Вольный пересказ документации к sync.Pool

Dmitry M @x88
Golang Lead [Blockchain, Architect, Security]
How to start a startup: Юридические основы запуска стартапа
12 мин
Перевод

Cтэнфордский курс CS183B: How to start a startup. Стартовал в 2012 году под руководством Питера Тиля. Осенью 2014 года прошла новая серия лекций ведущих предпринимателей и экспертов Y Combinator:
Вторая часть курса
Первая часть курса
- Сэм Альтман и Дастин Московитц: Как и зачем создавать стартап?
- Сэм Альтман: Как сформировать команду и культуру стартапа?
- Пол Грэм: Нелогичный стартап;
- Адора Чьюнг: Продукт и кривая честности;
- Адора Чьюнг: Стремительный рост стартапа;
- Питер Тиль: Конкуренция – удел проигравших;
- Питер Тиль: Как построить монополию?
- Алекс Шульц: Введение в growth hacking [1, 2, 3];
- Кевин Хейл: Тонкости в работе с пользовательским опытом [1, 2];
- Стэнли Тэнг и Уокер Уильямс: Начинайте с малого;
- Джастин Кан: Как работать с профильными СМИ?
- Андрессен, Конуэй и Конрад: Что нужно инвестору;
- Андрессен, Конуэй и Конрад: Посевные инвестиции;
- Андрессен, Конуэй и Конрад: Как работать с инвестором;
- Брайан Чески и Альфред Лин: В чем секрет культуры компании?
- Бен Сильберман и братья Коллисон: Нетривиальные аспекты командной работы [1, 2];
- Аарон Леви: Разработка B2B-продуктов;
- Рид Хоффман: О руководстве и руководителях;
- Рид Хоффман: О лидерах и их качествах;
- Кит Рабуа: Управление проектами;
- Кит Рабуа: Развитие стартапа;
- Бен Хоровитц: Увольнения, повышения и переводы по службе;
- Бен Хоровитц: Карьерные советы, вестинг и опционы;
- Эммет Шир: Как проводить интервью с пользователями;
- Эммет Шир: Как в Twitch разговаривают с пользователями;
- Хосейн Рахман: Как в Jawbone проектируют hardware-продукты;
- Хосейн Рахман: Процесс проектирования в Jawbone.
Фишинг в корпоративной среде
7 мин

Фишинговые сообщения электронной почты в корпоративной среде обычно знаменуют собой таргетированную атаку, хорошо продуманы и реализованы. В отличии от рядовых пользователей, сотрудники компаний могут быть проинструктированы должным образом о существующих угрозах информационной безопасности. За сообщениями электронной почты может быть установлен тот или иной контроль со стороны сотрудников ИТ/ИБ подразделений.
Анализ тональности текста с помощью Azure Machine Learning
8 мин
Туториал
В этом посте я расскажу, как можно использовать Microsoft Azure Machine Learning для анализа тональности текста, а также с какими проблемами можно столкнуться в процессе использования Azure ML и как их можно обойти.
Что такое анализ тональности хорошо описано в статье «Обучаем компьютер чувствам (sentiment analysis по-русски)».
Нашей целью будет являться построение веб-сервиса, который принимает на вход некоторый текст и возвращает в ответ 1, если этот текст носит позитивный характер, и -1 — если негативный. Microsoft Azure Machine Learning идеально (почти) подходит для этой задачи, так как там есть встроенная возможность опубликовать результаты вычислений как веб-сервис и поддержка языка R — это избавляет от необходимости писать свои костыли и настраивать свою виртуальную машину/веб-сервер. В общем, все преимущества облачных технологий. К тому же, совсем недавно было объявлено, что все желающие могут попробовать Azure ML даже без аккаунта Azure и кредитной карточки — необходим только Microsoft Account.
Что такое анализ тональности хорошо описано в статье «Обучаем компьютер чувствам (sentiment analysis по-русски)».
