В преддверии онлайн конференции
PRO+НАВЫКИ мы попросили докладчиков конференции написать полезных статей по темам докладов. На прошлой неделе вышли:
А сегодня пришло время поговорить о целеполагании. Мы попросили нашего хорошего знакомого Филиппа Гузенюка, известнейшего бизнес-тренера и автора проекта «Счастье в деятельности» написать статью. И вот что из этого вышло:
7 способов «пропитки» целью: как ставить цели, чтобы их достигать (Филипп Гузенюк, партнер Института коучинга (СПб))
Что такое «пропитка целью»? Это процесс перевода цели из состояния «ну да, есть цель» или «классная идея!!» или «вот бы мне!!» в состояние «я знаю, это будет».
В результате пропитки целью она «становится частью меня», «падает из головы в тело», начинает ощущаться как «моя», мир начинает «вести меня к цели», приходят «нужные возможности» и возникает железная уверенность «не знаю как, но знаю ТОЧНО — это будет».
Психолог сказал бы, что цель переходит с сознательного уровня на подсознательный и превращается в фильтр нашего восприятия.
Каждый человек похож на кита. Как кит пропускает планктон через свои усы, так мы пропускаем мир через фильтры своих потребностей, ценностей, убеждений, целей и выбираем из него нужную информацию.
Пропитавшись целью, мы начинаем подсознательно, естественно и без всяких усилий «фильтровать» окружающий мир на наличие возможностей ее достижения. И нам кажется, что они приходят как бы сами собой.
Любые случайности превращаются в знаки, которые подсказывают что-то ценное о том, как достичь цели. «Нужные люди», которых мы бы спокойно не заметили до этого, начинают «появляться» и помогать нам и т.д…
Вы понимаете, о чем я.


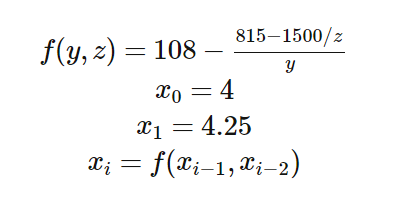

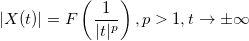 ,
,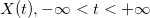 , удовлетворяет условию:
, удовлетворяет условию: 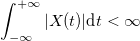
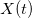 как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция
как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция 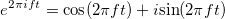 .
.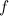 имеет вид:
имеет вид: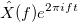 , где
, где 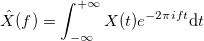 .
.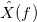 называется преобразованием Фурье.
называется преобразованием Фурье. Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения,
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, 


