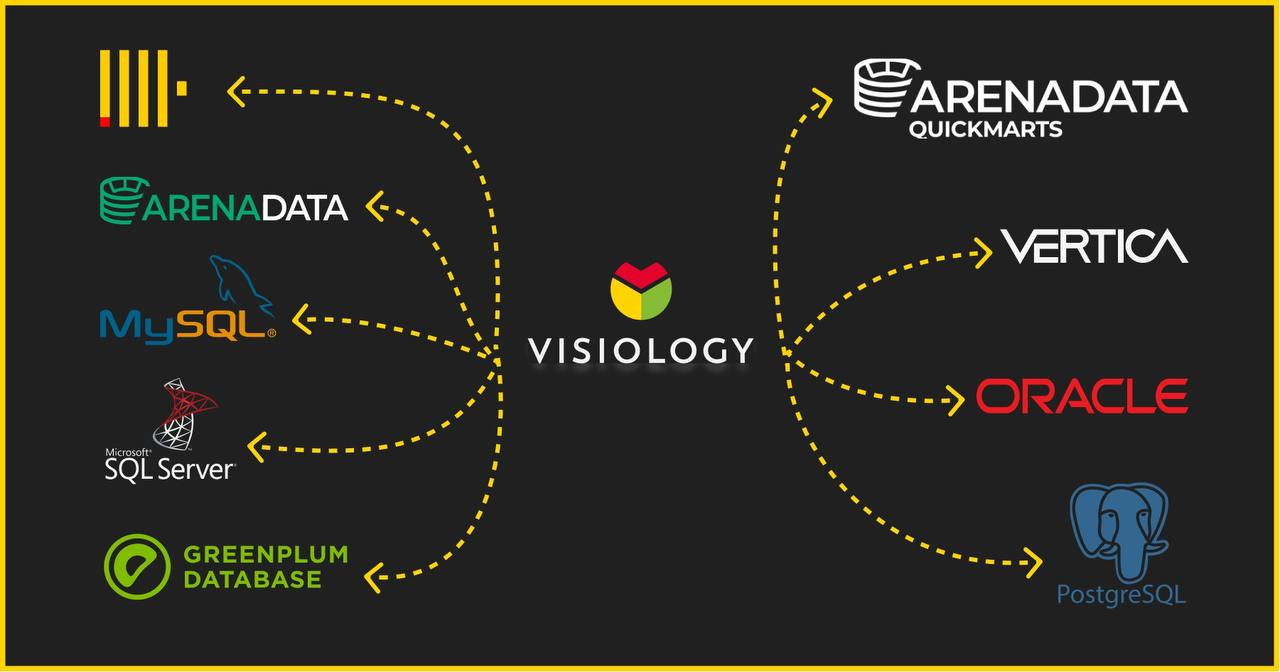
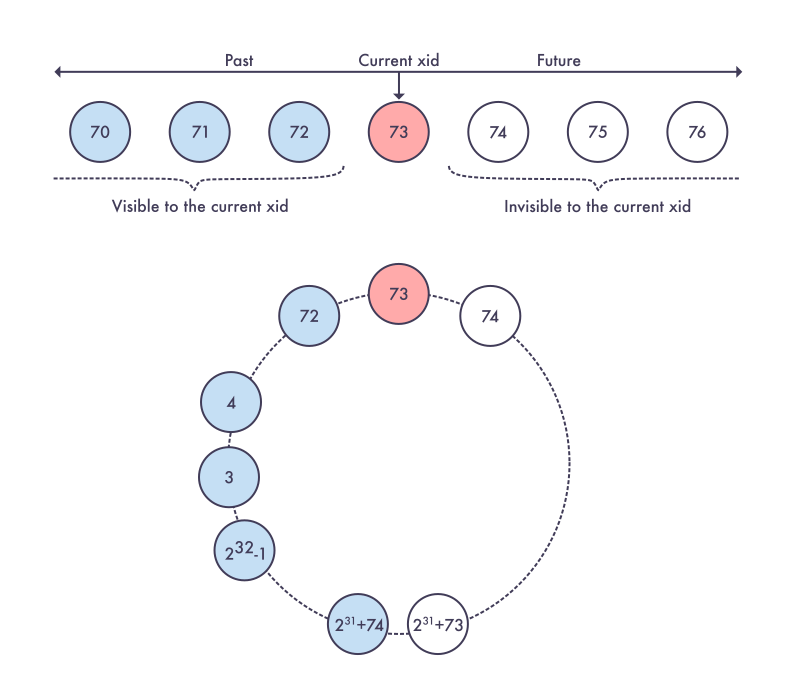
Эта статья описывает реализацию 64–битных счётчиков транзакций (XID, ксидов) в СУБД Postgres Pro Enterprise, которая создана на основе свободной, опенсорсной объектно–реляционной СУБД Postgres. Она ориентирована на тех, кто имеет практический опыт в работе с СУБД Postgres Pro Enterprise, но будет интересна и тем, кто интересуется развитием СУБД Postgres, так как описывает сравнение этих двух систем. Статья также описывает устройство таблиц на диске и организацию формата хранения данных отношений.
Postrges старается быть максимально гибким в конфигурации, чтобы удовлетворить запросы как можно большего числа своих пользователей. Большинство параметров, например, таких, как: размер страницы BLCKSZ (по умолчанию 8 кБ), размер сегмента SEGSIZE (по умолчанию 1 Гб), могут быть изменены при сборке Postgres.
Хотелось бы сразу обозначить, что мы будем рассматривать 64–битный вариант сборки Postrges, в котором все параметры имеют значение по умолчанию. Также мы не будем углубляться в мультитранзакции. Для целей этой статьи будет достаточным предположения, что они в данном контексте аналогичны "обычным" транзакциям.
Мы выложили наш вариант реализации в сообщество, а также занимаемся активным продвижением его в сообществе разработчиков Postgres. Он не на 100% идентичен коду, используемому в Postgres Pro Enterprise (в частности, там ксиды всё ещё образуют кольцо), но общая идея такая же, как изложена в статье. На текущий момент патч ожидает ревью. Мы верим, что этот патч положительно скажется на удобстве использования и устойчивости Postgres, надеемся, что он будет принят сообществом в ближайшем будущем. Тем не менее по этому вопросу предстоит ещё много работы. Поэтому мы будем благодарны всем желающим и небезразличным за посильное участие в его развитии.