 Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL. Между этим выпуском и #8 прошло больше времени, чем обычно, поэтому он будет более объемным.
Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL. Между этим выпуском и #8 прошло больше времени, чем обычно, поэтому он будет более объемным.
Релизы
PostgreSQL 11 Beta 3
Этот релиз отличается исправленными багами — и общими для серии релизов, о которых дальше, и специфическими для версии 11. Подробности об исправленных (и не только) багах можно узнать
здесь. Общая информация о beta
здесь.
PostgreSQL 10.5
Исправлены серьезные баги. Например, обнаружена и исправлена проблема в libpq: она не восстанавливала в начальное состояние все переменные состояния соединения при попытке повторного соединения. Не восстанавливалась переменная, которая задавала, нужен ли пароль, из-за чего, используя dblink или postgres_fdw, можно было получить незаконный доступ к серверам.
Всего в релизе около 20 исправлений и улучшений, касающихся самых разных механизмов СУБД: VACUUM, WAL, GIN-индексы, POSIX-семафоров и многого другого. В том числе для работы под Windows. Они расписаны
тут.
Вместе с 10.5 и Beta 3 вышли соответствующие обновления
9.6.10, 9.5.14, 9.4.19, 9.3.24. Скачать можно, как обычно,
отсюда.
Postgres Pro Standard 9.5.14.1, 9.6.10.1 и 10.5.1
Релизы
Postgres Pro Standard 9.5.14.1 и
10.5.1 созданы
Postgres Professional на базе соответствующих версий PostgreSQL (без последней цифры в номере релиза, напр PostgreSQL 10.5) и соответствующих предыдущих версий Postgres Pro Standard.

 Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.
Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.
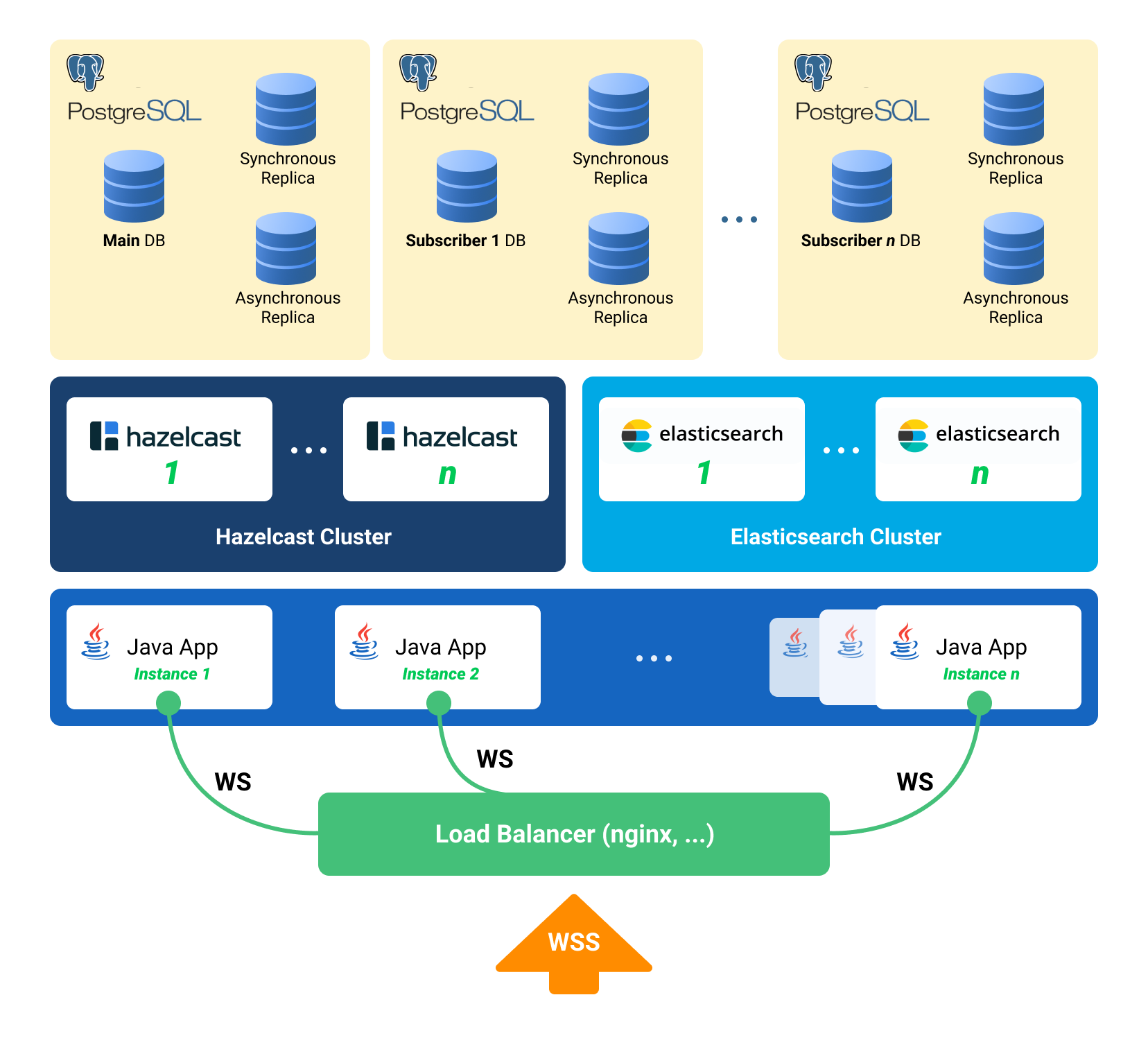
 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента. 



 Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL.
Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL.