Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем.
Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем. Технический уровень кандидата у нас оценивается за счет всего двух типов интервью: секции с кодом и секции дизайна компьютерных систем. Первый тип мы назначаем всем претендентам вне зависимости от их уровня, а вот у кандидатов, которые претендуют на должность старшего специалиста, нужно проверять не только способность писать эффективный и работоспособный код, но и способность разрабатывать сложные системы в целом.
Что такое дизайн информационных систем
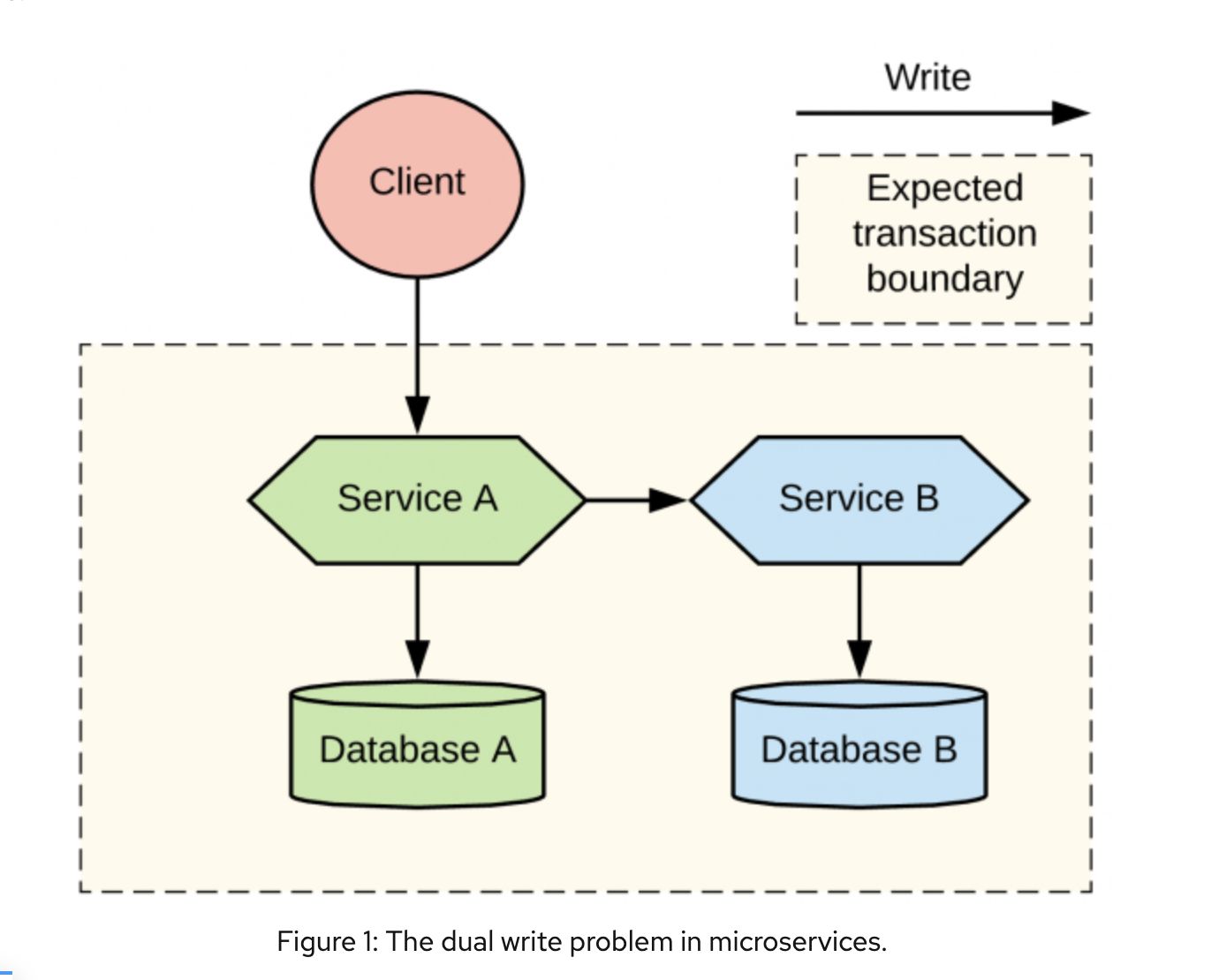
Основная цель любой IT-компании — производить сервисы, которые решают задачи пользователей. Мы должны уметь собирать элементы системы в единый механизм, который будет эффективно выполнять поставленную цель, и если первый тип собеседований нацелен в первую очередь на проверку необходимого минимума, то интервью про дизайн систем проверяет достаточность навыков кандидата в достижении конечной цели. Далекому от IT пользователю принципы и устройство систем могут казаться бесконечно сложными, но мы, их разработчики, должны иметь (не обязательно детальное) представление о принципах функционирования и роли каждого компонента.
Опытный читатель может сказать — в мире полно платных и бесплатных решений, из которых я могу собрать систему как из деталей конструктора, зачем мне понимать устройство этих деталей?