
Периодически возникает желание положить в базу «неположимое» — например, засунуть очень длинную строку. Нет, записать ее в поле таблицы — для PostgreSQL проблем нет, но вот в индекс…
Проблема в том, что вся строка (ROW) индекса целиком должна полностью умещаться на одной странице данных (8KB), иначе вас ждет примерно такая ошибка:
Проблема в том, что вся строка (ROW) индекса целиком должна полностью умещаться на одной странице данных (8KB), иначе вас ждет примерно такая ошибка:
ERROR: index row size… exceeds maximum… for index ...То есть даже в простейшем случае индекса из единственной строки — можно наступить на грабли. Как с ними бороться?
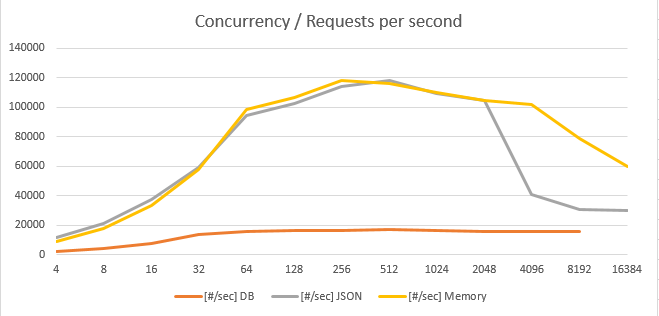
 Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.
Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.









{kind=link}