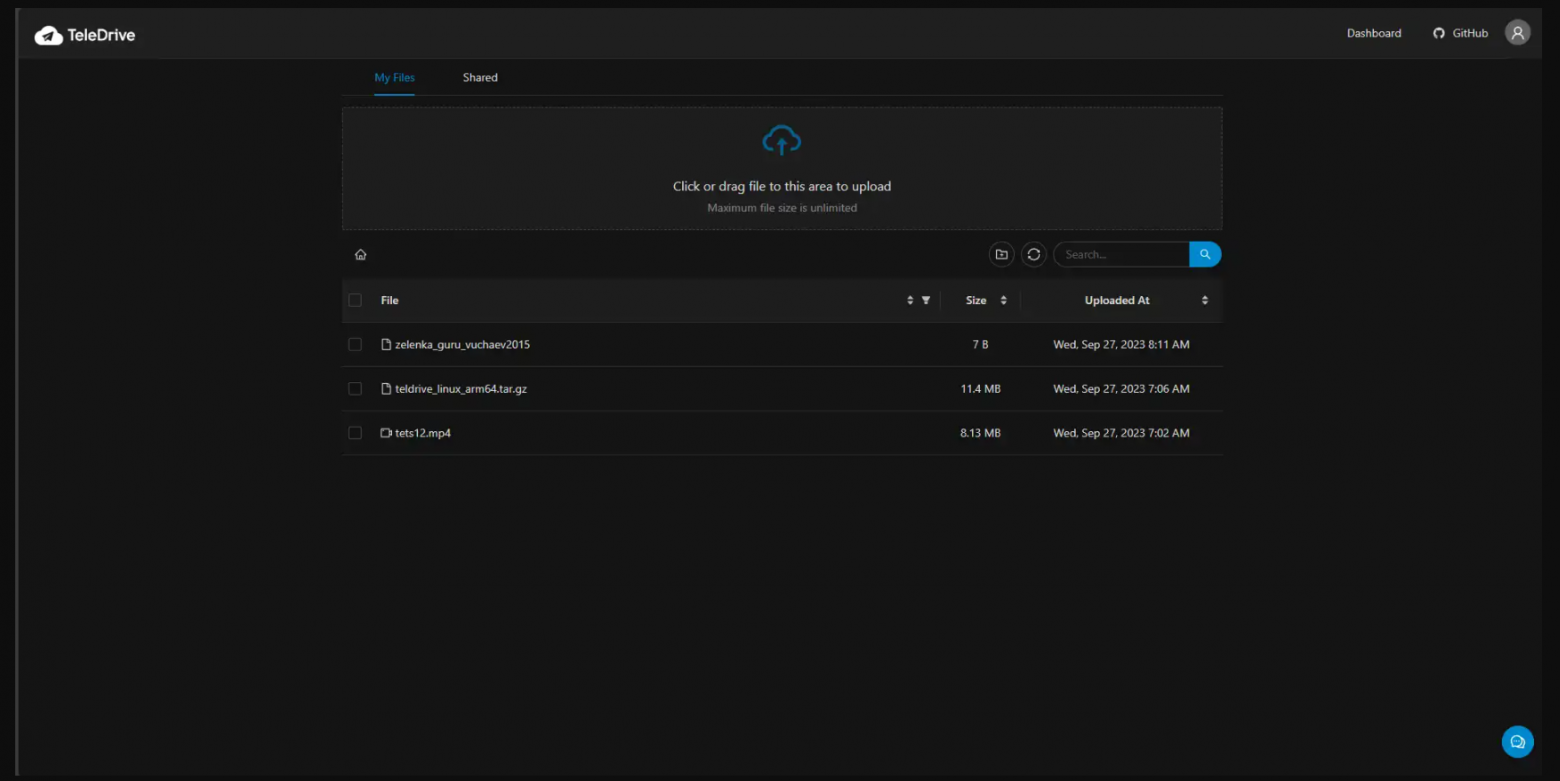
Hey everyone! Today, I'll guide you through creating a boundless cloud storage solution on Telegram using TeleDrive. This open-source project is a game-changer, offering functionalities like Google Drive/OneDrive via the Telegram API.
Hey everyone! Today, I'll guide you through creating a boundless cloud storage solution on Telegram using TeleDrive. This open-source project is a game-changer, offering functionalities like Google Drive/OneDrive via the Telegram API.
