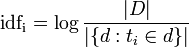Сколько бы ни говорили, что логи способны полностью заменить отладку, увы и ах — это не совсем так, а иногда — совсем не так. Действительно, иногда и в голову не придет, что надо было писать в лог именно эту переменную — в то же время, в режиме отладки можно часто просмотреть сразу несколько структур данных; можно, в конце концов, наткнутся на проблемный участок абсолютно случайно. Поэтому иногда отладка неизбежна, и часто она способна сэкономить очень немало времени.
Отлаживать однопоточное Java приложение просто. Отлаживать многопоточное Java приложение — чуть сложнее, но все равно просто. Отлаживать мультипроцессное Java приложение? С процессами, запущенными на разных машинах? Это определенно сложнее. Именно поэтому все руководства по Hadoop рекомендуют обращаться к отладке только и исключительно тогда, когда другие опции (читай: логгинг) исчерпаны и не помогли. Ситуация зачастую усложняется тем, что на больших кластерах у вас может и не быть доступа к конкретным map/reduce узлам (именно с этим вариантом я и столкнулся). Но давайте решать проблему по частям. Итак…
Самый простой вариант из всех возможных. Локальная инсталляция Hadoop — все выполняется на одной машине, и более того — в одном процессе, но в разных потоках. Отладка эквивалентна отладке обычного мультипоточного Java приложения — что может быть тривиальнее?
Как же этого добиться? Мы идем в директорию, где у нас развернут наш локальных Hadoop (я полагаю, что вы умеете это делать или умеете прочитать соответствующую инструкцию и уже теперь с этим справитесь).
Наша задача — добавить еще одну опцию JVM, где-то в районе 282-283 строки (в зависимости от версии, номер может и измениться), сразу после того, как скрипт закончил формировать
Отлаживать однопоточное Java приложение просто. Отлаживать многопоточное Java приложение — чуть сложнее, но все равно просто. Отлаживать мультипроцессное Java приложение? С процессами, запущенными на разных машинах? Это определенно сложнее. Именно поэтому все руководства по Hadoop рекомендуют обращаться к отладке только и исключительно тогда, когда другие опции (читай: логгинг) исчерпаны и не помогли. Ситуация зачастую усложняется тем, что на больших кластерах у вас может и не быть доступа к конкретным map/reduce узлам (именно с этим вариантом я и столкнулся). Но давайте решать проблему по частям. Итак…
Сценарий первый: локальный Hadoop
Самый простой вариант из всех возможных. Локальная инсталляция Hadoop — все выполняется на одной машине, и более того — в одном процессе, но в разных потоках. Отладка эквивалентна отладке обычного мультипоточного Java приложения — что может быть тривиальнее?
Как же этого добиться? Мы идем в директорию, где у нас развернут наш локальных Hadoop (я полагаю, что вы умеете это делать или умеете прочитать соответствующую инструкцию и уже теперь с этим справитесь).
$ cd ~/dev/hadoop
$ cp bin/hadoop bin/hdebug
$ vim bin/hdebug Наша задача — добавить еще одну опцию JVM, где-то в районе 282-283 строки (в зависимости от версии, номер может и измениться), сразу после того, как скрипт закончил формировать
$HADOOP_OPTS: