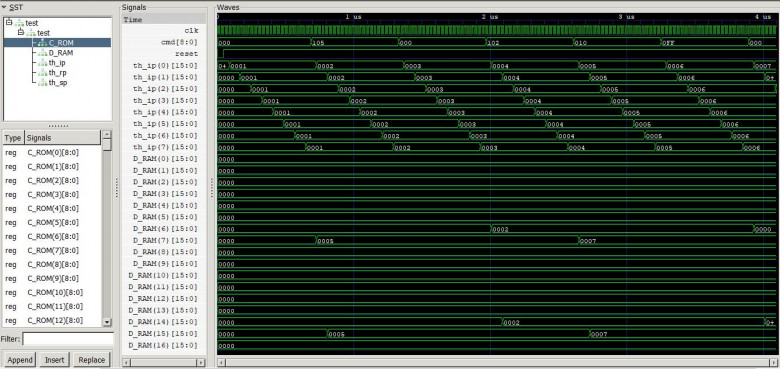
Выбираем логин на Яндекс.Почте

Много лет назад я зарегистрировал себе несколько трех- и четырехсимвольных адресов на Яндекс.Почте. Они оказались очень удобными, потому что их легко писать и диктовать, особенно вместе с доменом ya.ru.
Спустя время решил проверить, остались ли еще свободные короткие адреса и есть ли среди них какие-то поинтересней. Я предполагал, что сейчас уже ничего подобного не найти. Но когда начал вбивать разные варианты в форму на странице регистрации, то понял, что шансы пока есть. Не удовлетворившись парой выпавших логинов, решил комплексно изучить вопрос.
В статье вы найдете все, что вряд ли хотели знать, но теперь имеете отличную возможность узнать, о формате и количестве логинов Яндекса, а также датасет, с помощью которого сможете попробовать разобраться с «6-q» аномалией (у меня не получилось).