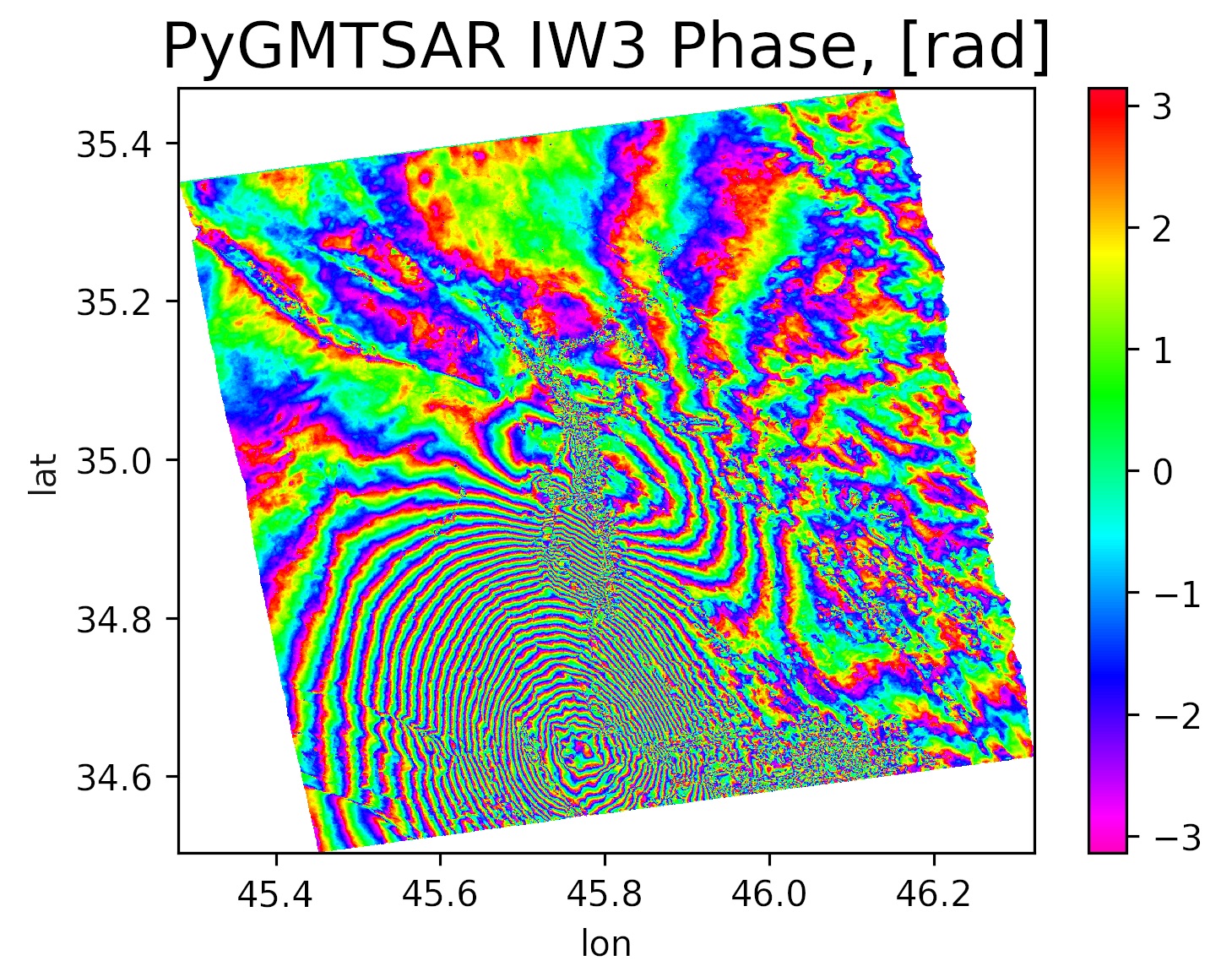
Do you need to produce satellite interferometry results for your work or study? Or should you find the way to process terabytes of radar data on your common laptop? Maybe you aren't confident about the installation and usage of the required software. Fortunately, there is the next generation of satellite interferometry products available for you. Beginners can build the results easily and advanced users might work on huge datasets. Open Source software PyGMTSAR is available on GitHub for developers and on DockerHub for advanced users and on Google Colab for everyone. This is the cloud-ready product, and it works the same as do you run it locally on your old laptop as on powerful cloud servers.