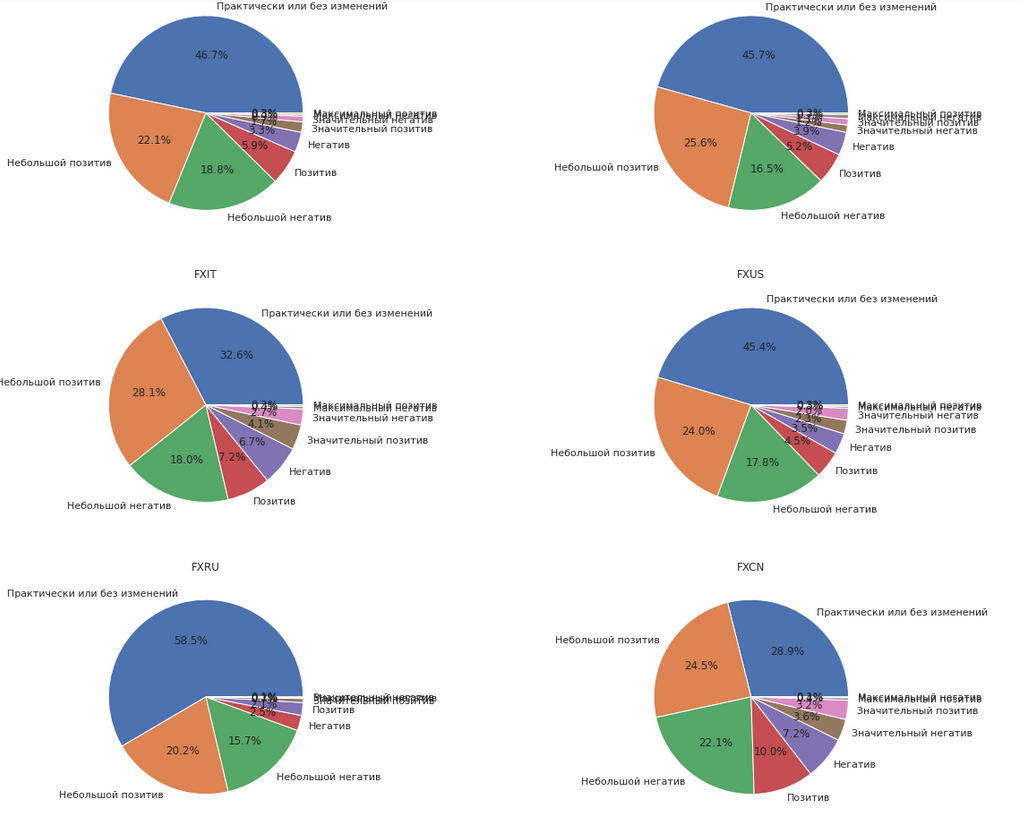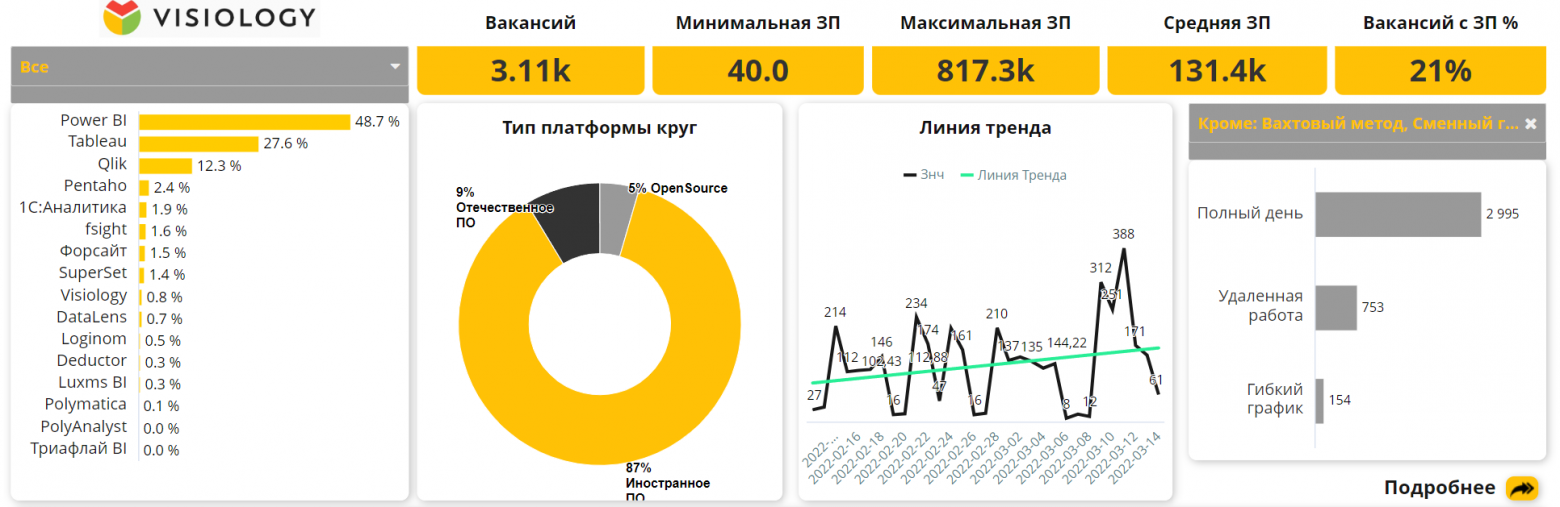
Привет, Хабр! Меня зовут Максим Губин, и я работаю в компании Visiology. Недавно к нам поступил интересный запрос, и мне с коллегами пришлось сделать демонстрационный дашборд для российского сообщества BI-специалистов. Интересно, что визуализация была сделана не под конкретного заказчика, но зато она позволила специалистам оценить, смогут ли они работать с другой BI-системой, если нужно будет сменить ПО.
Да, многие компании сегодня рассматривают альтернативные BI-системы, но специалисты продолжают сомневаться в удобстве и функциональности российских продуктов и open-source решений. В этом посте я расскажу о демонстрации возможностей отечественных платформ для сообщества российских BI-специалистов (Russian BI Chat), а также покажу, как выглядит интерактивный дашборд от Visiology. Этот пост будет интересен тем, кто рассматривает различные варианты внедрения BI-инструментов, включая российские и open-source системы.