13 сентября 2020 года в России прошёл единый день голосования. В некоторых регионах оппозицией была применена стратегия
«Умного Голосования», заключающаяся в том, что оппозиционно настроенные избиратели голосуют за единого кандидата, имеющего наивысшие шансы победить представителя от властей.
Процесс отбора кандидатов для «Умного Голосования» уже второй год вызывает дискуссии на тему своей прозрачности. Кроме того, лично меня смущают сложности с подведением итогов стратегии, с которыми могут столкнуться независимые аналитики. Организаторы
УмГ не публикуют подробные итоги стратегии, а лишь
диаграммы, демонстрирующие сколько оппозиционных кандидатов прошло в региональный парламент.
На
сайте «Умного Голосования» нельзя получить список поддержанных кандидатов, указав, например, город и округ. Если кто-то захочет собрать данные по региону, ему предстоит монотонная работа по подбору адресов для каждого округа.
Ни в коем случае не упрекаю разработчиков сайта УмГ, он имеет весь требуемый функционал для реализации стратегии голосования. Но в связи с тем, что в 2019 году никто не занимался сбором и публикацией подробных данных по итогам УмГ (вне московских выборов), на этих выборах я решил взять инициативу в свои руки.
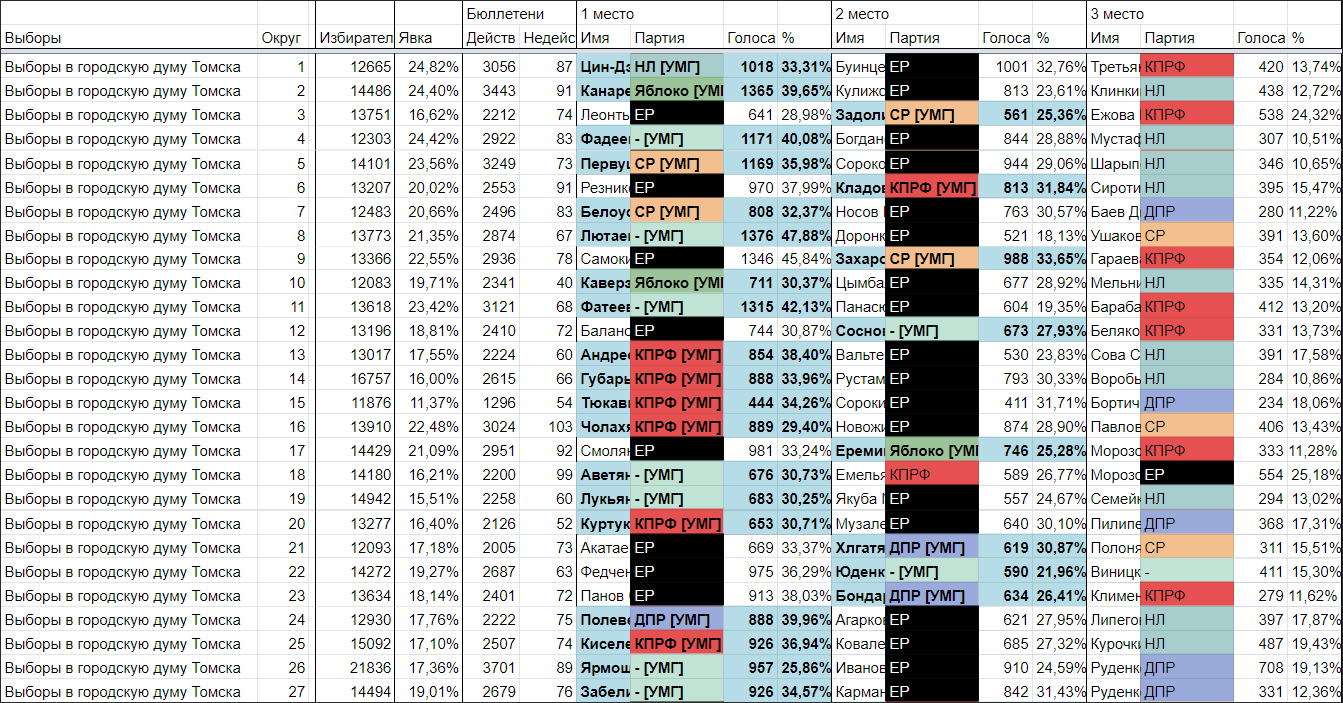
В итоге получилась вот такая
сводная таблица.
В данной статье я расскажу, как был получен приведённый
набор данных, как собиралась информация с сайтов Умного Голосования и нового веб-сервиса
ЦИК.