Мониторинг докер-хостов, контейнеров и контейнерных служб
7 мин
Туториал
Перевод
Я искал self-hosted мониторинговое решение с открытым кодом, которое может предоставить хранилище метрик, визуализацию и оповещение для физических серверов, виртуальных машин, контейнеров и сервисов, действующих внутри контейнеров. Опробовав Elastic Beats, Graphite и Prometheus, я остановился на Prometheus. В первую очередь меня привлекли поддержка многомерных метрик и несложный в овладении язык запросов. Возможность использования одного и того же языка для графических изображений и уведомления сильно упрощает задачу мониторинга. Prometheus осуществляет тестирование по методу как черного, так и белого ящика, это означает, что вы можете тестировать инфраструктуру, а также контролировать внутреннее состояние своих приложений.


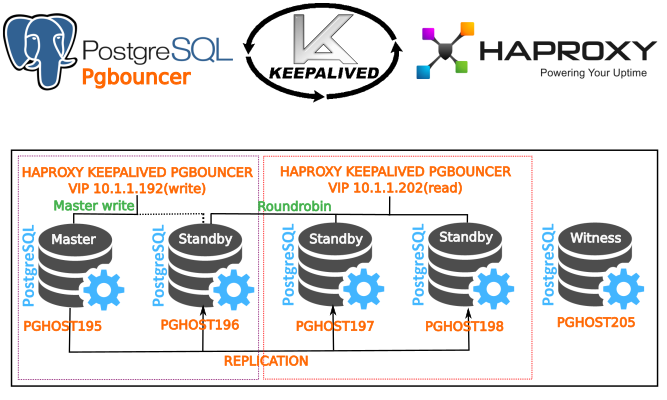









 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров. 

 Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.