Привет, Хабр! Мы продолжаем нашу традицию и снова выпускаем ежемесячный набор рецензий на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Напоминаем, что описания статей даются без изменений и именно в том виде, в котором авторы запостили их в канал #article_essence. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.

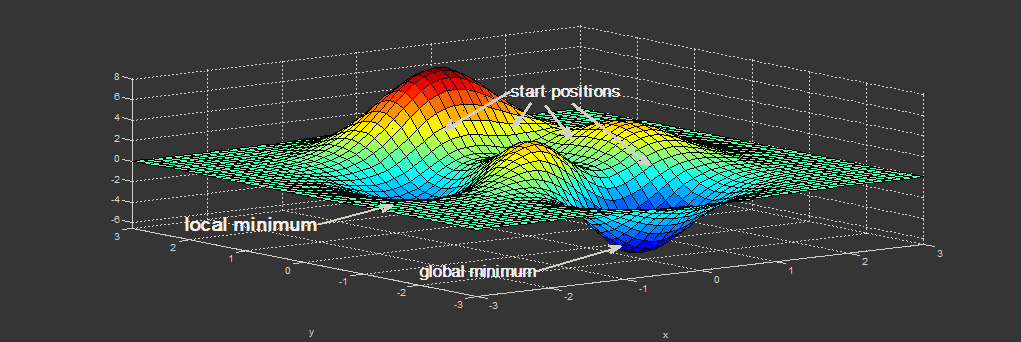
 Но дело серьёзно осложняется тем, что компьютеры так и научились ориентироваться в нашем мире. Всё, что они так хорошо делают, они делают по аналогии, не вдаваясь в суть и не нагружая себя смыслом происходящего. Может оно и к лучшему — дольше проживём, не будучи порабощены бездушным племенем машин.
Но дело серьёзно осложняется тем, что компьютеры так и научились ориентироваться в нашем мире. Всё, что они так хорошо делают, они делают по аналогии, не вдаваясь в суть и не нагружая себя смыслом происходящего. Может оно и к лучшему — дольше проживём, не будучи порабощены бездушным племенем машин.