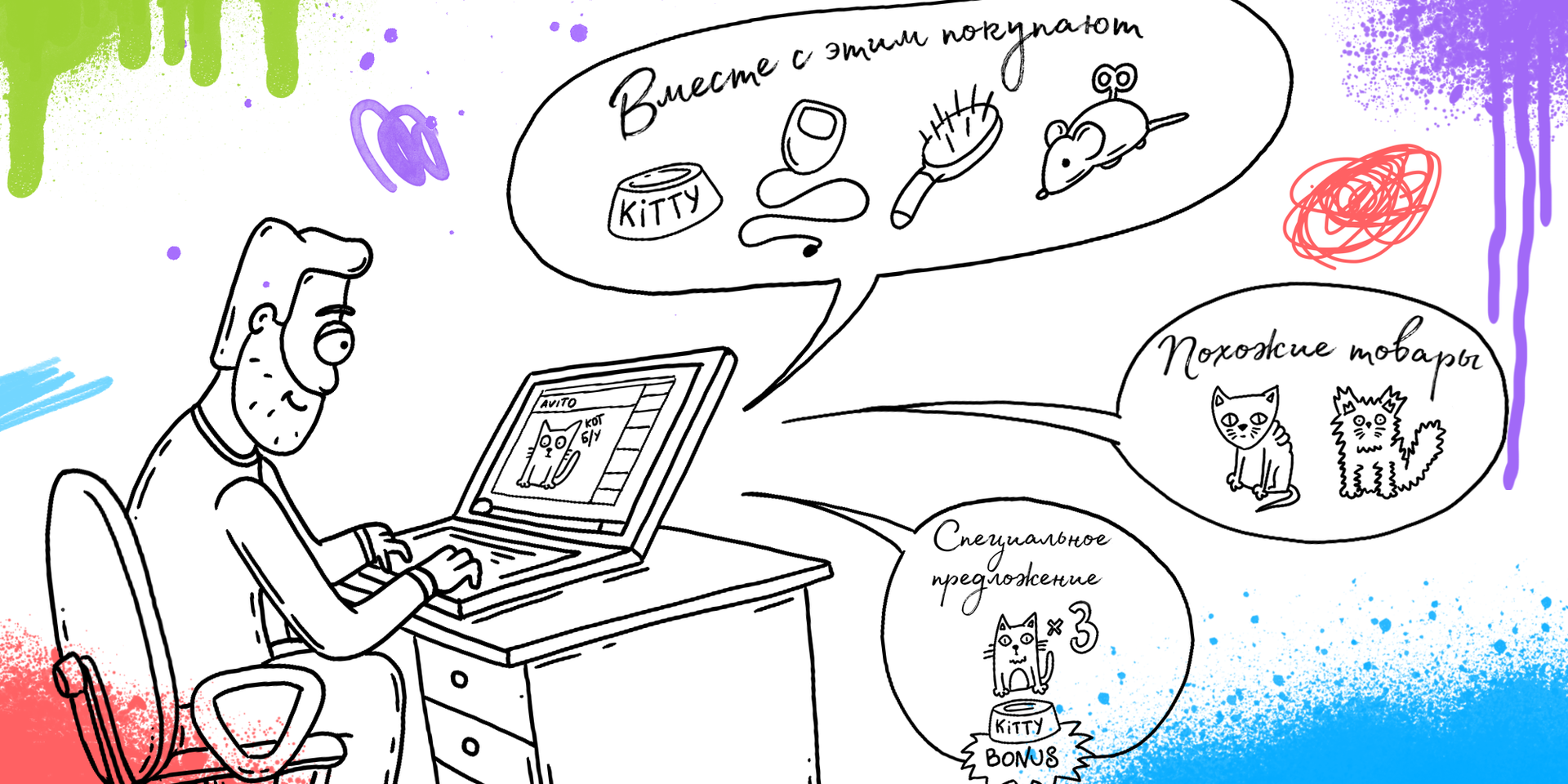
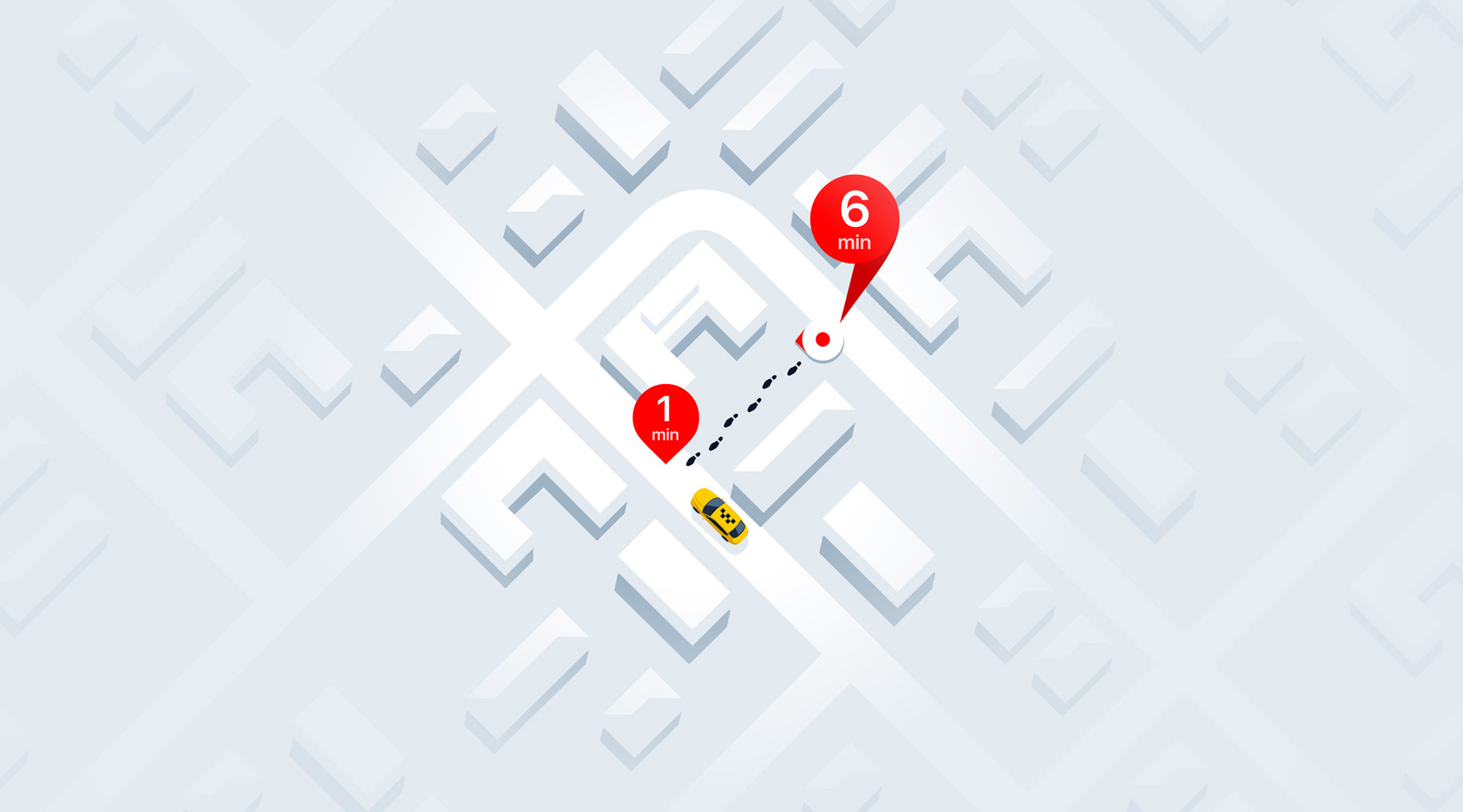
Несмотря на всеобщий хайп вокруг машинного обучения и нейронных сетей, несомненно, сейчас на них действительно стоит обратить особое внимание. Почему? Вот ключевые причины:
- Железо стало гораздо быстрее и можно легко обсчитывать модели на GPU
- Появилась куча неплохих бесплатных фреймворков для нейросетей
- Одурманенные предыдущим хайпом, компании стали собирать бигдату — теперь есть на чем тренироваться!
- Нейронки в некоторых областях приблизились к человеку, а в некоторых — уже превзошли в решении ряда задач (где тут лопаты продают, надо срочно бункер рыть)
Но управлять этим, по прежнему, сложно: много математики, высшей и беспощадной. И либо ты из физмата, либо сиди и решай 2-3 тысячи задачек в течении двух-трех