Comments 194
Доводилось в конце 1990х держать в руках железный ускоритель для просмотра видео, который цеплялся к разъему на видяшке и таки да, реально ускорял просмотр видео.
История идет по спирали, бгг.
Voodoo 3 уже самостоятельный девайс
Это было еще до пришествия вуды, и встретилось мне только один раз. Как называлось и чье было — за давностию лет не помню совсем.
Маленькая такая платка с большим чипом, которая втыкалась в штырьковый разъем на самой видеокарте, внутри, и использовалась не для игрушек а именно для видео. Видео которое на том компе едва шевелилось с этой платкой бодро игралось во весь экран.
Маленькая такая платка с большим чипом, которая втыкалась в штырьковый разъем на самой видеокарте, внутри, и использовалась не для игрушек а именно для видео.
У меня была такая, но отнюдь не маленькая, а размером с тот же Voodoo, зато была совместима со всеми видеокартами, а не только с какой-то одной конкретной. Называлась Creative Encore Dxr3.
смотрю этот ролик www.youtube.com/watch?v=ZkofUXbwGDs
если включаю 1440, то графический проц видеокарты нагружен на 30%, если 2160, то гп нагружен на 20-25 циклично уходя в ноль. ну а в 8к вообще спит. проблему с интернетом или с буферизацией не вижу, достаточно быстро грузит ютуб.
эм, у меня операционка винда 7, я так понял edge под нее нет?
Сомневаюсь, что это даст существенной рост производительности.
Разрешение видео, частота кадров, сложность кодеков растет, а производительность процессоров не особо.
Скорее нужна поддержка декодирования отдельными процессорами (видеокартой)
Смысла использовать универсальный центральный процессор для всех задач нет.
Раньше графика в играх обрабатывалась на CPU, позже пришли к использованию видеокарт.
В скринах бросается в глаза блочность традиционных кодеков, она же плодит ошибку большую чем например у MotionJPEG2000 однако снижение битрэйта всё расставляет по своим местам.
Тут кодируется 2 кадра в секунду в VGA на Nvidia Tesla V100. Я сильно подозреваю, что, если на тот же VP9 бросить такие же мощности, он сильно выиграет в качестве.
И в целом мысль wataru очень правильная — если кодеку основанному на традиционных подходах дать сравнимые вычислительные мощности для кодирования — он порвет все эти нейросети как тузик грелку по степени сжатия и/или качества картинки на выходе.
Например те же VP9 и H.265 существенно обходят по качеству и сжатию H.264/AVC практически только за счет того, что им позволено использовать в разы больше вычислений при кодировании. Благо кратно выросшие с момента появления x264 мощности железа позволили это сделать.
Стоит у современных кодеков эти дополнительные вычислительные мощности отобрать — и они сразу сдуются, практически до результатов старых кодеков. А при совсем малых допусных вычислительных возможностях — вообще могут и проиграть старым кодекам по соотношению качество/степень сжатия.

Горизонтальная шкала логарифмическая:
— горизонтальная ось = секунд на кодирование 1 кадра с одним и тем же итоговым качеством
— вертикальная = относительный битрейт чтобы обеспечить одинаковое качество
За точку отсчета взят х264 @ VerySlow пресете кодирования.
В скринах бросается в глаза блочность традиционных кодеков
Блочность там неспроста. Именно разбиение кадра на блоки малого размера даёт приемлемую вычислительную сложность и относительную гомогенность входного изображения в пределах малого блока. Отсюда хорошее приближение исходного изображения косинусными преобразованиями и методами меж- и внутри- кадрового предсказания.
Сравнение кодеков выглядит необъективным. Н.264/Н.265 построены вокруг В-кадров и заточены под метрику PSNR. Меж тем, В-кадры не использовались, а качество измеряли по метрике SSIM. Если авторам интересна именно эта метрика, то стоило добавить в сравнение кодек AV1. Желаю авторам удачи, но сомневаюсь что статью примут в серьёзный рецензируемый журнал.
Заголовок статьи, конечно, жёлтый. Как минимум, не хватает сравнения с AV1.
