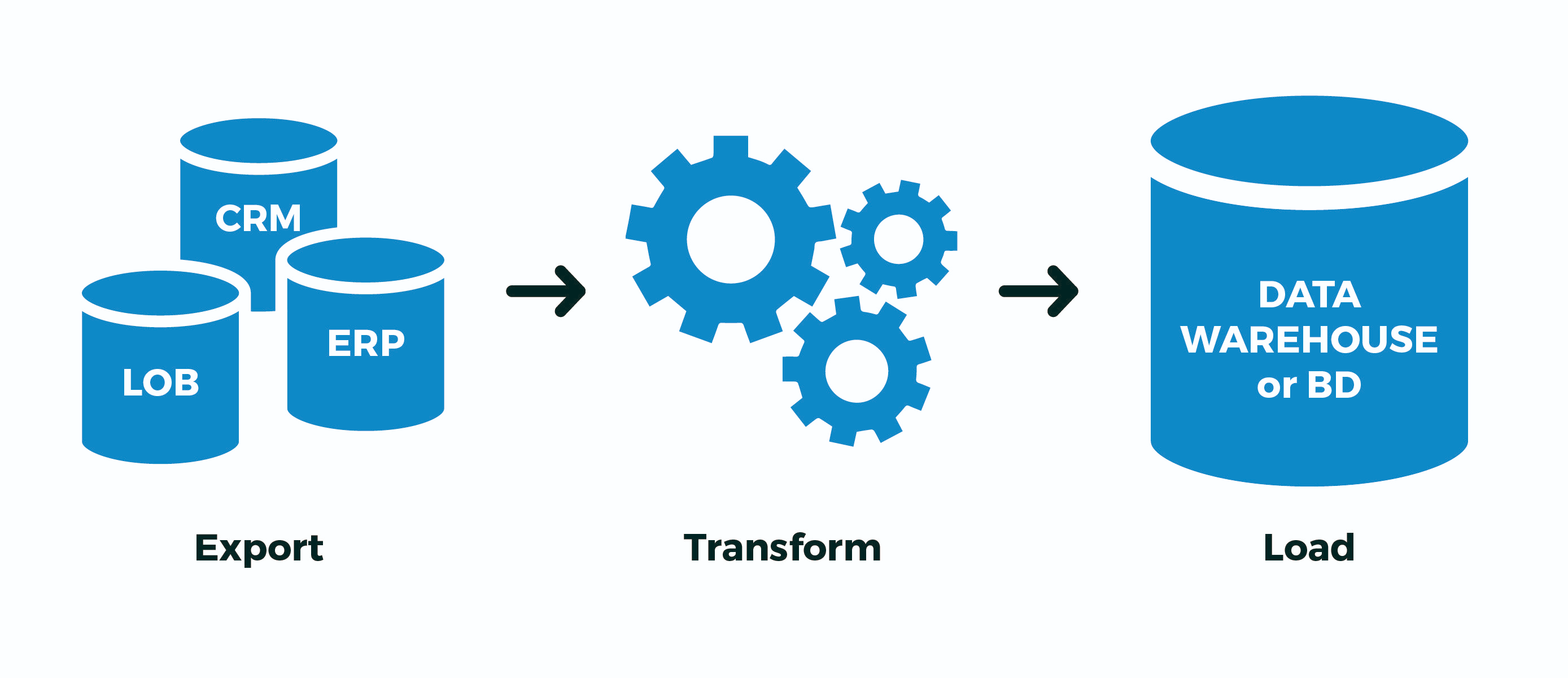
Жизнь продолжается. Продолжаем знакомить вас с самыми интересными новостями PostgreSQL.
Жизнь продолжается. Продолжаем знакомить вас с самыми интересными новостями PostgreSQL.
Релизы
Postgres Pro Enterprise 11.17.1 и Postgres Pro Standard 11.17.1
В
Postgres Pro Enterprise 11.17.1 исправлены недостатки, на которые указали пользователи. Серьезные доработки сделаны в расширении multimaster:
— теперь рекомендуется использовать его в конфигурации с тремя узлами, один из которых голосующий. Подробнее
здесь;
— устранена проблема раздувания WAL путём очистки точек синхронизации удалённого узла и исправления расчёта минимального требующегося LSN. Ранее раздувание WAL иногда случалось при удалении узла из кластера;
— устранена проблема с возвращением узла в кластер после длительного отключения этого узла;
исправлена ошибка в точке синхронизации при инициализации модуля multimaster, возникавшая в случае сбоя до первой синхронизации.
Кроме этого усовершенствован механизм встроенного пула соединений. По сравнению с предыдущей версией, в нём появились следующие новшества:
— параметр dedicated_users, позволяющий задать список пользователей, для которых в режиме пула соединений будут использоваться выделенные обслуживающие процессы;
— отдельные обслуживающие процессы теперь могут принимать подключения разных пользователей, так что все подключения к одной базе данных будут относиться к одному общему пулу.
Есть доработки, общие для Postgres Pro Enterprise 11.17.1 и Postgres Pro Standard 11.17.1. Например, утилита pg_probackup обновлена до версии 2.2.7, а mamonsu — до версии 2.4.4.
Об этих и других новшествах релиза есть в главке Замечания к выпуску из
документации по PPE и
PPS.
Postgres Pro Standard 12.2.1
Отличия этой версии от PostgreSQL 12 и от Postgres Pro Standard 11.17.1 можно проследить по соответствующим
Замечаниям к выпуску.