лет, чтобы понимать, о чем идет речь. Разобраться по дороге на собеседование в электричке, полистав книжку «Программирование на PHP/JavaScript за 3 дня» — не получится, ну никак, и списать никто не даст (даже за ящик водки).
Вам не дадут «списать» модель нейросети даже за ящик водки. Часто именно на Ваших данных публично доступная модель работает внезапно плохо и придется разбираться в тервере и матане
Но зато, ууУУ, овладев основами, можно строить разные предсказательные модели, реализующие интересные и мощные алгоритмы. И вот тут язык начинает заворачиваться и выпадать изо рта, цепляя левый глаз…









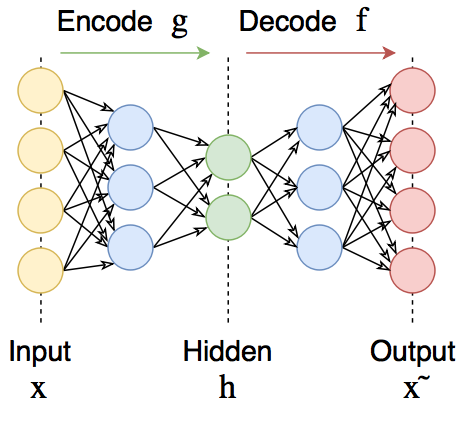




 Всем привет! Это уже одиннадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже одиннадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.