Верно, причём современные медиа форматы очень сильно оптимизируются также под быстрое набор инструкций потребительских ПК. Создатели существующих кодеков даже не ставили такой (непрактичной) задачи, которую поставили авторы статьи.
И я думаю, что стоит применить ML для создания кодека оптимизированного под реальный набор инструкций. Только вот эта задача уже настоящая и практическая, и даже просто среднего результата будет очень сложно добиться.
Классика жанра )))
Для начала — результаты тестирования кодеков 2017 (ПРОШЛОГО) года:
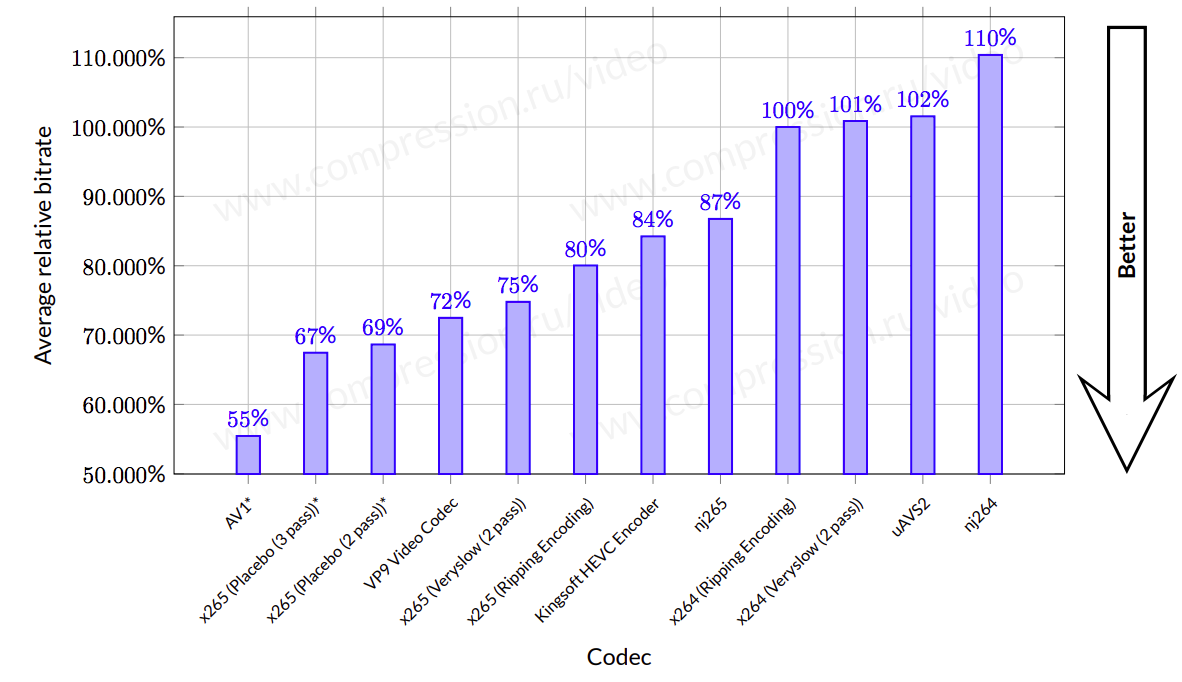
Что можно сказать про авторов:
- Для начала — они начисто проигнорировали наличие AV1, который сегодня (молитвами Google) развивается крайне быстро, причем в открытых исходных текстах! И в общем-то всех рвет (но мучительно медленный пока).
- Далее, авторы пишут: «We evaluate H.264 and H.265 in both the default preset of medium, as well as slower.» Как легко заметить на графике выше — есть еще пресеты Slow, Veryslow и Placebo, причем в последнем есть варианты с 2 и 3 проходами. И это позволяет заметно больше десятка процентов наиграть! Просто за счет выбора другого пресета!
