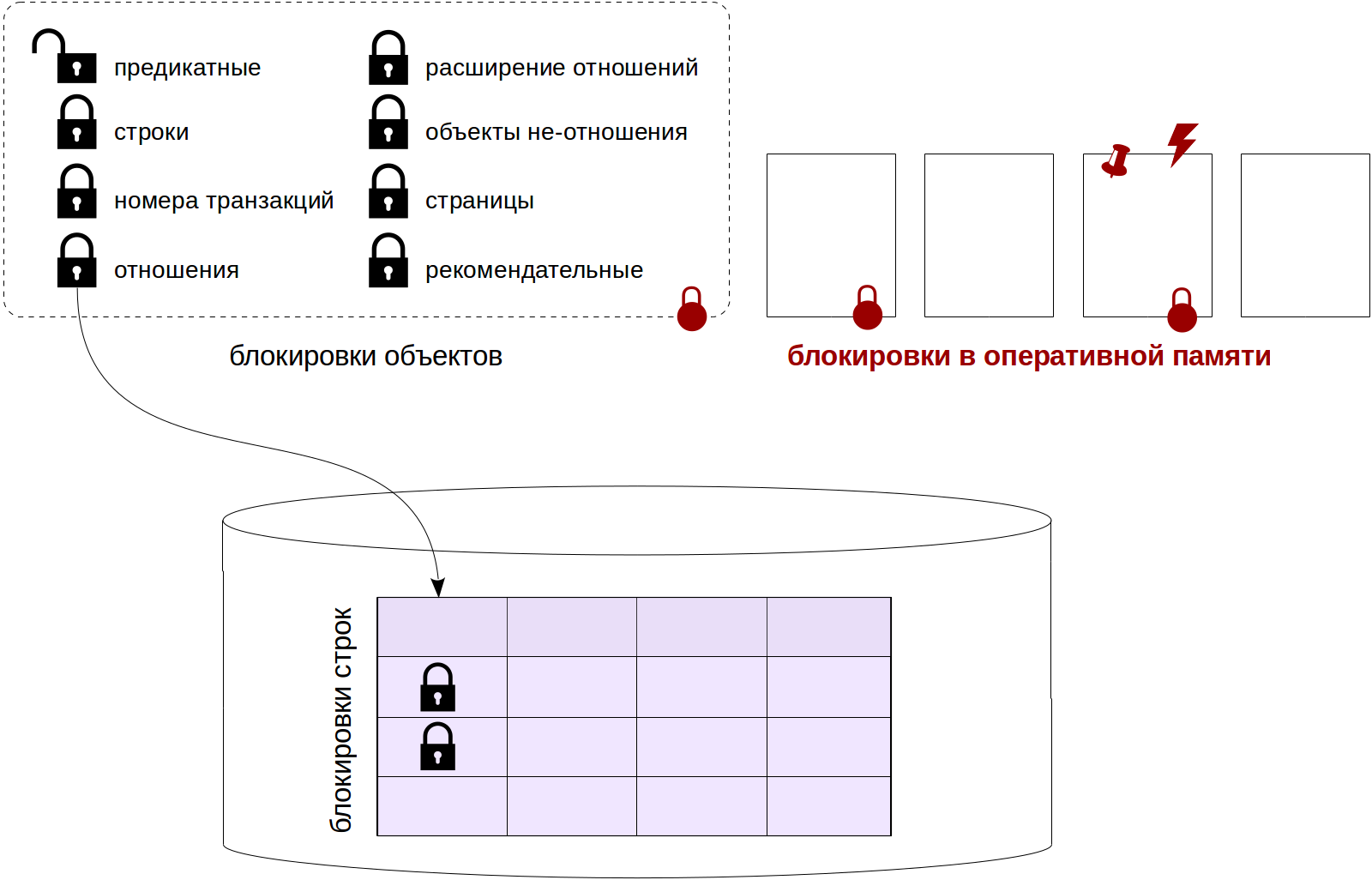
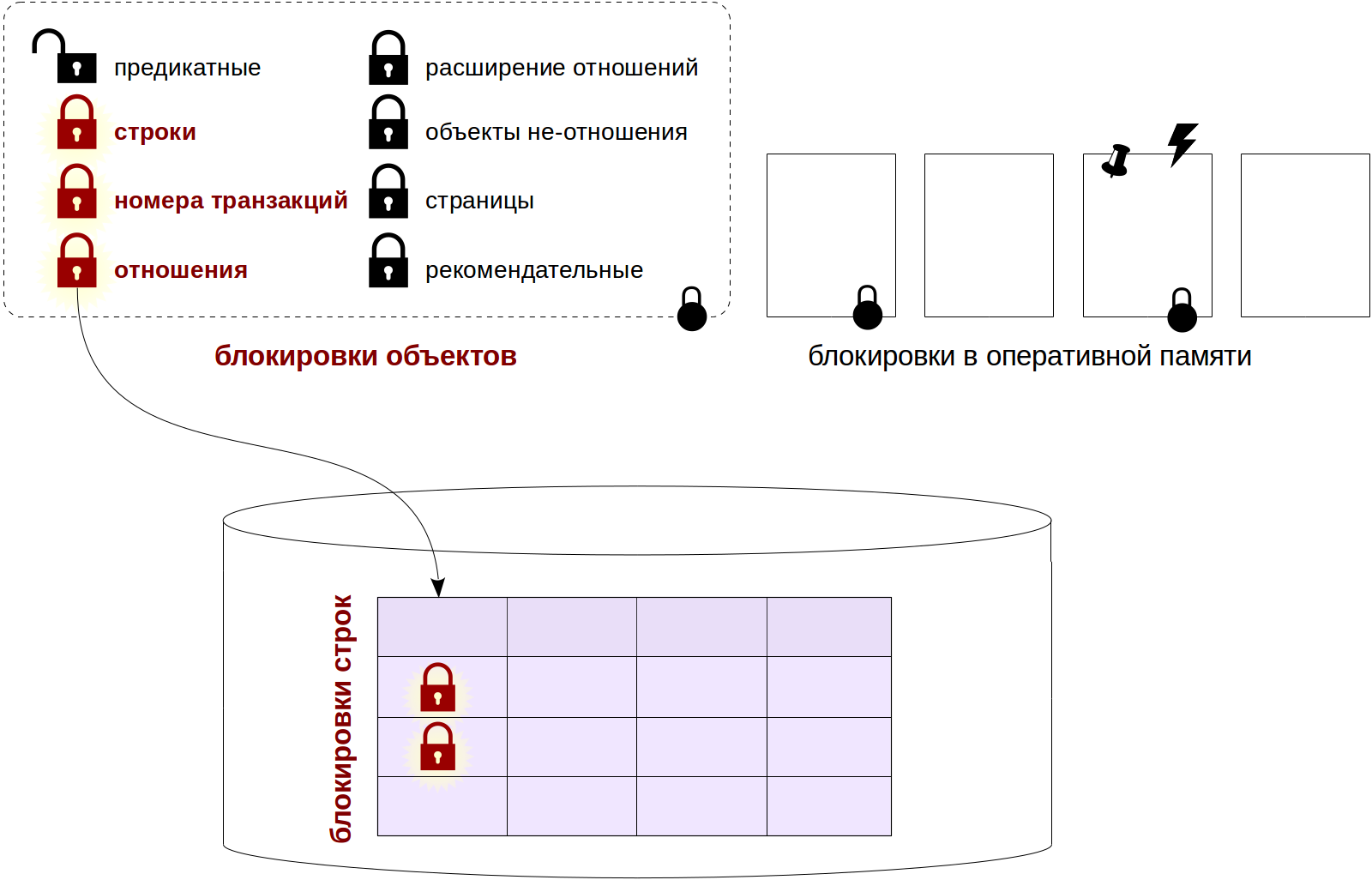
Разработка отказоустойчивых систем представляет собой важнейшую компетенцию для инженеров, занятых созданием распределённых и масштабируемых приложений. Под отказоустойчивостью понимается способность системы сохранять работоспособность в условиях сбоев отдельных компонентов или недоступности внешних сервисов. В данной статье рассматриваются практики обеспечения устойчивости на уровне программного кода, в частности в контексте серверных приложений, реализованных на языках Python и Java.
Особое внимание уделяется методам повышения надёжности при временных сбоях, включая: повторные попытки выполнения операций с экспоненциальной задержкой (exponential backoff), использование шаблона circuit breaker, механизмы плавной деградации функциональности (graceful degradation), задание таймаутов, реализация идемпотентности, ограничение одновременных вызовов (bulkhead isolation), а также внедрение систем мониторинга и алертинга. Приводимые примеры охватывают типовые сценарии — обращение к внешним API, взаимодействие с базами данных и выполнение фоновых задач.