Эта статья рассказывает о времени выполнения и о расходе памяти большинства алгоритмов используемых в информатике. В прошлом, когда я готовился к прохождению собеседования я потратил много времени исследуя интернет для поиска информации о лучшем, среднем и худшем случае работы алгоритмов поиска и сортировки, чтобы заданный вопрос на собеседовании не поставил меня в тупик. За последние несколько лет я проходил интервью в нескольких стартапах из Силиконовой долины, а также в некоторых крупных компаниях таких как Yahoo, eBay, LinkedIn и Google и каждый раз, когда я готовился к интервью, я подумал: «Почему никто не создал хорошую шпаргалку по асимптотической сложности алгоритмов? ». Чтобы сохранить ваше время я создал такую шпаргалку. Наслаждайтесь!

Пользователь
Самые популярные структуры данных
9 мин
Туториал
Что такое структура данных?
Проще говоря, структура данных — это контейнер, в котором хранятся данные в определенной компоновке (формате, или способе организации их в памяти). Эта «компоновка» позволяет структуре данных быть эффективной в одних операциях и неэффективной в других. Ваша цель — понять структуры данных, чтобы вы могли выбрать структуру данных, наиболее оптимальную для рассматриваемой проблемы.
Зачем нам нужны структуры данных?
Поскольку структуры данных используются для хранения данных в организованном виде, и поскольку данные являются наиболее важным элементом компьютерной науки, истинная ценность структур данных очевидна.
Независимо от того, какую проблему вы решаете, вам так или иначе приходится иметь дело с данными — будь то зарплата сотрудника, цены на акции, список покупок или даже простой телефонный справочник.
Исходя из разных сценариев, данные должны храниться в определенном формате. У нас есть несколько структур данных, которые покрывают потребность хранить данные в разных форматах.
Проще говоря, структура данных — это контейнер, в котором хранятся данные в определенной компоновке (формате, или способе организации их в памяти). Эта «компоновка» позволяет структуре данных быть эффективной в одних операциях и неэффективной в других. Ваша цель — понять структуры данных, чтобы вы могли выбрать структуру данных, наиболее оптимальную для рассматриваемой проблемы.
Зачем нам нужны структуры данных?
Поскольку структуры данных используются для хранения данных в организованном виде, и поскольку данные являются наиболее важным элементом компьютерной науки, истинная ценность структур данных очевидна.
Независимо от того, какую проблему вы решаете, вам так или иначе приходится иметь дело с данными — будь то зарплата сотрудника, цены на акции, список покупок или даже простой телефонный справочник.
Исходя из разных сценариев, данные должны храниться в определенном формате. У нас есть несколько структур данных, которые покрывают потребность хранить данные в разных форматах.
Шпаргалка по рекомендательным системам
Средний
7 мин

Рекомендательные системы стали неотъемлемой частью нашей жизни, помогая нам легко находить новые фильмы, музыку, книги, товары и многое другое. Цель этой шпаргалки - дать краткий обзор основных методов: коллаборативная фильтрация, матричная факторизация и некоторые нейросетевые методы.
Надеюсь, что эта шпаргалка станет полезным ресурсом для вас, помогая разобраться в мире рекомендательных систем и использовать их потенциал для улучшения пользовательского опыта.
Сравнение матричной факторизации с трансформерами на наборе данных MovieLens с применением библиотеки pytorch-acceleratd
45 мин
Перевод