- Ну и, наконец, забавно выглядит выбор базовой реализации для H.265. Если посмотреть на график сравнений этого года
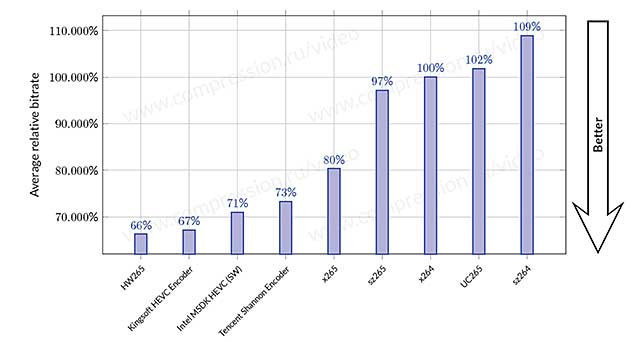 хорошо видно, что хорошая коммерческая реализация H.265 (HW265) при высокой скорости работы обгоняет по степени сжатия, сделанные на основе базовой (UC265 и sz265) В ПОЛТОРА РАЗА!!!
хорошо видно, что хорошая коммерческая реализация H.265 (HW265) при высокой скорости работы обгоняет по степени сжатия, сделанные на основе базовой (UC265 и sz265) В ПОЛТОРА РАЗА!!!
Прикол, что при этом у них волшебным образом совпали графики реализаций H.264 и H.265, т.е. кодеки, которые разделяет 13 лет развития типа работают одинаково по эффективности. Но боже, кого это смущает? )))
Секрет успеха 1: выкидываем из сравнения сегодняшнего лидера, выбираем пресеты послабее для хороших кодеков и выбираем заведомо слабую для самого сильного аналога! И, бинго, мы первые!!! )))
А есть еще и параметры, например, «To remove B-frames, we use H.264/5 with the bframes=0 option, VP9 with -auto-alt-ref 0 -lag-in-frames 0, and use the HM encoder lowdelay P main.cfg profile.» То есть они не смогли побить обычные кодеки в честном соревновании и выбрали для статьи что соревнуются только в low-latency режиме. При том что у них декодер работает 2 сек на кадр, то есть ни о каком low-latency даже близко говорить нельзя.
Тонким издевательством на этом фоне выглядят рассуждения о том, что некоторые кодеки могут заглядывать вперед (на минуточку — B-фреймы были стандартизованы еще в 1992 году в MPEG-2).
Кстати — в AV1 вполне себе используются нейросети, но точечно и по делу. Но сказать «второй кодек с машинным обучением» — согласитесь, не прозвучит ), особенно если вы решили первый проигнорировать как сильного конкурента ))))
Секрет успеха 2: Наглость, как известно города берет, а тут задача не менее сложная. Рассуждаем о том, как безнадежно устарели текущие кодеки и отключаем у них параметры, которые обеспечивают им повышение степени сжатия.
Также доставляют картинки «оптического потока» H.265 и у них. У них картинка выглядит более гладкой, значит она (конечно!) более правильная и современная ))). Есть один маленький нюанс. Эту картинку надо СЖИМАТЬ. Т.е. она должна быть компактно представлена. И (внезапно!) выясняется, что компактнее вовсе не означает красивее, тем более если речь идет о технических внутренних данных, которые никто никогда кроме разработчиков не видит! Скорее наоборот — что-то квадратное великолепно сжимается, а что-то плавное — плохо. Т.е. корректно было бы привести рядом во сколько обошлось сохранение векторов движения справа и слева, во сколько обошлась межкадровая разница справа и слева. Ну и кадры, которые получились с их значениями MS-SSIM, обязательно. После этого появляется предмет обсуждения, если там есть о чем говорить, конечно.
Секрет успеха 3: Вырываем из контекста какой-то кусок внутренних данных, который визуально выглядит красивее (как вариант — можно что-то красиво визуализировать). Показываем у нас и у них. И неважно, как оно сжимается. Люди (включая инвесторов))) реально любят красоту!
Вообще кому интересно — вот так примерно кодеки сегодня располагаются в многомерном пространстве реальных требований:

Как видно — картинка реально многомерная и для реального успеха нужно в нескольких измерениях преуспевать.
