
Postgresso 35 — спецвыпуск: PostgreSQL 14

Пресс-релиз PostgreSQL обширен и основателен. Есть и выжимка (highlights), в которой после бурных обсуждений в рассылках выделили главное.
Статей о 14-й много. Мы смотрели и разрозненные статьи и целые сериалы:
обзоры коммитфестов Павла Лузанова (5 серий),
waiting for PostgreSQL 14 Хуберта 'depesz' Любашевского (18),
микрообзоры Postgres 14 highlights Мишеля Пакье (Michael Paquier) (5),
в блоге Fujitsu OSS (5).
Кроме того есть пространная статья-справочник от HPE: PostgreSQL 14 New Features With Examples (Beta 1).
Начнём со статей, в которых авторы стараются охватить версию 14 в целом. Но перед этим разомнёмся
в облаках и контейнерах
Храним данные в JSONB, как это влияет на скорость запросов?

Добрый день, меня зовут Павел Поляков, я Principal Engineer в каршеринг компании SHARE NOW, в Гамбурге в ?? Германии. А еще я автор Telegram-канала Хороший разработчик знает, где рассказываю обо всем, что должен знать хороший разработчик.
Сегодня хочу поговорить о том стоит ли хранить данные в JSONB полях в PostgreSQL. Как это влияет на производительность?
Рецепты PostgreSQL: загрузка Государственного Адресного Реестра
Для приготовления загрузки Государственного Адресного Реестра в PostgreSQL нам понадобится сам PostgreSQL, bash, sh, curl, wget, xml2csv, jq, или можно воспользоваться готовым образом.
ОСТОРОЖНО! Может потребоваться много дискового пространства! Терабайта должно хватить, может, даже пол-терабайта хватит.
Партицирование таблиц в PostgreSQL: чек-лист для старта

Часто возникает проблема: одна из таблиц в базе данных сильно выросла и время выполнения запросов к этой таблице увеличилось. Одним из вариантов решения подобной проблемы в PostgreSQL является партицирование. В статье затронем не только техническую реализацию, но и опишем этапы подготовки к партицированию.
Представим, что у нас есть батон хлеба. Порежем его на части. Каждый отрезанный кусочек — часть целого батона, но не сам батон. То есть мы поделили целое на части — это и есть партицирование. Батон как целое соответствует таблице, а кусочки батона как части — партициям этой таблицы.
Опыт миграции кластера PostgreSQL на базе Patroni

Недавно мне посчастливилось заниматься переносом кластера PostgreSQL под управлением Patroni на новое железо. Задача казалась простой — я и не думал, что могут возникнуть проблемы. Но в процессе реализации встретились некоторые сложности, которые натолкнули на мысль поделиться полученным опытом. В этой работе описываются практические шаги и нюансы, которые встретились во время переноса кластера на новую платформу. Использовались следующие версии ПО: PostgreSQL 11.13, Patroni 2.1.1, etcd 3.2.17 (API version 2). Итак, поехали!
PostgreSQL 15: Часть 2 или Коммитфест 2021-09
Список изменений в этом выпуске получился не очень длинным, но кое-что интересное всё-таки найдется:
- Как заставить очистку в «агрессивном» режиме работать менее агрессивно?
- Кто на самом деле владелец схемы PUBLIC?
- Cколько разделяемой памяти потребуется для запуска сервера? А количество огромных страниц?
SQL в SQLAlchemy

Меня зовут Алексей Казаков, я техлид команды «Клиентские коммуникации» в Домклик. По моему опыту подавляющее большинство приложений, взаимодействующих с базой данных, использовали для этого Object Relational Mapper. В этой статье я продолжу знакомить вас с популярными ORM, которые встречались мне в продовых проектах. На очереди всемогущий SQLAlchemy.
Как работает rollback в базах данных

