерживать их работоспосоность на высоком уровне. Это важно, поскольку модель, которая работала хорошо вчера, может устареть сегодня из-за изменения данных или условий окружающей среды.