Зачем нужен __init__.py знает, наверное, любой питонист, но что насчёт __main__.py? Я видел немало проектов либо рабочих, либо на Github, которые не используют этот магический файл, хотя могли бы сделать свою жизнь проще. На мой взгляд, __main__.py это лучший способ для взаимодействия с питоновскими модулями, состоящими из нескольких файлов.
Но давайте сначала разберёмся: как большинство людей запускают свои скрипты на Python?
Однажды вы напишете программу, которую захотите использовать и как импортируемый модуль, и как инструмент запускаемый из командной строки. Вы скорей всего в курсе, как обычно поступают в этом случае:
if __name__ == '__main__':
main(sys.argv)
Когда вы скармливаете скрипт интерпретатору, магическая глобальная переменная __name__ получает значение __main__. Таким образом мы узнаём, что это не импорт, а именно запуск. Например:
python myapp.py
И это прекрасно работает для одиночного файла.
Проблема
Но если вы похожи на меня, вы не захотите, чтобы всё ваше приложение теснилось в единственном файле. Разбиение логики по разным файлам упрощает редактирование и поддержку. Например:
.
├── README.me
├── requirements.txt
├── setup.py
└── src
├── __init__.py
├── client.py
├── logic.py
├── models.py
└── run.py
Но пользователю, который склонировал проект из репозитория будет непонятно — какой из этих файлов главный? Неужели run.py? А может client.py? Где же искать знакомую строку if __name__ == '__main__'? Вот здесь-то __main__.py и способен проявить себя.




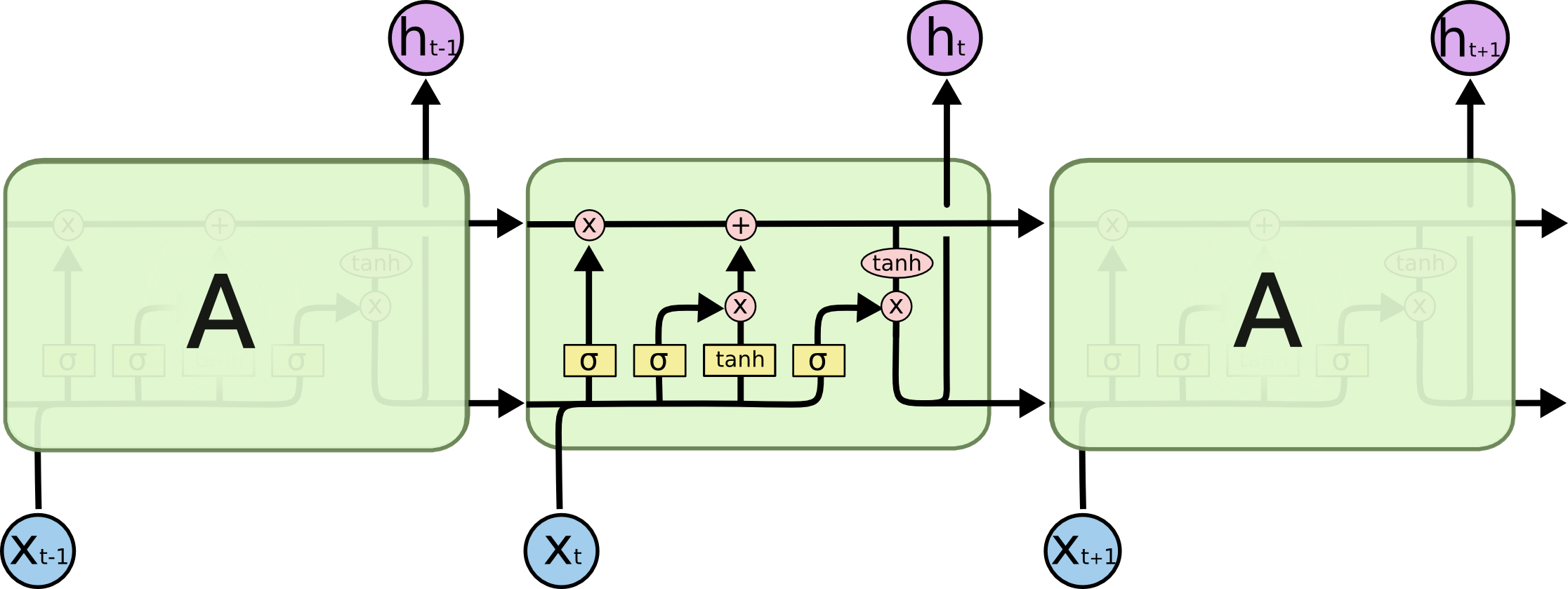
 Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией
Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией