Вокруг постоянно говорят про Docker. Я знаю что вы отвечаете: «Это что-то про контейнеры, виртуализацию, облака», «У нас все и так работает», «Это все баловство», «Он не запустится на нашем старом ядре линукса», «Точно так же можно подготовить образ для облака и запустить его», «Можно просто настроить LXC, chroot или AppArmor». Вы знаете, что он вам не нужен. Очередная модная штука. В конце концов, просто лень разбираться. Но любопытно! Тогда, читайте. Это серия из шести заметок.
Если вы не слышали о контейнерах в Линуксе, вот список страниц, которые надо прочитать, чтобы понимать о чем речь:
Поставьте Docker, он небольшой. Для Windows и Mac можно просто поставить Toolbox:
www.docker.com/toolbox. Создавать виртуальную машину и настраивать лучше из командной строки, а не через графическую обертку. Прочитайте несколько уроков из мануала. Здесь я пишу о том, чего в документации нет.
Docker — это не виртуализация.
Вот какой у меня линукс:
Welcome to Ubuntu 15.04 (GNU/Linux 3.19.0-15-generic x86_64)
Last login: Tue Aug 18 00:43:50 2015 from 192.168.48.1
gri@ubuntu:~$ uname -a
Linux ubuntu 3.19.0-15-generic #15-Ubuntu SMP Thu Apr 16 23:32:37 UTC 2015 x86_64 x86_64 x86_64 GNU/ Linux
gri@ubuntu:~$ free -h
total used free shared buffers cached
Mem: 976M 866M 109M 11M 110M 514M
-/+ buffers/cache: 241M 735M
Swap: 1.0G 1.0M 1.0G
Запускаю CentOS:
gri@ubuntu:~$ docker run -ti centos
[root@301fc721eeb9 /]# uname -a
Linux 301fc721eeb9 3.19.0-15-generic #15-Ubuntu SMP Thu Apr 16 23:32:37 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
[root@301fc721eeb9 /]# cat /etc/redhat-release
CentOS Linux release 7.1.1503 (Core)
[root@301fc721eeb9 /]# free -h
total used free shared buff/cache available
Mem: 976M 85M 100M 12M 790M 677M
Swap: 1.0G 1.0M 1.0G
Docker — это не chroot, их функционал частично совпадает. Это не система безопасности вроде AppArmor. Docker использует те же контейнеры, что и LXC, но интересен он не контейнерами. Docker — это ничего из того, что я думал о нем до того, как прочитал документацию.
То же ядро, память, файловая система, а дистрибутивы, библиотеки и пользователи — разные.
Docker — это инструмент объекто-ориентированного проектирования
Регулярно возникает вопрос, является ли конфигурация nginx частью веб-приложения. Системные администраторы спорят с разработчиками. Но недавно в мире появились devops и захотели вместо последовательно-процедурного вызова команд из bash думать привычным OOP. Docker дает инкапсуляцию, наследование и полиморфизм компонентам системы, таким как база данных и данные. Это значит, что можно провести декомпозицию всей информационной системы, выделить приложение, web-сервер, базу данных, системные библиотеки, рабочие данные в независимые компоненты, внедрять зависимости из конфигов, и заставить все это работать одной группой, одинаково на разных компьютерах.
Такой подход можно использовать, чтобы снизить потери рабочего времени дорогих front-end разработчиков на настройку базы данных и Nginx. Чтобы уйти от vendor lock-in. Не обломаться когда openssl на сервере не поддерживает cipher, используемый в API госучреждения. Чтобы приложение работало независимо от версии PHP или Python на сервере заказчика. Создавать open source не только в виде кода, но и настройкой пакетов из нескольких приложений, написанных на разных языках, работающих на разных слоях OSI.


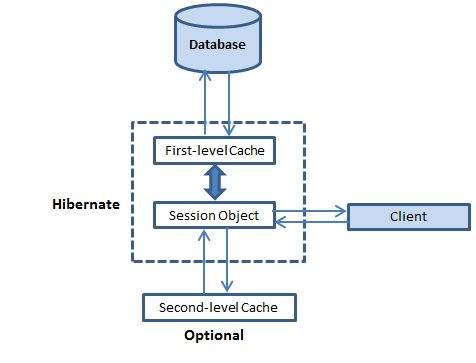



 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
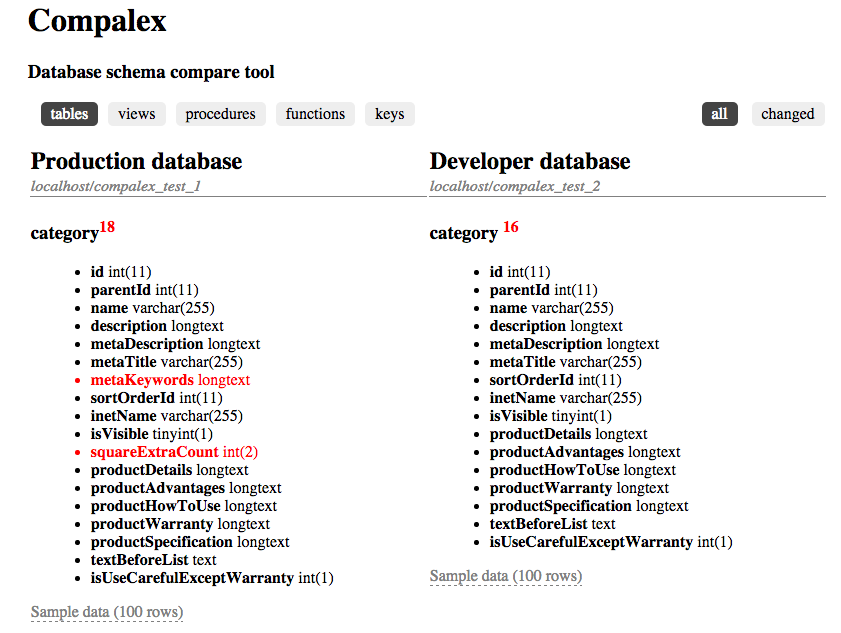
 В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (
 CSS-препроцессоры в своё время значительно облегчали работу по написанию CSS кода. Однако в некотором роде все они были несовершенны и имели значительные изъяны в работе. А потому на смену препроцессорам пришёл постпрепроцессор PostCSS.
CSS-препроцессоры в своё время значительно облегчали работу по написанию CSS кода. Однако в некотором роде все они были несовершенны и имели значительные изъяны в работе. А потому на смену препроцессорам пришёл постпрепроцессор PostCSS. Если вы владелец интернет-магазина и хотите, чтобы покупатель мог оплатить товары удобным ему способом, у вас есть два пути: подключать и настраивать оплату для каждой платежной системы отдельно — мучиться с интеграцией, подписанием договоров… либо сделать все быстро и без лишней волокиты — воспользоваться услугами компании, которая является платежным агрегатором. При выборе последнего варианта вам понадобится подписать всего один договор, а ваш покупатель сможет выбрать удобный ему способ оплаты из десятков доступных. Это и оффлайн способы, и электронные кошельки и, конечно же, оплата банковской картой. Платежных агрегаторов множество.
Если вы владелец интернет-магазина и хотите, чтобы покупатель мог оплатить товары удобным ему способом, у вас есть два пути: подключать и настраивать оплату для каждой платежной системы отдельно — мучиться с интеграцией, подписанием договоров… либо сделать все быстро и без лишней волокиты — воспользоваться услугами компании, которая является платежным агрегатором. При выборе последнего варианта вам понадобится подписать всего один договор, а ваш покупатель сможет выбрать удобный ему способ оплаты из десятков доступных. Это и оффлайн способы, и электронные кошельки и, конечно же, оплата банковской картой. Платежных агрегаторов множество. 