Нашей целью будет являться построение веб-сервиса, который принимает на вход некоторый текст и возвращает в ответ 1, если этот текст носит позитивный характер, и -1 — если негативный. Microsoft Azure Machine Learning идеально (почти) подходит для этой задачи, так как там есть встроенная возможность опубликовать результаты вычислений как веб-сервис и поддержка языка R — это избавляет от необходимости писать свои костыли и настраивать свою виртуальную машину/веб-сервер. В общем, все преимущества облачных технологий. К тому же, совсем недавно было объявлено, что все желающие могут попробовать Azure ML даже без аккаунта Azure и кредитной карточки — необходим только Microsoft Account.
Перенос данных в Россию. Краткий FAQ по заблуждениям
5 мин
Фраза «уж сколько раз твердили миру» наверно идеально подходит под описание ситуации с защитой персональных данных и их переноса в Россию. За прошедшее с начала обсуждений проблем в этой области время казалось бы обсуждено все. И тем более юристы должны уметь читать законы.
Увы. Посещение очередной конференции развеяло для меня этот миф, в связи с чем я предлагаю в копилку Хабражителям ответы на типовые вопросы в области переноса данных.
Увы. Посещение очередной конференции развеяло для меня этот миф, в связи с чем я предлагаю в копилку Хабражителям ответы на типовые вопросы в области переноса данных.
Деплой Go-серверов с помощью Docker
5 мин
Перевод
Введение
На этой неделе команда Docker анонсировала официальные базовые образы для Go и других основных языков, предоставляя разработчикам простой и надежный способ создания контейнеров для программ на Go.
В этой статье мы шаг за шагом пройдём создание Docker-контейнера для простого веб-приложения на Go а также деплой этого контейнера в Google Compute Engine. Если вы ещё не знакомы с Docker, вам следует прочесть статью Understanding Docker, прежде чем читать дальше.
Понимая Docker
7 мин
Уже несколько месяцев использую docker для структуризации процесса разработки/доставки веб-проектов. Предлагаю читателям «Хабрахабра» перевод вводной статьи о docker — «Understanding docker».
Докер — это открытая платформа для разработки, доставки и эксплуатации приложений. Docker разработан для более быстрого выкладывания ваших приложений. С помощью docker вы можете отделить ваше приложение от вашей инфраструктуры и обращаться с инфраструктурой как управляемым приложением. Docker помогает выкладывать ваш код быстрее, быстрее тестировать, быстрее выкладывать приложения и уменьшить время между написанием кода и запуска кода. Docker делает это с помощью легковесной платформы контейнерной виртуализации, используя процессы и утилиты, которые помогают управлять и выкладывать ваши приложения.
Что такое докер?
Докер — это открытая платформа для разработки, доставки и эксплуатации приложений. Docker разработан для более быстрого выкладывания ваших приложений. С помощью docker вы можете отделить ваше приложение от вашей инфраструктуры и обращаться с инфраструктурой как управляемым приложением. Docker помогает выкладывать ваш код быстрее, быстрее тестировать, быстрее выкладывать приложения и уменьшить время между написанием кода и запуска кода. Docker делает это с помощью легковесной платформы контейнерной виртуализации, используя процессы и утилиты, которые помогают управлять и выкладывать ваши приложения.
Правильное использование QThread
5 мин
В недавнем проекте с Qt пришлось разбираться с классом QThread. В результате вышел на «правильную» технологию работы c QThread, которую буду использовать в других проектах.
Еще раз про приведение типов в языке С++ или расстановка всех точек над cast
8 мин

Этот пост попытка кратко оформить все, что я читал или слышал из разных источников про операторы приведения типов в языке C++. Информация ориентирована в основном на тех, кто изучает C++ относительно недолго и, как мне кажется, должна помочь понять cпецифику применения данных операторов. Старожилы и гуру С++ возможно помогут дополнить или скорректировать описанную мной картину. Всех интересующихся приглашаю под кат.
Обработка ошибок в Go: Defer, Panic и Recover
5 мин
Перевод
В языке Go используются обычные способы управления потоком выполнения: if, for, switch, goto. Есть ещё оператор go, чтобы запустить код в отдельной го-процедуре. А сейчас я бы хотел обсудить менее обычные способы: defer, panic и recover.
Команда defer помещает вызов функции в список. Этот список отложенных вызовов выполняется после того, как объемлющая функция завершит выполнение. Defer обычно используется для упрощения функций, которые занимаются освобождением ресурса.