Всем привет, меня зовут Артём и я алкоголик долгое время не понимал базы данных. Ну, то есть я понимал концепт и как с ними работать, но всегда воспринимал их как чёрный ящик с понятным интерфейсом, который может сохранять и отдавать данные, если знать, как его об этом попросить. Механизмы, позволяющие магии случаться, были совершенно не понятны. И честно говоря, меня это особо не волновало. Бизнесу нужно, чтобы ты фичи фигачил, а не вот это вот всё.
Однако недавно я понял, что хватит это терпеть и настало время разобраться что происходит под капотом, как это происходит и зачем. Статья подойдёт тем, кто каждый день работает с базами данных и не особо вникает в подробности, людям, кто как и я заинтересовался тем, как всё работает и не знает откуда начать копать или просто тем, кто хочет немного освежить своё понимание баз данных.
Распространённые ошибки изменения схемы базы данных PostgreSQL (Николай Самохвалов)

Postgres.ai делает возможным работу с полноразмерными базами данных в CI, значительно улучшая качество разработки и тестирования.
Разрабатываемый компанией открытый инструмент, Database Lab Engine, позволяет создавать полноразмерные клоны баз данных любого размера за секунды. Используя такие клоны, вы можете тестировать изменения, оптимизировать SQL-запросы и быстро развёртывать независимые тестовые стенды.
Вебсайт компании – https://Postgres.ai/ – содержит также SaaS-версию Database Lab.
Запросы в PostgreSQL: 7. Сортировка и слияние
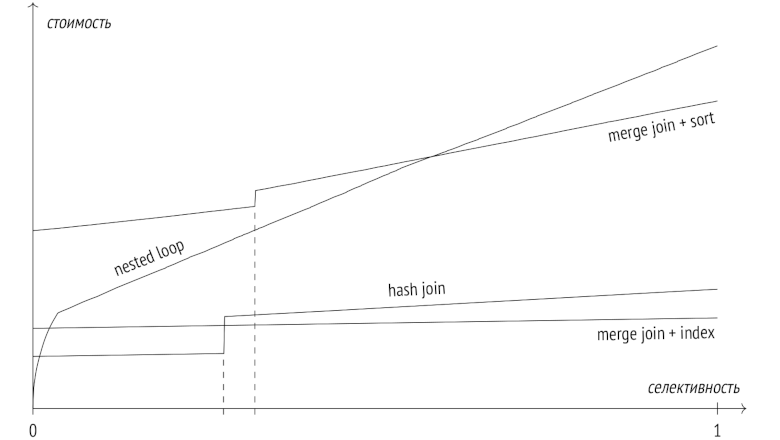
В предыдущих статьях я писал про этапы выполнения запросов, про статистику, про два основных вида доступа к данным — последовательное сканирование и индексное сканирование, — и успел рассказать о двух способах соединения — вложенном цикле и соединении хешированием.
В заключительной статье этой серии я расскажу про алгоритм слияния и про сортировку, и сравню все три алгоритма соединения между собой.
Популярные расширения для PostgreSQL: как установить и для чего использовать

Облачные базы данных Selectel поддерживают 40 расширений для PostgreSQL. Некоторые добавляют небольшие радости оптимизации баз данных, другие — заменяют отдельные модули разработки на стороне приложения. На данный момент расширениями пользуются 26% пользователей DBaaS. Мы узнали, какие экстеншены наиболее популярны у клиентов и где они их применяют.
Если вы опытный DBA, вы точно нужны в комментариях — расскажите, какие расширения используете и как они решают ваши задачи.
Что должен, но не знает про конкуренцию в PostgreSQL каждый разработчик?

