
Случилось вот что: вышел большой отчёт про возможности GPT-4V. Внезапно оказалось, что LLM могут обращаться с картинками так же, как с текстовыми промптами, и никакой особой разницы нет. Что та фигня, что эта фигня, главное — научиться распознавать, дальше те же логические связки. Это давно ожидалось, потому что люди в основном смотрят, и большая часть информации приходит через глаза. Но мало кто ждал, что это так круто получится вот уже сейчас и с LLM.
Отчёт вот. Теперь давайте смотреть, а не читать.

Хорошие мультимодальные способности, чётко считывает указатели, хорошее общее понимание ситуации
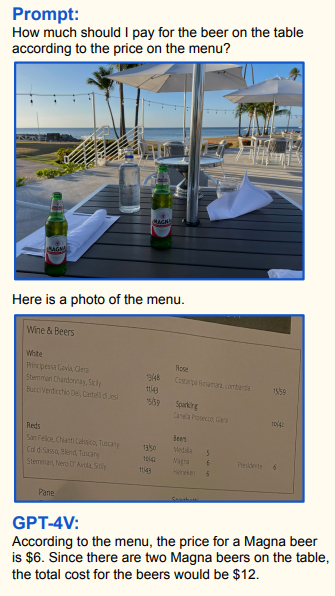
Если вы пьяны, он пересчитает пиво и сверит с чеком:
Собственно, важное:
Давайте к деталям.
Отчёт вот. Теперь давайте смотреть, а не читать.
Хорошие мультимодальные способности, чётко считывает указатели, хорошее общее понимание ситуации
Если вы пьяны, он пересчитает пиво и сверит с чеком:
Собственно, важное:
- Хорошо понимает что за сцена изображена и какие взаимосвязи между объектами на ней.
- Читает текст, ориентируется на местности, опознаёт конкретных людей
- Умеет в абстракции и обратно
- Отлично ищет то, чего не должно быть (отклонения от базовой идеи) — дефекты на деталях, дефекты в людях (в особенности на рентгене) и так далее.
- Плохо считает.
Давайте к деталям.






