Некоторое время назад передо мной была поставлена задача написать процедуру, которая выполняет прореживание котировок рынка Форекс (точнее, данных таймфреймов).
Формулировка задачи: данные поступают на вход с интервалом в 1 секунду в таком формате:
- Название инструмента (код пары USDEUR и пр.),
- Дата и время в формате unix time,
- Open value (цена первой сделки в интервале),
- High value (максимальная цена),
- Low value (минимальная цена),
- Close value (цена последней сделки),
- Volume (громкость, или объём сделки).
Необходимо обеспечить пересчёт и синхронизацию данных в таблицах: 5 сек, 15 сек, 1 мин, 5 мин, 15 мин, и т.д.
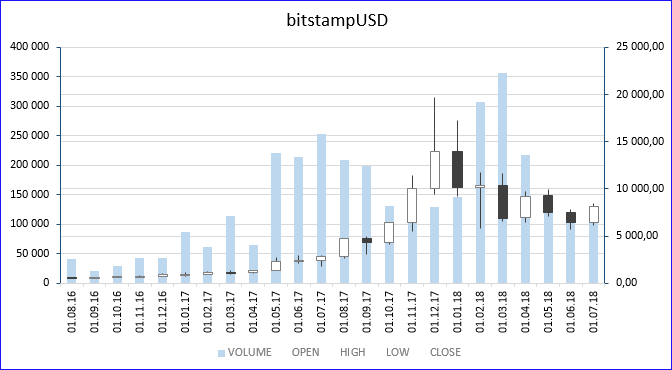
Описанный формат хранения данных имеет название OHLC, или OHLCV (Open, High, Low, Close, Volume). Он применяется часто, по нему сразу можно построить график «Японские свечи».
Под катом я описал все варианты, какие смог придумать, как можно прореживать (укрупнять) полученные данные, для анализа, например, зимнего скачка цены биткоина, а по полученным данным вы сразу построите график «Японские свечи» (в MS Excel такой график тоже есть). На картинке выше этот график построен для таймфрейма «1 месяц», для инструмента «bitstampUSD». Белое тело свечи означает рост цены в интервале, чёрное — снижение цены, верхний и нижние фитили означают максимальную и минимальную цены, которые достигались в интервале. Фон — объём сделок. Хорошо видно, что в декабре 2017 цена вплотную приблизилась к отметке 20К.
Решение будет приведено для двух движков БД, для Oracle и MS SQL, что, в некотором роде, даст возможность сравнить их на этой конкретной задаче (обобщать сравнение на другие задачи мы не будем).




 Это будет немного напыщенная речь, но меня действительно раздражает софт, в котором люди пытаются изобрести очередной собственный язык запросов. У нас уже есть триллион различных ORM, еще триллион баз данных с собственным языком запросов каждая, и еще триллион SaaS-продуктов, для доступа к которым нужно освоить какой-нибудь очередной DSL, которые они придумали.
Это будет немного напыщенная речь, но меня действительно раздражает софт, в котором люди пытаются изобрести очередной собственный язык запросов. У нас уже есть триллион различных ORM, еще триллион баз данных с собственным языком запросов каждая, и еще триллион SaaS-продуктов, для доступа к которым нужно освоить какой-нибудь очередной DSL, которые они придумали.




{kind=link}