Например, посмотрим на функцию, которая открывает два файла и копирует содержимое из одного файла в другой:
Команда defer помещает вызов функции в список. Этот список отложенных вызовов выполняется после того, как объемлющая функция завершит выполнение. Defer обычно используется для упрощения функций, которые занимаются освобождением ресурса.
Например, посмотрим на функцию, которая открывает два файла и копирует содержимое из одного файла в другой:
Windows 10 по 10. Выпуск #1. Как повысить заметность и частоту установок
10 мин
Перевод
Приветствуем в первой статье из серии Windows 10 по 10. Мы начнем серию с того, откуда начинается ваше взаимодействие с пользователями — с магазина Windows Store.
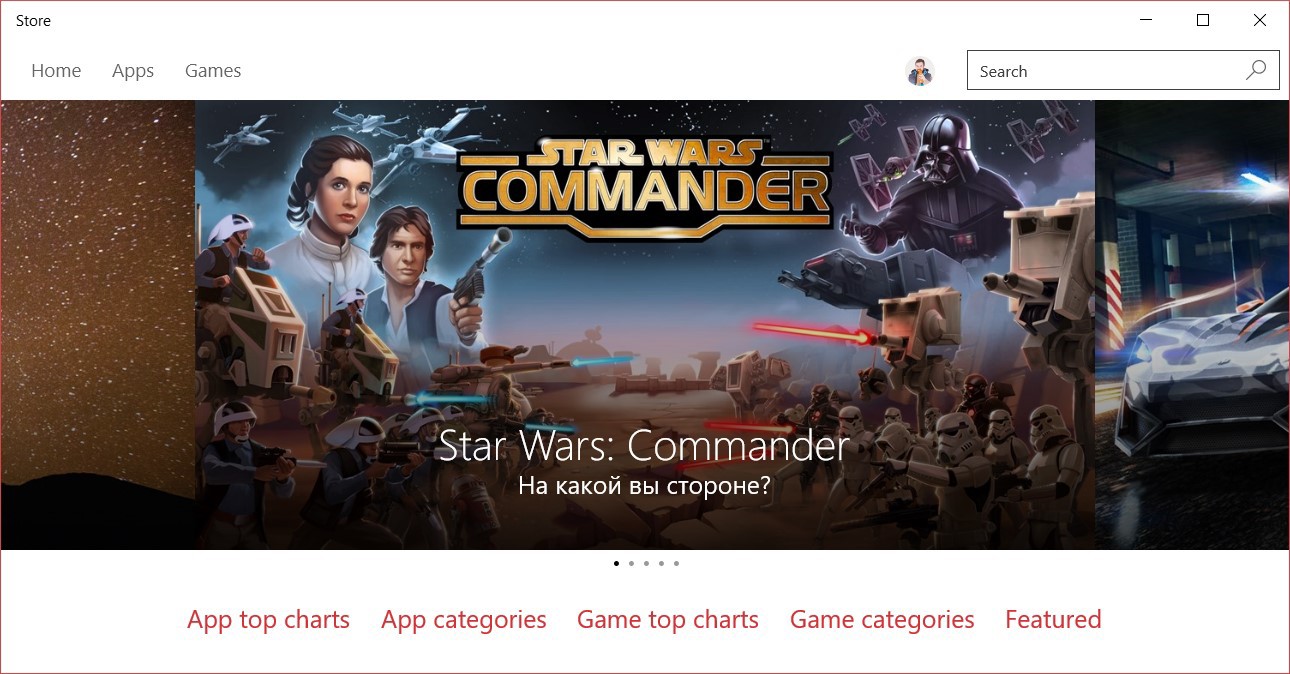
Чтобы убедиться, что ваши приложения находятся и запускаются пользователями Windows 10, рекомендуем проделать три упражнения прямо сейчас:
Даже если вы просто потратите один час на этой неделе, вы не только улучшите свое представительство в Windows 10, но и также сможете определить для себя базовые показатели, от которых вы сможете отталкиваться по мере развития и улучшения вашего приложения.