В качестве вишенки на торт — нет смысла сравнивать кадры. В кодеке (особенно если он пытается выдержать битрейт, он ведь у нас работает в low-latency режиме с ограниченным каналом, не правда ли?) заведомо идут осциляционные процессы. В таких режимах можно на примерах доказать, что MPEG-2 точно превосходит AV1. Главное взять последовательность подлиннее ))) (бонусный секрет)))
Ну и публикуется все на архиве, а не в материалах Data Compression Conference ), ведь на архиве не будут задавать неприятных вопросов до публикации! )))
Всем удачи!
www.streamingmedia.com/Articles/Editorial/Featured-Articles/At-the-Battle-of-the-Codecs-Answers-on-AV1-HEVC-and-VP9-128213.aspx?CategoryID=423
In terms of decode performance, one attendee reported that a major social media company was already distributing AV1 streams to mobile viewers with efficient playback, using decoders included in the company’s iOS and Android apps. I shared my finding that Chrome and Firefox were playing 1080p video on a single-CPU HP ZBook notebook using between 15 and 20 percent of CPU resources.
AV1 streams to mobile viewers with efficient playback, using decoders included in the company’s iOS and Android appsНо ведь в вашей цитате речь идет о декодинге видео, а не энкодинге. Мне кажется, что на картинке что-то кардинально неверно со шкалой «encoding performance», потому что у H264 эта производительность ниже, чем у AV1…
Плюс почему-то свободна low-половина у следующей шкалы, декодинга. Тогда уж AV1 нужно было поставить в low (пока мы еще в 2018), а hevc — по середине, как мне кажется, иначе ерунда какая-то выходит.
В Decoder install base VVC находится не в самом левом положении, хотя для него декодер появился, ну, пару месяцев назад, и еще не установлен ни у кого, кроме как у разработчиков этого кодека.
Я привел цитату, потому что она просто нереалистична. В цитате у человека на ноутбуке декодирование FullHD AV1 отнимает 15-20% CPU, в то время как на десктопном четырехядерном i5-4570 мой компьютер с трудом декодирует такой видеопоток чуть быстрее реалтайма (24 fps), не говоря уже о мобильных устройствах.
Суммарно там в этом году в 20-100 раз ускорение (очевидно с падением эффективности) и до конца года обещают еще:

Так что чуть позднее можно будет более предметно говорить, что в итоге получилось.
Вообще средний кодек сегодня это минимум 50 квалифицированных человеко-лет, и минимум 4 гора разработки (чаще больше) и если пригнать больше людей, результат можно только ухудшить. Поэтому остается ждать и смотреть, что получается по ходу.
AV1, как я писал выше — не просто медленный, он мучительно медленныйЗнаю, вот и удивился. Хотел его попробовать, но просто не дождался окончания процесса.
Поэтому остается ждать и смотреть, что получается по ходу.Ну я не могу сказать, что куда-то спешу, пока HEVC вполне справляется с задачами, которые я ему ставлю. С VP9 устал воевать с колорспейсами…
Что-то её не видать в интернетах нигде. Не поделитесь советом, где она могла бы водиться? :)
Давится гора квадровидюшек сутками напролёт в x265 — до 1.4Тб разрослись, никаких дискет не напасёшься!
crf 23 slower ужимает втрое, а так было б вчетверо и порезвее…
С Tencent Shannon Encoder — такая же петрушка, видимо?
А так в целом рынок отдельных кодеков в упадке, за них мало кто готов платить. Как следствие производители доходят до того, что в инсталлируемом в систему виде кодеки вообще не выпускают. В принципе их можно понять. У вас запрос на бесплатный вариант?
Тенсентовский — тоже будет в их приложении и облаке однозначно.
А за облака терабайтные платить, давящие в 265 — проще ещё один винчестер поставить.
Кстати, в вашем случае видео с квадрокоптерами скорее всего даже пресетами можно наиграть процентов 20-30. Посмотрите evt.guru, если интересно — пишите.
Ну, в моей ситуации выгоднее купить 3 винчестера по 12Тб, чем платить $1000 за пресет.
А так затея прикольная. Любопытно, как реализовано…
Исходное видео кодируется пользовательским пресетом. Режется на небольшие кусочки по ключевым кадрами. Выбирается несколько наиболее прожорливых, нарезаем их из оригинального видео. Затем методами оптимизации (градиентный спуск?) ищем минимум битрейта, пробуя соседние значения всех изменяемых параметров (штук 30-40, которыми есть смысл играться?), отслеживая время работы, итоговый битрейт и качество (метрика VMAF?).
