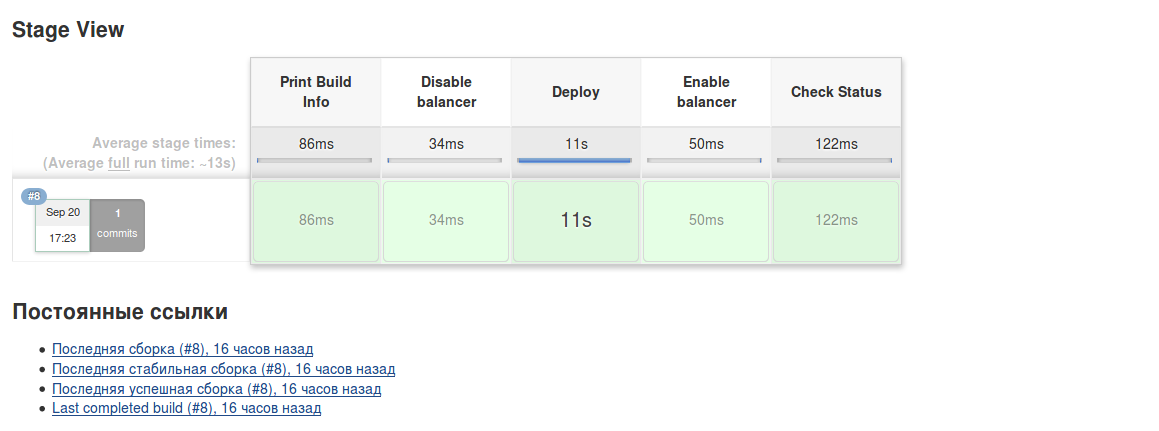
В докладе представлены некоторые подходы, которые позволяют следить за производительностью SQL-запросов, когда их миллионы в сутки, а контролируемых серверов PostgreSQL — сотни.
Какие технические решения позволяют нам эффективно обрабатывать такой объем информации, и как это облегчает жизнь обычного разработчика.
Кому интересен разбор конкретных проблем и разные техники оптимизаций SQL-запросов и решения типовых DBA-задач в PostgreSQL — можно также ознакомиться с серией статей на эту тему.
Какие технические решения позволяют нам эффективно обрабатывать такой объем информации, и как это облегчает жизнь обычного разработчика.
Кому интересен разбор конкретных проблем и разные техники оптимизаций SQL-запросов и решения типовых DBA-задач в PostgreSQL — можно также ознакомиться с серией статей на эту тему.



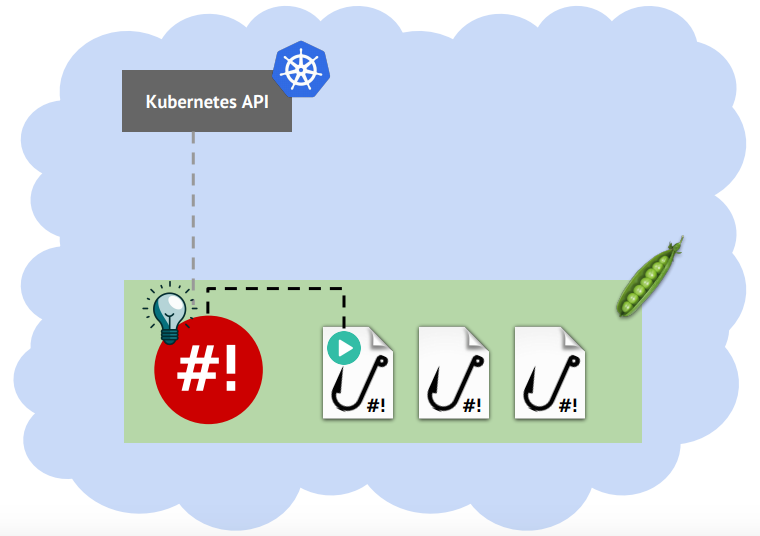


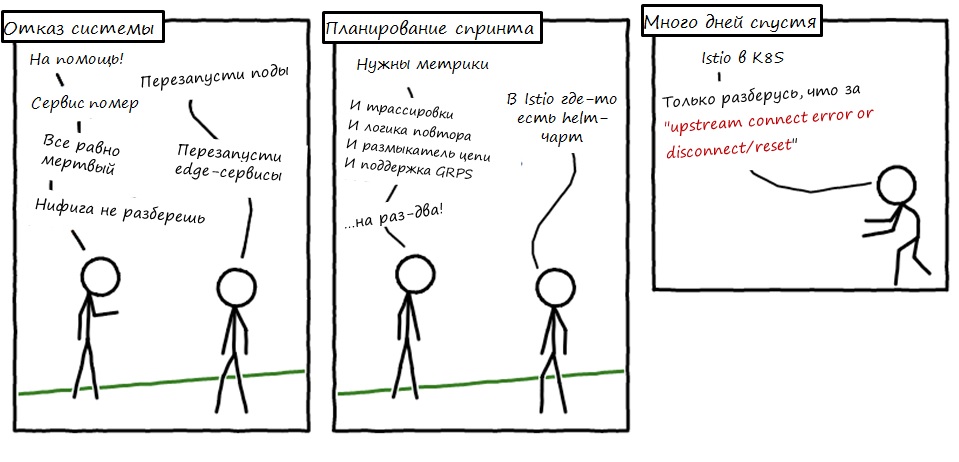
 Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.
Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.