DoH в картинках
11 мин
Перевод
Угрозы конфиденциальности и безопасности в интернете становятся серьёзнее. Мы в Mozilla внимательно их отслеживаем. Считаем своей обязанностью сделать всё возможное для защиты пользователей Firefox и их данных.
Нас беспокоят компании и организации, которые тайно собирают и продают пользовательские данные. Поэтому мы добавили защиту от слежения и создали расширение контейнера Facebook. В ближайшие месяцы появится ещё больше защитных мер.
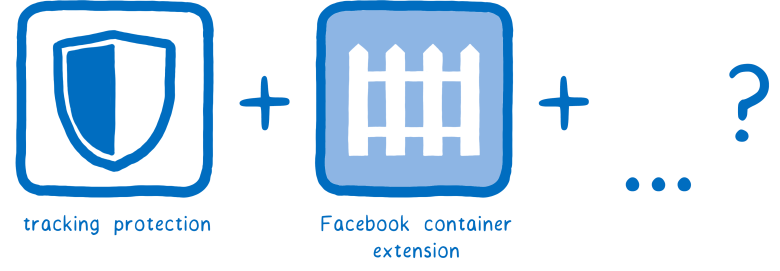
Сейчас мы добавляем в список ещё две технологии:
Нас беспокоят компании и организации, которые тайно собирают и продают пользовательские данные. Поэтому мы добавили защиту от слежения и создали расширение контейнера Facebook. В ближайшие месяцы появится ещё больше защитных мер.
Сейчас мы добавляем в список ещё две технологии:
- DNS по HTTPS — новый стандарт IETF, в разработке которого мы приняли участие
- Trusted Recursive Resolver — новый безопасный способ резолвить DNS, предоставляется совместно с Cloudflare
 Здравствуйте, в эфире Радио SQL!
Здравствуйте, в эфире Радио SQL!