Привет, кстати, из стримбокса :)
Ну, в моей ситуации выгоднее купить 3 винчестера по 12Тб, чем платить $1000 за пресет.Это совершенно понятно, но это и ответ, почему производители хорошие кодеки не портируют, рынок мал, типа — используйте бесплатные. )
Любопытно, как реализовано…Реализовано по-другому. Активно зарабатываем на том, что чтобы на ролике в 600 кадров попробовать все 49 параметров даже вполне быстрого x264 нужно 10 в 13 степени лет, т.е. больше 400000 возрастов земли. И чтобы сделать перебор в 49-мерном пространстве градиентный спуск вам не поможет, оно не дифференцируемо ). Подавляющее большинство компаний эту задачу не тянет, публикаций нет. В общем — вполне)
Привет, кстати, из стримбокса :)
Забавно. Сейчас там?
Текущие кодеки изначально исходят не из максимальной компрессии. А из возможной компрессии с учетом ограничений (сложности и цены) декодера (https://en.wikipedia.org/wiki/H.264/MPEG-4_AVC#Profiles). Поэтому в таких кодеках используются ассиметричные алгоритмы, такие что декодирование должно быть достаточно простым, легко параллелизуемым и локальным (что бы можно было создать специализированные чипы). Тогда как кодирование может быть в разы более трудоемким.
Остаётся надеяться только на увеличение мощности графических процессоров в будущем
Не, не будет больше увеличения мощности.
Не поняли. Здесь не вопрос в том хватит — не хватит. Конечно не хватит. Вот мне например скорости света тоже не хватает, чтобы до Андромеды летать, а что поделать?
Не поняли.
Я всё понял. А вы — не умеете в сарказм.
Вот мне например скорости света тоже не хватает, чтобы до Андромеды летать, а что поделать?
На самом деле, может быть и хватит. Вы почему-то учитываете скорость света и расстояние, но не учитываете лоренцево сокращение длины.
Я всё понял. А вы — не умеете в сарказм.
На самом деле, может быть и хватит.
Наверное сарказмы у нас разные. Мне кажется, что и вы не так умелы. :P
Я вас не минусовал. И вообще я очень, очень редко минусую кого нибудь. И никогда как ответ на шутку или иронию.
/комментарии_на_хабре_порою_интересней_поста
Согласен. Просто johnfound тонко шутит и не всем понятно.
А шутку я объясню:
кодеки разрабатываются для существующих наборов вычислительных инструкций, чтобы у всех быстро проигрывалось на реальных машинах. Авторы статьи такой задачи вообще не ставят. И в результате сделали кодек в сотни раз медленнее. Зато оптимизировали какой-то другой параметр на 20%.
А в конце статьи пишут
Остаётся надеяться только на увеличение мощности графических процессоров в будущем
Своим ответом
Не, не будет больше увеличения мощности.
johnfound как бы намекает, что надо делать кодек для тех вычислительных устройств которые есть сейчас.
Ну, так глубоко я не думаю и тем более не намекаю. Но понравилось.
… надо делать кодек для тех вычислительных устройств которые есть сейчас.
А вот это надо на камне вытесать и поставить на вход факультетов ИТ:
«Пиши программы для существующих компютеров, ибо в будущем смотреть тебе не дано!»
А авторы очевидно расчитывают на экспоненциальный рост производительности в будущем. А вот его и вправда уже нет и не будет в будущем. Было, да сплыло. Недолго музыка играла… Ну и так далее. :D
К тому же, как и другие наверх отметили, для видеокодека важно не только чтобы компрессия была выше. Дешевая декомпрессия, не побоюсь сказать, намного важнее. А с этом у авторов прямо беда какая-то — дешевая декомпрессия даже и не предвидится.