Чтобы убедиться, что ваши приложения находятся и запускаются пользователями Windows 10, рекомендуем проделать три упражнения прямо сейчас:
- Обновить описание в магазине для повышения шансов приложения быть установленным.
- Начать отслеживать использование приложения с помощь Visual Studio Application Insights и новых отчетов об использовании.
- Научиться использовать новые возможности магазина для отслеживания успешности проводимых кампаний.
Даже если вы просто потратите один час на этой неделе, вы не только улучшите свое представительство в Windows 10, но и также сможете определить для себя базовые показатели, от которых вы сможете отталкиваться по мере развития и улучшения вашего приложения.
Прокладка трубопровода со spark.ml
8 мин
Туториал
 Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.
Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.Ну что же, давайте проверим, что может новый пакет и насколько он хорош.
Как устроена apache cassandra
13 мин

В этом топике я хотел бы рассказать о том, как устроена кассандра (cassandra) — децентрализованная, отказоустойчивая и надёжная база данных “ключ-значение”. Хранилище само позаботится о проблемах наличия единой точки отказа (single point of failure), отказа серверов и о распределении данных между узлами кластера (cluster node). При чем, как в случае размещения серверов в одном центре обработки данных (data center), так и в конфигурации со многими центрами обработки данных, разделенных расстояниями и, соответственно, сетевыми задержками. Под надёжностью понимается итоговая согласованность (eventual consistency) данных с возможностью установки уровня согласования данных (tune consistency) каждого запроса.
NoSQL базы данных требуют в целом большего понимания их внутреннего устройства чем SQL. Эта статья будет описывать базовое строение, а в следующих статьях можно будет рассмотреть: CQL и интерфейс программирования; техники проектирования и оптимизации; особенности кластеров размещённых в многих центрах обработки данных.
Анализируем большие объемы данных с Apache Spark
1 мин

С анализом больших объемов данных постепенно начинают сталкиваться не только крупнейшие IT-компании, но и обычные разработчики. В нашей компании в ряде проектов такая задача возникает, и мы решили систематизировать накопленный опыт, поделившись с коллегами по i-Free и нашими партнерами наиболее эффективными инструментами и технологиями. Сегодня речь пойдет о применении Apache Spark
Иерархическая классификация сайтов на Python
8 мин
Привет, Хабр! Как упоминалось в прошлой статье, немаловажной частью нашей работы является сегментация пользователей. Как же мы это делаем? Наша система видит пользователей как уникальные идентификаторы cookies, которые им присваиваем мы или наши поставщики данных. Выглядит этот id, например, так:
Эти номера выступают ключами в различных таблицах, но первоначальным value является, в первую очередь, URL страниц, на которых данная кука была загружена, поисковые запросы, а также иногда некоторая дополнительная информация, которую даёт поставщик – IP-адрес, timestamp, информация о клиенте и прочее. Эти данные довольно неоднородные, поэтому наибольшую ценность для сегментации представляет именно URL. Создавая новый сегмент, аналитик указывает некоторый список адресов, и если какая-то кука засветится на одной из этих страничек, то она попадает в соответствующий сегмент. Получается, что чуть ли не 90% рабочего времени таких аналитиков уходит на то, чтобы подобрать подходящий набор урлов – в результате кропотливой работы с поисковиками, Yandex.Wordstat и другими инструментами.
Получив таким образом более тысячи сегментов, мы поняли, что этот процесс нужно максимально автоматизировать и упростить, при этом иметь возможность мониторинга качества алгоритмов и предоставить аналитикам удобный интерфейс для работы с новым инструментом. Под катом я расскажу, как мы решаем эти задачи.
42bcfae8-2ecc-438f-9e0b-841575de7479Эти номера выступают ключами в различных таблицах, но первоначальным value является, в первую очередь, URL страниц, на которых данная кука была загружена, поисковые запросы, а также иногда некоторая дополнительная информация, которую даёт поставщик – IP-адрес, timestamp, информация о клиенте и прочее. Эти данные довольно неоднородные, поэтому наибольшую ценность для сегментации представляет именно URL. Создавая новый сегмент, аналитик указывает некоторый список адресов, и если какая-то кука засветится на одной из этих страничек, то она попадает в соответствующий сегмент. Получается, что чуть ли не 90% рабочего времени таких аналитиков уходит на то, чтобы подобрать подходящий набор урлов – в результате кропотливой работы с поисковиками, Yandex.Wordstat и другими инструментами.