Современный человек много чем занимается в интернете: ходит по магазинам, слушает музыку, читает новости. Все эти задачи подразумевают поиск и выбор того, что ему нужно. При этом важную роль тут играют рекомендательные системы. Они помогают людям не утонуть в многообразии вариантов и увидеть именно то, что им подойдёт, то, что иначе им сложно было бы найти. Предоставление пользователям качественных рекомендаций — это важнейшая часть обеспечения первоклассного уровня удовлетворения клиента. Это — один из самых эффективных способов взращивания лояльности клиентов и повышения ценности продукта или услуги в их глазах. Всё это так важно, что целые бизнес-модели некоторых компаний построены вокруг предоставления их клиентам наилучших рекомендаций, что делает рекомендательные системы важнейшими факторами, влияющими на прибыль подобных компаний! В результате неудивительно то, что клиенты проекта Microsoft CSE часто обращаются к нам с просьбами, касающимися реализации эталонных рекомендательных техник. Один из таких проектов был моим первым опытом в данной сфере.
Рекомендательная система SVD
Средний
4 мин

Про SVD разложение и PCA. Решение задачи восстановления user-item matrix с помощью stochastic gradient descent.
Рекомендательная система SVD: Funk MF (Matrix Factorization)
Средний
5 мин

Продолжение темы рекомендательных систем. Небольшая модификация алгоритма SVD. Как учитывать предубеждения пользователей относительно товаров и куда развиваться дальше.
Рекомендательная система для Directum Club. Часть первая, коллаборативная
8 мин
Каждый день пользователи по всему миру получают большое количество различных рассылок — только через сервис MailChimp ежедневно рассылают миллиард писем. Из них открывают 20.81%.
Ежемесячно пользователи наших сайтов получают рассылки с отобранными редактором материалами. Эти письма открывают около 21% читателей.
Для того, чтобы повысить это число можно сделать их персонализированными. Один из способов — добавить рекомендательную систему, которая будет подсказывать материалы, интересные конкретному читателю.
В этой статье расскажу о том, как реализовать рекомендательную систему с нуля на основе коллаборативной фильтрации.
