
Разукрашиваем вывод mysql-client в консоли
4 мин
Цвет и звук — это те небольшие радости, которые могут разукрасить и облегчить будние администратора при постоянной работе с консолью. Вывод цветовой информации регулируется так называемым escape-последовательностями, определяющими среди прочего цвет текста и цвет фона.
Общий вид:
В интернете не раз был встречен вопрос о разукрашивании консоли mysql, но нигде не нашлось рецепта. Только общие слова «может быть состряпать обертку» или «посмотрите в исходном коде». Такой вопрос на StackOverflow жил без ответа более 2 лет! «Жил» было специально употреблено в прошедшем времени, потому что ответ нашелся.
Поможет нам утилита grc. Она доступна в большинстве дистрибутивов и о ней многие знают. Но как обернуть в нее вывод mysql-client?
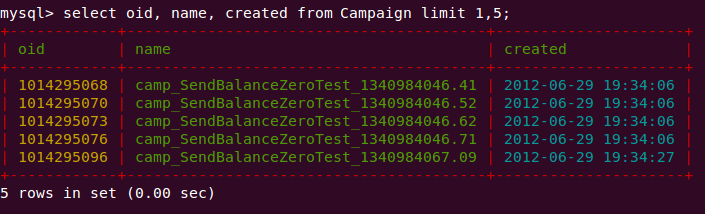
Общий вид:
\033[Xm, где X — это значение параметра (цифра). Например, echo -ne "\033[34mHELLO" выведет синим цветом «HELLO». Таблицу цветов и других доступных параметров (подчеркивание, мигание и т.п.) можно получить в документации man console_codes в разделе «ECMA-48 Set Graphics Rendition». Обычно поддержка цвета интегрирована в само приложение, но mysql-client не входит в число таких программ. В интернете не раз был встречен вопрос о разукрашивании консоли mysql, но нигде не нашлось рецепта. Только общие слова «может быть состряпать обертку» или «посмотрите в исходном коде». Такой вопрос на StackOverflow жил без ответа более 2 лет! «Жил» было специально употреблено в прошедшем времени, потому что ответ нашелся.
Поможет нам утилита grc. Она доступна в большинстве дистрибутивов и о ней многие знают. Но как обернуть в нее вывод mysql-client?

 Для определения страны по IP необходимы специальные базы данных, состоящие из диапазонов IP адресов и соответствующих им стран. Обычно такие базы данных распространяются в виде CSV или SQL файлов для использования в СУБД, либо бинарных файлов специального формата.
Для определения страны по IP необходимы специальные базы данных, состоящие из диапазонов IP адресов и соответствующих им стран. Обычно такие базы данных распространяются в виде CSV или SQL файлов для использования в СУБД, либо бинарных файлов специального формата.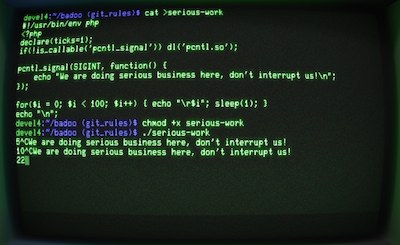 Для большинства специалистов PHP не является языком, который бы всерьёз использовался для написания консольных утилит, и для этого есть много причин. PHP изначально разрабатывался как язык для создания веб-сайтов, но, начиная с PHP 4.3, в 2002-ом году появилась
Для большинства специалистов PHP не является языком, который бы всерьёз использовался для написания консольных утилит, и для этого есть много причин. PHP изначально разрабатывался как язык для создания веб-сайтов, но, начиная с PHP 4.3, в 2002-ом году появилась 