Получив таким образом более тысячи сегментов, мы поняли, что этот процесс нужно максимально автоматизировать и упростить, при этом иметь возможность мониторинга качества алгоритмов и предоставить аналитикам удобный интерфейс для работы с новым инструментом. Под катом я расскажу, как мы решаем эти задачи.
Автоматическое определение рубрики текста
5 мин
Введение
В предыдущих статьях, посвященных организации данных в виде рубрикатора (Использование графа, как основы для создания рубрикатора и Проблемы, подстерегающие любого создателя рубрикаторов) были описаны общие идеи по организации рубрикатора. В этой статье я опишу один из возможных алгоритмов автоматического определения тематики текста на основе заранее подготовленного графа-рубрикатора. При этом я сознательно избегаю сложных формул, чтобы донести идею, лежащую в основе алгоритма, максимально просто.
Подготовка данных рубрикатора
Для начала определимся с тем, в каком виде мы будем готовить данные для рубрикатора.
- 1. Рубрикатор – это граф, а не дерево
- 2. Текст, тематика которого определяется, может быть отнесен к нескольким рубрикам одновременно
- 3. Для каждого соотнесения с рубрикой указывается коэффициент точности определения рубрики
- 4. Тематика текста определяется для каждого текста отдельно, и не зависит от того как были определены рубрики других текстов ранее
Последний пункт нуждается в небольшом пояснении. Независимость определения тематики текста очень хороша, когда не требуется последующая сортировка результатов. Когда тексты просто отнесены к рубрики или нет. Но при наличии в рубрике нескольких текстов, наверняка возникнет необходимость отсортировать их по критерию наилучшего попадания в рубрику. В данной статье этот вопрос опущен для ясности.
Алгоритм определения тематики текста, кратко
Описываем рубрикатор. Извлекаем из исследуемого текста ключевые слова, описанные в рубрикаторе. В результате извлечения получаем кусочки разорванного и чаще всего несвязного графа. Используем волновой (или любой другой, по желанию) алгоритм для «дотягивания» извлеченных кусочков графа до вершины «всё». Анализируем и выводим результаты.
Нечёткий поиск в тексте и словаре
13 мин
Введение
Алгоритмы нечеткого поиска (также известного как поиск по сходству или fuzzy string search) являются основой систем проверки орфографии и полноценных поисковых систем вроде Google или Yandex. Например, такие алгоритмы используются для функций наподобие «Возможно вы имели в виду …» в тех же поисковых системах.
В этой обзорной статье я рассмотрю следующие понятия, методы и алгоритмы:
- Расстояние Левенштейна
- Расстояние Дамерау-Левенштейна
- Алгоритм Bitap с модификациями от Wu и Manber
- Алгоритм расширения выборки
- Метод N-грамм
- Хеширование по сигнатуре
- BK-деревья
Организация «чистого» завершения приложений на Go
6 мин

Здравствуйте, в данной заметке будет затронута тема организации «чистого» завершения для приложений, написанных на языке Go.
Чистым выходом я называю наличие гарантий того, что в момент завершения процесса (по сигналу или по любым иным причинам кроме system failure), будут выполнены определённые процедуры и выход будет отложен до окончания их выполнения. Далее я приведу несколько типичных примеров, расскажу о стандартном подходе, а также продемонстрирую свой пакет для упрощённого применения этого подхода в ваших программах и сервисах.
TL;DR: github.com/xlab/closer

Интеграция Symfony 2 и Google Calendar
3 мин
При создании современного веб проекта вам не обойтись без работы с внешними сервисами. Недавно у нас возникла задача по работе с календарями. В этой статье я бы хотел рассказать о некоторых моментах интеграции проекта на Symfony2 с Google Calendar.
Видео докладов с Golang Moscow
1 мин
Готовы видео докладов с митапа Golang Moscow и мы с радостью с вами ими делимся.
1. «Go в Badoo»
Антон einstein_man Поваров
1. «Go в Badoo»
Антон einstein_man Поваров