

Перевод поста Стивен Вольфрам (Stephen Wolfram) "Today We Launch Version 11!".
Выражаю огромную благодарность Полине Сологуб за помощь в переводе и подготовке публикации
Содержание
— Первое, что вы отметите...
— 3D печать
— Машинное обучение и нейронные сети
— Аудио
— Встроенные данные о чем угодно: от скелетной структуры и продуктов питания до сведений о нашей Вселенной
— Вычисления с реальными объектами
— Передовые возможности географических вычислений и визуализаций
— Не забудем про сложные задачи математического анализа и теоретической физики...
— Образование
— Совмещение всех функций в одно целое
— Визуализация
— От строк к тексту
— Современный подход к программированию систем
— Работа в интернете
— Облачные данные
— Подключайтесь к любым внешним сервисам: Facebook, Twitter, Instagram, ArXiv, Reddit и многим другим...
— WolframScript
— Новое в ядре языка Wolfram Language
— И еще много нового...
Я рад объявить о выходе новой версии системы Mathematica и 11-й версии языка Wolfram Language, доступной как для Desktop-компьютеров, так и в облачном виде. В течение последних двух лет сотни человек упорно трудились над ее созданием, а несколько тысяч часов и я лично. Я очень взволнован; это важный шаг вперед, имеющий важное значение для многих крупнейших технологических областей.


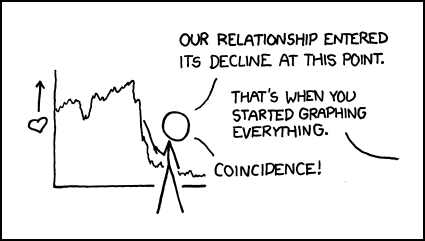
 Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому.
Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому.

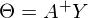 , где
, где 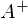 — псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
— псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).


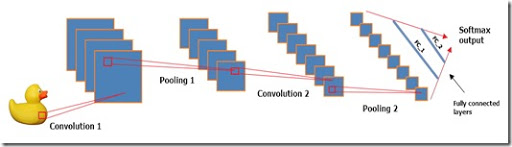
 Каждый должен делать свою работу качественно и в срок. Допустим, вам нужно сделать веб-сервис классификации картинок на базе обученной нейронной сети с помощью библиотеки
Каждый должен делать свою работу качественно и в срок. Допустим, вам нужно сделать веб-сервис классификации картинок на базе обученной нейронной сети с помощью библиотеки 