
Привет, Хабр!
Это статья больше для начинающих или любознательных, тут я постарался простыми словами объяснить что же такое эта база данных и для чего они используются на проектах.

Data Engineer
Привет, Хабр!
Это статья больше для начинающих или любознательных, тут я постарался простыми словами объяснить что же такое эта база данных и для чего они используются на проектах.

Привет, Хабр!
Я решил посвятить свою первую статью SQL. Вопросы, рассмотренные ниже мне задавали на собеседованиях на позицию python-разработчика. Естественно отвечать правильно получалось не всегда, а если точнее то чаще не правильно, однако проведя N часов в рефлексии я составил перечень ответов, которыми пользуюсь до сих пор.
Данная информация предполагает знание основ языка запросов и я надеюсь, она окажется полезной для разработчиков, которые сейчас активно ищут работу а также, что ты прочитаешь этот текст до конца и добавишь свой вопрос к перечню (ну или поправишь неточности в существующих)
В современном мире большинство бизнес-процессов связаны с обработкой больших объемов данных, получаемых от различных источников. Часто эти данные содержат ошибки, дубликаты и пропуски, что может привести к неверным выводам и решениям. Одним из инструментов, которые позволяют очистить и преобразовать данные, является библиотека pandas для языка программирования Python.
Я собираюсь рассмотреть задачу по очистке данных с помощью pandas. Для этого возьмем данные, содержащие дубликаты строк, неправильные типы данных, пропуски и отрицательные значения. Затем я буду использовать функциональные возможности pandas для очистки и преобразования этих данных в форму, пригодную для дальнейшего анализа.
Предположим, у вас есть набор данных, содержащий информацию о продажах компании за последние несколько лет. Но данные не очень чистые, и вы заметили, что есть некоторые проблемы с форматированием и некоторые строки содержат ошибки.
Задача: Необходимо очистить данные о продажах компании за последние несколько лет с помощью библиотеки Pandas.

Взлом Instagram*‑аккаунта — популярный запрос в поисковиках. Поэтому есть смысл рассказать о том, как это обычно работает. Просто для того, чтобы вы знали, откуда может пойти атака.

Пошаговая инструкция о том, как из одного DAG сделать фабрику DAG.
Включает в себя: установка Airflow через Docker и поэтапное объяснение того, как сделать фабрику DAG.

ChatGPT — это сервис на базе Искусственного Интеллекта (Artificial intelligence) от команды Open. AI (используется более продвинутая языковая модель GPT-3.5, скоро выйдет 4-я версия, и будет совсем космос). В чем фишка? Вы общаетесь с ним как будто с человеком в чате.
В этой статье я хочу показать на рабочих примерах как сервис ChatGTP может помочь получить в разы больше интервью при поиске работы при правильном его использовании. Попробуйте эти 6 советов по ChatGPT, чтобы вдвое сократить время поиска работы (и втрое увеличить количество собеседований).

Все об использовании шаблонов в Airflow с примерами кода. Продолжение серии публикаций astronomer.io

Python-модуль asyncio позволяет заниматься асинхронным программированием с применением конкурентного выполнения кода, основанного на корутинах. Хотя этот модуль имеется в Python уже много лет, он остаётся одним из самых интересных механизмов языка. Но asyncio, при этом, можно назвать ещё и одним из модулей, которые вызывают больше всего недоразумений. Дело в том, что начинающим разработчикам бывает трудно приступить к использованию asyncio.
Перед вами — подробное и всестороннее руководство по использованию модуля asyncio в Python. В частности, здесь будут рассмотрены следующие основные вопросы:

Автор материала кратко, наглядно и с примерами кода представлет три пакета Python, заметно упрощающих и ускоряющих исследовательский анализ данных. Подборкой делимся к старту нашего флагманского курса по Data Science.


Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.

Чему нужно обучить junior QA, чтобы он начал приносить пользу проекту? Конечно, было бы здорово «всему и сразу», но это может затянуться надолго. А вот с основами тестирования можно познакомить буквально за пару-тройку дней. Особенно если это фулл-тайм дни (рабочее время).
Я обучаю новичков больше 6 лет, больше тысячи людей выпустила, книгу вот написала. И на опыте студентов вижу, что «план-минимум» на самом деле небольшой.
Если перед вами стоит задача «завтра выйдут два джуниора, обучи их», начните с основ. Один из вариантов:
• дали посмотреть видео или прочитать статьи;
• собрались вместе в переговорке или зуме, обсудили;
• дали ДЗ на закрепление материала;
• через три дня получили более-менее адекватного джуна, профит!
В этом посте я собрала ссылки в помощь по каждой теме:
• видео — варианты из публичного доступа. Выбираете то, что больше по душе, отдаете падаванам;
• статьи — даете как дополнительный материал.
В итоге затраты на подготовку — меньше, а польза от новичков — быстрее.


Форматированные строковые литералы, которые ещё называют f-строками (f-strings), появились довольно давно, в Python 3.6. Поэтому все знают о том, что это такое, и о том, как ими пользоваться. Правда, f-строки обладают кое-какими полезными возможностями, некоторыми особенностями, о которых кто-нибудь может и не знать. Разберёмся с некоторыми интересными возможностями f-строк, которые могут оказаться очень кстати в повседневной работе Python-программиста.

