Материалы NLP курса от DeepPavlov
4 мин
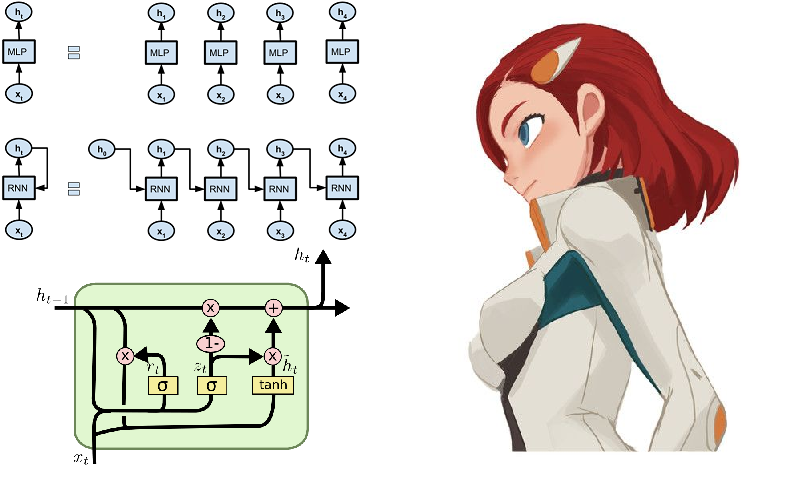
В этой статье вы найдете материалы очных курсов «Deep Learning in NLP», которые запускались командой DeepPavlov в 2018-2019 годах и которые являлись частичной адаптацией Stanford NLP course — cs224n. Статья будет полезна любым специалистам, погружающимися в обработку текста с помощью машинного обучения. Благодарю физтехов, разрабатывающих открытую библиотеку для разговорного искусственного интеллекта в МФТИ, и Moryshka за разрешение осветить эту тему на Хабре в нашем ods-блоге.