Я собрал здесь некоторые не очень очевидные факты о заглавных и строчных буквах, с которыми может столкнуться программист в работе. Многие из вас переводили строки во «все заглавные» (uppercase), «все строчные» (lowercase), «первую заглавную, а остальные строчные» (titlecase). Ещё более популярна операция сравнения без учёта регистра. В мировом масштабе такие операции могут быть весьма нетривиальны. Пост построен в виде «сборника заблуждений» с контрпримерами.
1. Если я переведу строку в uppercase или lowercase, число Unicode-символов не изменится.
Нет. В тексте могут попасться строчные лигатуры, которым не соответствует один символ в верхнем регистре. Например, при переводе в uppercase: fi (U+FB00) -> FI (U+0046, U+0049)
2. Лигатуры — изврат, ими никто не пользуется. Если их не учитывать, то я прав.
Нет. Некоторым буквам с диакритикой нет точного соответствия в другом регистре, поэтому приходится использовать комбинированный символ. Скажем, в языке африкаанс есть буква
ʼn (U+0149). В верхнем регистре ей соответствует комбинация из двух символов:

(U+02BC, U+004E). Если вам попадётся транслитерация арабского текста, вы можете
столкнуться с

(U+1E96), которой в верхнем регистре также нет односимвольного соответствия, поэтому придётся заменять на

(U+0048, U+0331). В
ваханском языке есть буква

(U+01F0) с аналогичной проблемой. Вы можете возразить, что это экзотика, однако на африкаанс в википедии 23000 статей.
3. Ну хорошо, но давайте считать комбинированный символ (с участием modifying или combining code points) одним символом. Тогда длина всё же сохранится.
Нет. Есть, например, в немецком языке буква «эсцет» ß (U+00DF). При переводе в верхний регистр, она превращается в два символа SS (U+0053, U+0053).


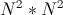 . Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.
. Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.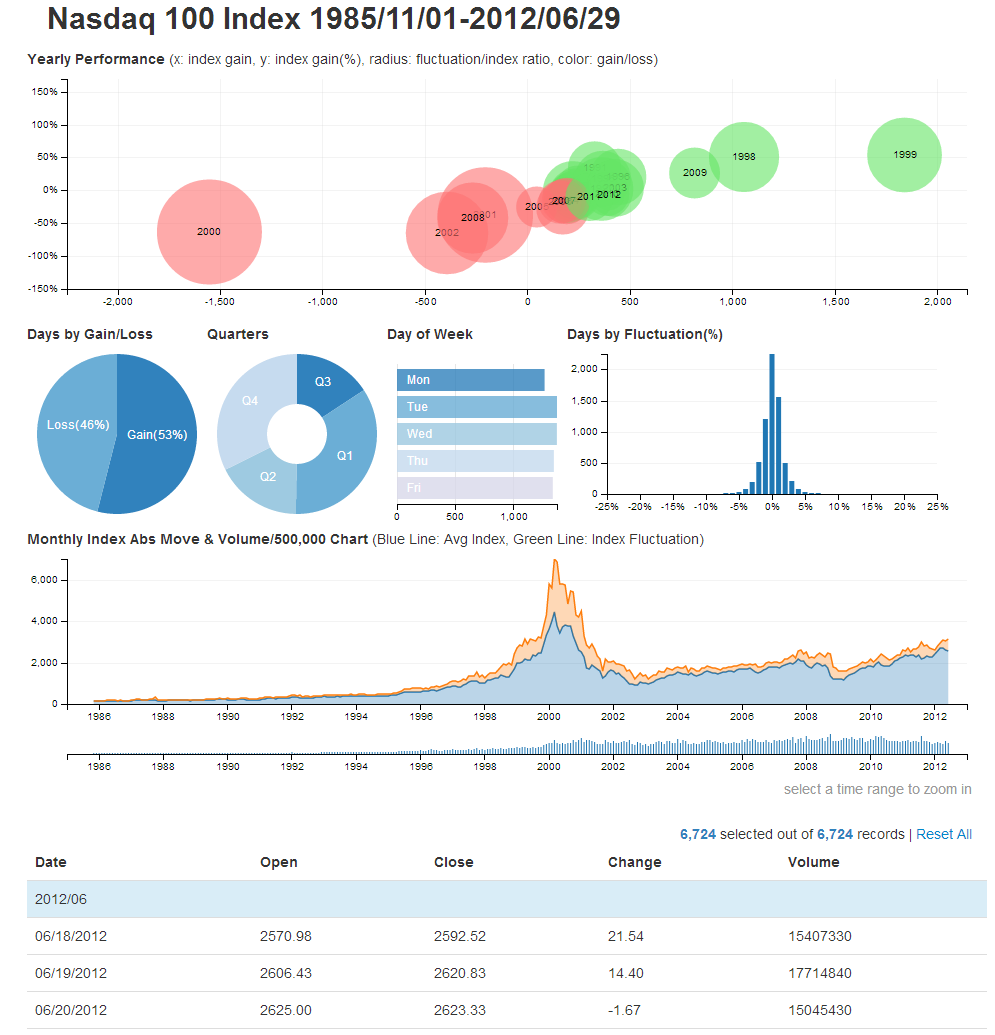

 Привет. В этой статье будет рассмотрен способ
Привет. В этой статье будет рассмотрен способ  Все по прежнему: эксперты отвечают на вопросы не экспертов.
Все по прежнему: эксперты отвечают на вопросы не экспертов.