Apache NiFi динамично развивается и на сегодняшний день обладает достаточно большим набором возможностей, позволяющим отслеживать состояние потоков данных, ошибки и предупреждения, возникающие в процессорах и на кластере, а также состояние кластера.
Первая статья посвящена мониторингу потоков данных с помощью инструмента GUI NiFi. В последующих материалах мы рассмотрим задачи отчетности, опишем примеры сбора метрик и визуализации при помощи таких популярных систем, как Prometheus и Grafana.
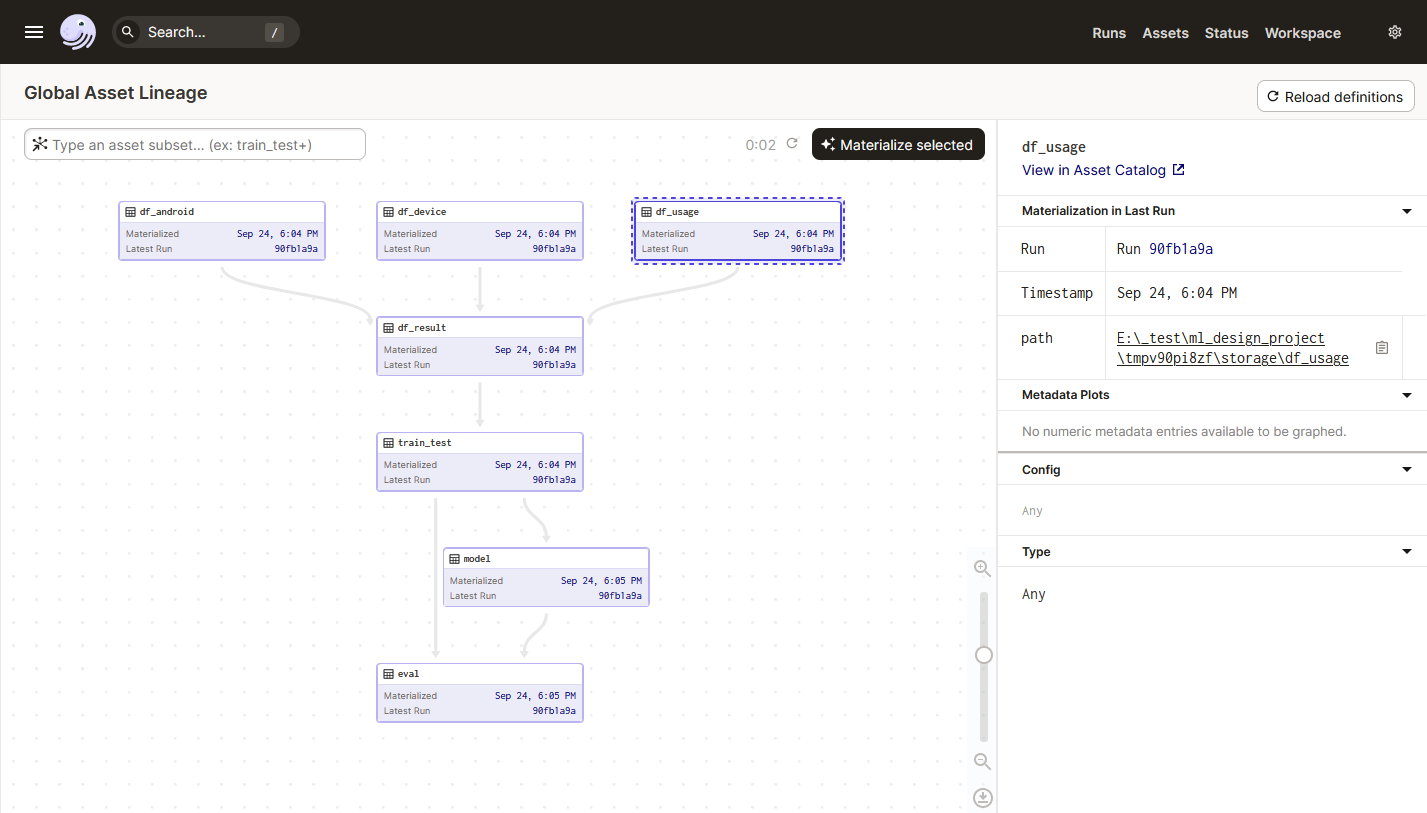
Dagster — это оркестратор, предназначенный для организации конвейеров обработки данных: ETL, проведение тестов, формирование отчетов, обучение ML-моделей и т.д.
На паре несложных примеров посмотрим как его развернуть, настроить и работать с ним.

Привет, Хабр!
Структурированные данные – хорошо, а полуструктурированные – не проблема. Формат json хоть и является очень популярным, однако не очень удобен для анализа, особенно если данных много, и они разделены на отдельные файлы.
Разберем преобразование множества json файлов различной структуры в привычный аналитикам pandas.DataFrame.

Нет данных? Сгенерируй!
Рассмотрим три самых интересных, в плане функциональности и простоты использования, способа генерации синтетических данных с помощью пакетов Python .

Библиотека Pandas — это весьма эффективный инструмент для обработки данных, представляющих собой временные ряды. На самом деле, эта библиотека была создана Уэсом МакКинни для работы с финансовыми данными, которые состоят, главным образом, из временных рядов.
При работе с временными рядами много сил уходит на выполнение различных операций с датой и временем. Этот материал посвящён ответам на четыре распространённых вопроса из данной сферы.
Возможно, вы уже сталкивались с этими вопросами. Ответить на все из них, кроме последнего, можно сравнительно просто. А вот ответ на последний, довольно-таки хитрый вопрос, представляет собой последовательность из нескольких действий.
Начнём с создания учебного датафрейма (объекта DataFrame), с которым будем экспериментировать:

Вы вряд ли найдете в интернете что-то про разработку ботов, кроме документаций к библиотекам, историй "как я создал такого-то бота" и туториалов вроде "как создать бота, который будет говорить hello world". При этом многие неочевидные моменты просто нигде не описаны.
Как вообще устроены боты? Как они взаимодействуют с пользователями? Что с их помощью можно реализовать, а что нельзя?
Подробный гайд о том, как работать с ботами — под катом.