Опыт показывает, что разработчики редко задумываются о проблемах, которые могут возникать при многопользовательском доступе к данным. При этом практически любое web-приложение является многопользовательским и так или иначе использует блокировки при доступе к данным в БД. При неправильном использовании эти блокировки могут больно бить по пользователям, а иногда и по системе в целом. Поэтому рано или поздно каждый разработчик многопользовательских систем должен задуматься о том, как ему начать работать с БД так, чтобы пользователи не мешали другу другу. Многие считают, что это сложно, давайте вместе убедимся, что это не так.
Ближайшие события
Запросы в PostgreSQL: 6. Хеширование
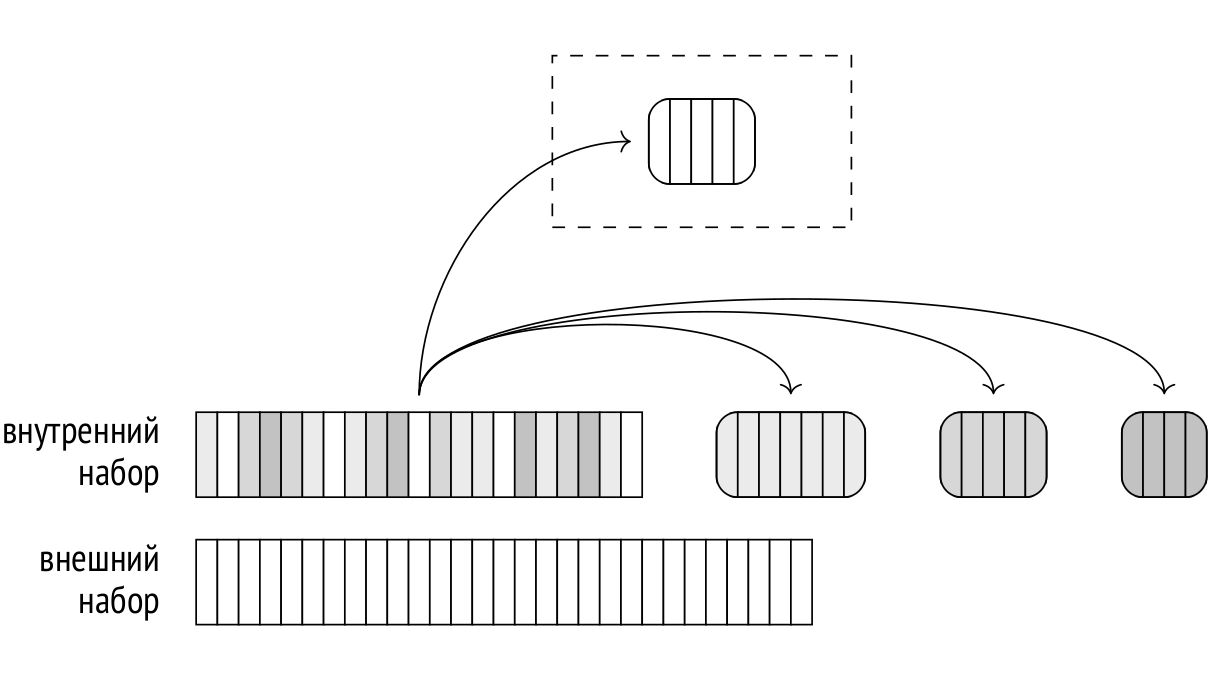
В предыдущих статьях я рассказал про этапы выполнения запросов, про статистику, про два основных вида доступа к данным — последовательное сканирование и индексное сканирование, — и перешел к способам соединения.
Прошлая статья была посвящена вложенному циклу, а сегодня поговорим про соединение хешированием. Заодно затронем группировку и поиск уникальных значений.
Причины спекуляций в строительной отрасли. Монополии корпораций над данными. Войны лоббистов и развитие BIM. Часть 6
Причиной отсутствия роста производительности и распространения спекуляций в строительной отрасли является качество данных, которыми оперируют участники процессов строительства. В чем основная проблема данных в строительстве? В первую очередь, в отсутствии доверия и прозрачности в системах 3D-7D, что ведёт к появлению рисков, связанных с человеческим фактором, и созданию многоуровневой бюрократии в основных бизнес-процессах строительных компаний.
Сегодня при обмене данными между различными 3D-7D системами мы доверяем хранение наших данных корпорациям. Для поддержания своего влияния на строительную отрасль корпорации, которым невыгодна прозрачность и интероперабельность данных, монополизировали хранение и обработку данных. Вследствие этого поставщики основных CAD и ERP решений постоянно повышают цены за пользование своими продуктами, а простые пользователи вынуждены платить “комиссию” на каждом этапе передачи данных в системах 3D-7D: за подключение, импорт, экспорт и работу с данными, которые пользователи сами создали.
Postgresso 34

