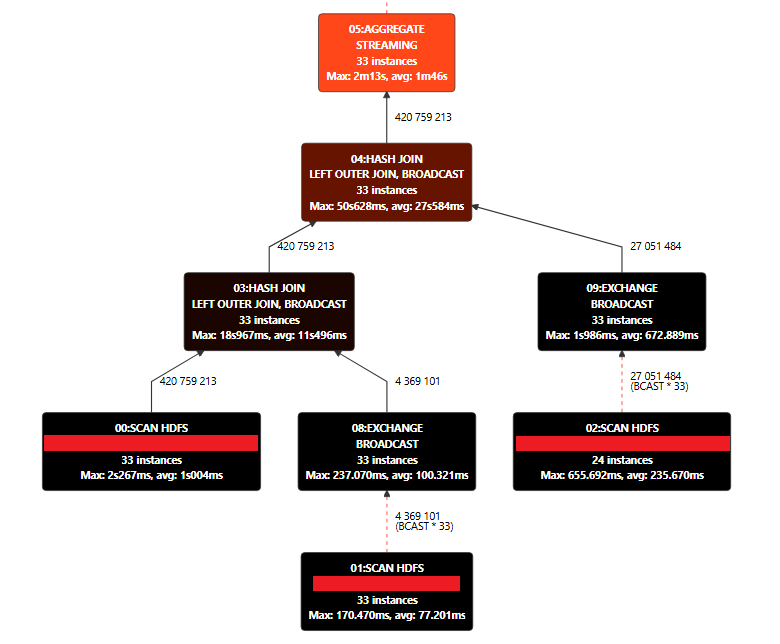
Привет, Хабр! DAX является мощным аналитическим языком запросов и активно используется во множестве проектов. Кроме того, на текущем уровне развития AI он способен условно в режиме реального времени преобразовать DAX запросы в запросы одной из СУБД, например, PostgreSQL, но, конечно, с рядом ограничений на сложность DAX запроса, схему данных и т.д. В связи с этим может быть актуальным вопрос, реально ли использовать «AI DAX движок» в сочетании с выполнением SQL запросов, сгенерированных этим движком, в одной из СУБД, т.е. выполнить DAX без Power BI на PostgreSQL источнике? Интересующимся возможностями DAX AI на примере PostgreSQL — добро пожаловать под кат :)