Апгрейд базы PostgreSQL через репликацию
Доброго времени суток. Решил поделиться опытом апгрейда через репликацию. Порыскав немного нашел написанного не мало на просторах Хабра, теории и практики, но в моем случае есть небольшое отличие ну и плюс актуальные версии, в общем думаю лишним не будет, а если кому-то даже частично будет полезно то вообще блеск. Итак приступим …
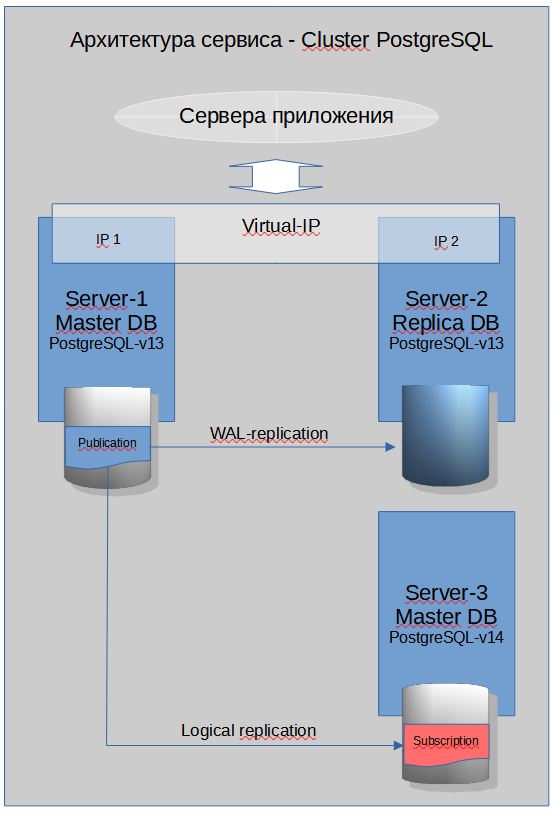
Недолго рассмотрев сложившуюся ситуацию предложил ребятам метод апгрейда через репликацию, для них никаких сложностей лишь один раз перезапустить приложение с изменением имени базы в коннекторе. Это позволит за раз сделать все что необходимо с учетом всех условий. Объяснил что разработчикам нужно наверно даже больше уделить внимание тестированию того что может выстрелить в новой версии самого 14 PosgreSQL - возможно изменение синтаксиса SQL, или свежий баг на лини сопряжения «база - ОС», или особенность драйвера, в общем нужно протестировать работу всего функционала и ухо держать востро, ну а я сделаю все максимально гладко со своей стороны.
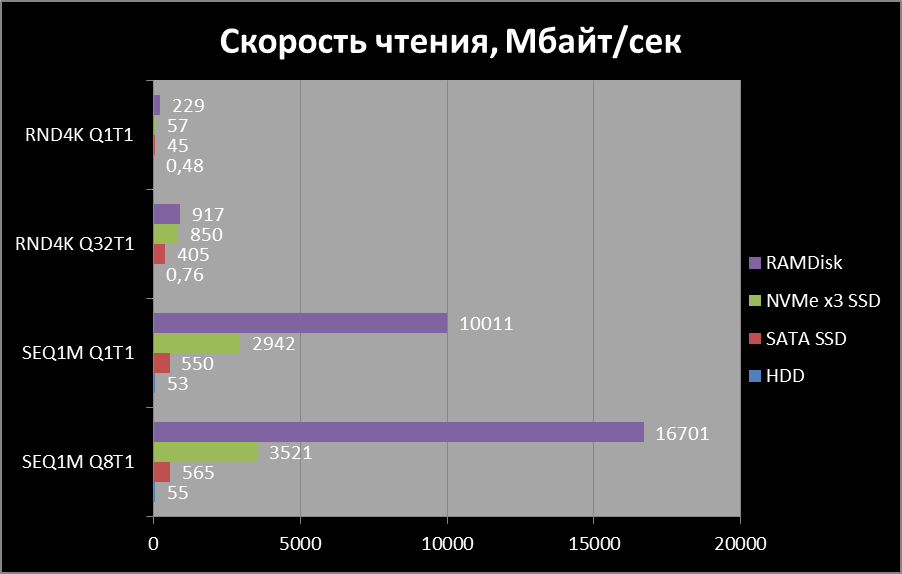
Соответственно на тесте постарался процедуру обкатать и проиграть в различных вариантах и ситуациях. Да и конечно было ограничение - на сервере не было дискового пространства на 8 баз суммарно, разве что на 3 хватило. Короче есть ограничение по месту. Да и сразу скажу, что в моей базе партиций не было, поэтому стоит это учесть и внести изменения в скрипты, если требуется !
Задача у команды стояла такая - нужно разделить одну базу на 8 отдельных баз по внутреннему индикатору- ID проекта (в процессе работы проект разделился на признаку и все жило в пределах одной базы). Так же у меня была своя задача апгрейда с 13 на 14 версию PostgreSQL. Была просьба от команды сделать это с минимальный простоем и совсем хорошо если за один присест, а не разбивая частями по 2-3 базы за итерацию.