Первая часть статьи содержит теоретическую основу для реализации рекомендательной системы. Для понимания материала достаточно школьной математики.
Во второй части описана реализация на Python для данных нашего сайта.
Дропаем ранжирующие метрики в рекомендательной системе, часть 3: платформа для экспериментов
Средний
11 мин
Кейс
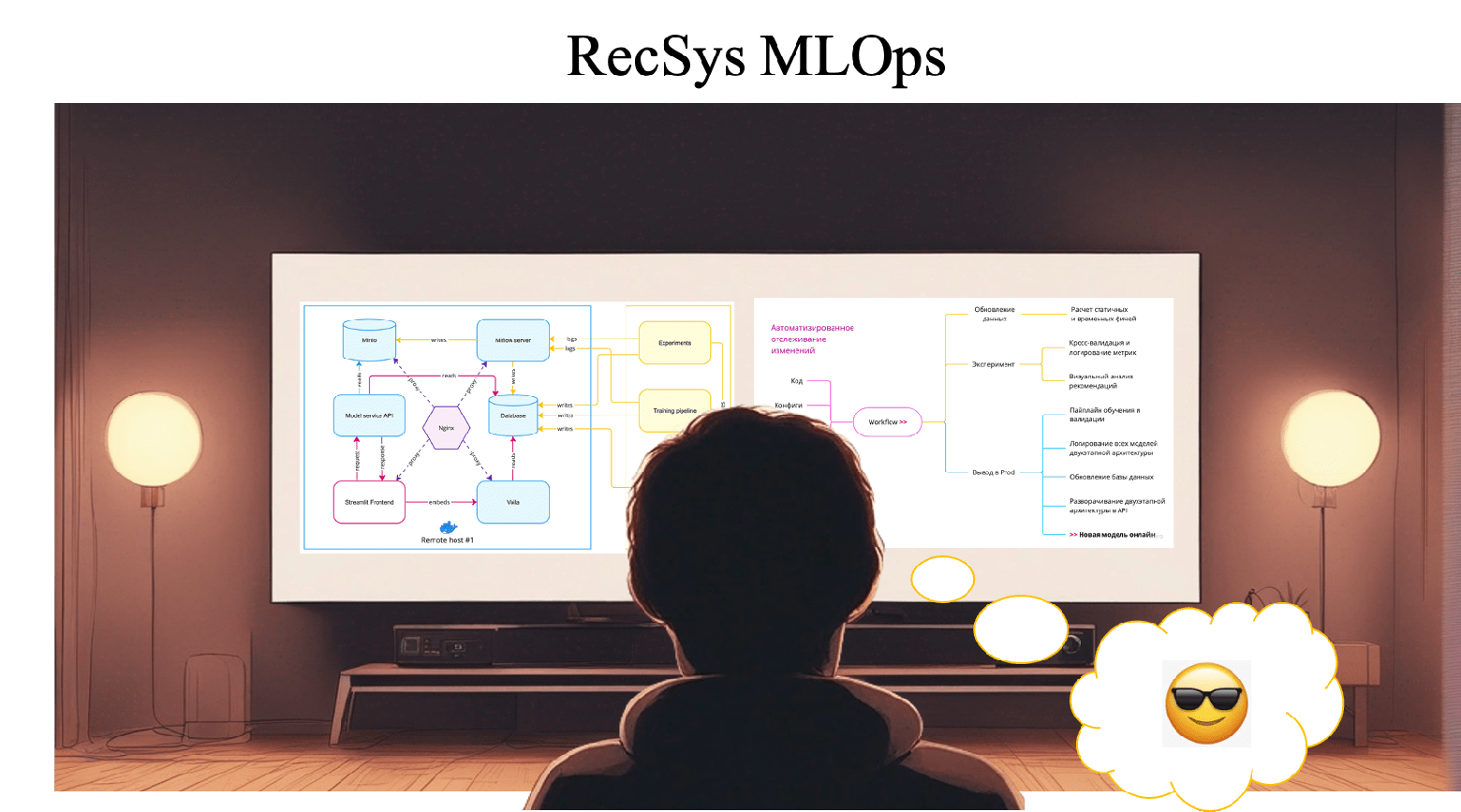
В прошлых частях статьи я описывала, как мы экспериментировали с рекомендательными моделями на датасете онлайн-кинотеатра Kion. Считали метрики, проводили визуальный анализ, диагностировали popularity bias и другие проблемы алгоритмов, строили двухэтапные модели.
Кроме онлайн приложения мы построили небольшую, но цельную платформу для экспериментов с рекомендательными моделями. Сегодня я подробно на ней остановлюсь:
- Расскажу о workflow экспериментов и пайплайнах обработки данных.
- О том, какие инструменты мы использовали для реализации платформы.
- Нарисую полную инфраструктуру проекта.
А также опишу, как мы построили эксперименты с кросс-валидацией скользящим окном для моделей, которые используют фичи, зависящие от времени. В том числе как мы сделали валидацию для двухэтапной модели с градиентным бустингом.
Будет много MLOps для RecSys.
Дропаем ранжирующие метрики в рекомендательной системе, часть 2: двухэтапные модели
Средний
9 мин
Кейс

В первой части статьи я рассказала, как мы с напарником решили выкатить модель из соревнования в онлайн рекомендации, увидели проблему popularity bias, и затем построили новую модель, сбалансированную по метрикам.
В этой части я опишу, как мы улучшали результат выдачи рекомендаций с помощью двухэтапной модели.
Дропаем ранжирующие метрики в рекомендательной системе, часть 1: визуальный анализ и popularity bias
Средний
12 мин
Кейс

Привет, Хабр! Поговорим о RecSys?
Что нужно для построения рекомендательной системы, которая будет полезна бизнесу? Топовые метрики, максимум предсказательной силы, machine learning на полную? Проверим. Сегодня покажу:
• Как (и почему) мы дропнули в 3 раза ранжирующие метрики в пет-проекте по рекомендациям фильмов
• Как искали свой идеальный алгоритм
• Как подобрали релевантные рекомендации на самые разные запросы
Будем говорить обо всех аспектах экспериментов в RecSys: метрики, визуальный анализ, workflow. А результат проверим в онлайн-приложении.