В ожидании PostgreSQL 15
PostgreSQL 15: Часть 1 или Коммитфест 2021-07
Думаю, вы следите за обзорами Павла Лузанова о новостях коммитфестов. Если нет, то задумайтесь, не стоит ли. Павел, между прочим, не перечисляет буквально все патчи, а отбирает значимые, обычно с SQL-примерами.
Название скромничает: в обзоре также и о PostgreSQL 14 — принятые доработки. Но больше о 15-й. Часто Павел даёт коротенький код, демонстрирующий изменения — в духе «вот так запрос работал в 14-й, а в 15-й уже вот так». Иногда заныривает и глубже в историю — в 13-ю, если это оправдано контекстом, как при анализе pg_dump и схема public, например.
Напоминаем, что самое интересное о 14 версии можно прочитать и в предыдущих статьях: 2020-07, 2020-09, 2020-11, 2021-01 и 2021-03.
Запросы в PostgreSQL: 5. Вложенный цикл
Я уже рассказал об этапах выполнения запросов и о статистике, и о двух основных видах доступа к данным: о последовательном сканировании и об индексном сканировании.
Настал черед способов соединения. В этой статье я кратко напомню, какие бывают логические типы соединений, и расскажу о первом из трех физических способов соединения — о вложенном цикле. Заодно посмотрим и на новую для 14-й версии мемоизацию строк.
Архитект Проггер и кабинет приемной комиссии

Этим летом абитуриентам было жарко, МГУ по проходному баллу почти превратился в ПТУ, а кто-то успешно поступил в вооруженные силы РФ, сам того не желая. Отсутствие автоматизации в 2021 году, способной обработать распределение абитуриентов по учебным заведениям, а так же необходимость написать продолжение предыдущей статьи, описывающей основы теории о Распределенной Авторизации (РА) побудило решить эту детскую задачу автоматизации. Посмотрим, сколько же рпс нам в этом раз отсыпет антилопа.
Запускаем PostgreSQL в Docker: от простого к сложному

О простых и продвинутых способах запуска PostgreSQL в Docker: добавляем healthcheck, ставим на мониторинг, настраиваем параметры.
Запросы в PostgreSQL: 4. Индексное сканирование
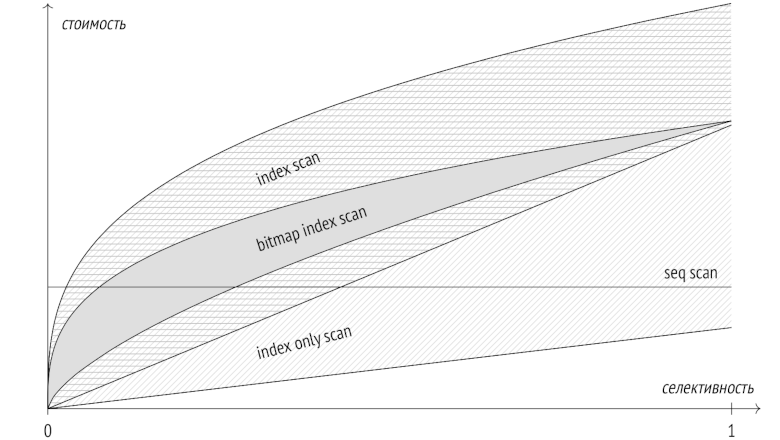
Я уже рассказал об этапах выполнения запросов и о статистике и перешел к способам доступа к данным. В прошлый раз темой статьи было последовательное сканирование, а сегодня поговорим о сканировании индексном.
Прежде чем погружаться в детали индексного доступа, надо было бы рассказать про интерфейс индексных методов. Но я это уже делал в статье про индексы, и, хотя та серия несколько устарела, повторяться не буду. Если слова «класс операторов» и «свойства методов доступа» не находят отклика в душе, статью лучше перечитать.