авторы очевидно расчитывают на экспоненциальный рост производительности в будущем. А вот его и вправда уже нет и не будетРаскрывайте карты. На чём основан прогноз? Лопнет экономический пузырь и у людей денег не будет на 11-й айфон или упрёмся в техпроцесс и тепловыделение или скорость деградации софта перевесит скорость деления ядер процессоров?
Это не прогноз. Это простое наблюдение. Экспоненциального роста уже нет. И давно. Не заметили что ли? Производительность увеличивается в лучшем случае полиномиально. И степень полинома (мне кажется) не намного больше единицы.
А скорость деградации ПО не падает, увы.
А что касается софта — в целом, особых проблем с плеерами я не заметил, производительность там не падает. В браузерах да, картина иная…
Сейчас как раз увеличением их количества и занимаются
Но не экспоненциально же! А это важно и меняет все!
А кстати, люди смотрят видео не на серверах и даже не на десктопах, а на телефонах.
А кстати, люди смотрят видео не на серверах и даже не на десктопах, а на телефонах.Да, есть такая проблема. Ну на телефонах можно ждать только AV1, никаких других (дельных) кодеков там не появится в ближайшие десять лет. Если, конечно, не произойдет какая-нибудь революция в сфере.
лоренцево сокращение длины.
И какой будет год на Земле, когда вернется с Андромеды?
Чтобы что?
Одного QR-кода со ссылкой на Pastebin мало что ли?
Ну как бы показать супер сжатие и декодирование на системе со нвидией тесла и жалкие 10 кадров в секунду — немного далековато от кодека пользовательского уровня. При таких широких лимитах нет смысла сравнивать кодеки, которые обязаны как минимум декодировать в реальном времени.
Так уж и до Pi сжатия можно добраться — есть определенная вероятность найти любой фрагмент чисел внутри числа Пи, так что можно просто хранить смещение и длину в качестве указателя на данные произвольного состава. Проблема только в расчете числа Пи до нужного количества знаков.
0.001 кадр в секунду будет на среднем офисном Intel i3 без чего бы то ни было лишнего?
так что можно просто хранить смещение и длину в качестве указателя на данные произвольного состава. Проблема только в расчете числа Пи до нужного количества знаков.
Проблема как раз таки в хранении смещения, не факт что оно окажется короче чем сами данные.
Ну как бы показать супер сжатие и декодирование на системе со нвидией тесла и жалкие 10 кадров в секунду — немного далековато от кодека пользовательского уровня.
А с чего вы взяли что это кодек пользовательского уровня? Это всего лишь научная работа на тему которая уже лет 10 как витает в воздухе.
Чтобы это стало научной работой:
1) надо сделать кодек в существующие выч. наборы инструкций
2) делать оценку качества кодека на кросс-валидации, а не на тренировочных данных.
надо сделать кодек в существующие выч. наборы инструкцийЭто какое-то особое требование научности? Они сделали на несуществующих выч инструкциях?
делать оценку качества кодека на кросс-валидации, а не на тренировочных данных.Оценка качества кодеков производилась на тестовом наборе:
We benchmark all the above codecs onлогично наверное использовать то что используется в индустрии для бенчмаркинга кодеков?
standard video test sets in SD and HD, frequently used for
evaluation of video coding algorithms. In SD, we evaluate
on a VGA resolution dataset from the Consumer Digital
Video Library (CDVL)1
. This dataset has 34 videos with a
total of 15,650 frames. In HD, we use the Xiph 1080p video
dataset2
, with 22 videos and 11,680 frames. We center-crop
all 1080p videos to height 1024 (for now, our approach requires
each dimension to be divisible by 32)
Для обучения использовались видео с ютуба:
Training data. Our training set comprises high-definition
action scenes downloaded from YouTube. We found these
work well due to their relatively undistorted nature, and
higher coding complexity. We train our model on 128×128
video crops sampled uniformly spatiotemporally, filtering
out clips which include scene cuts
Алексей, залогиньтесь!
Научно-фантастический роман Карла Сагана "Контакт" скорей вспоминал, там вокруг послания внеземного разума внутри числа Pi строился кусок сюжета :)
А для алгоритмов сжатия без ошибок это всегда так.
Рассмотрим всевозможные последовательности длины N. И алгоритм архивации A(x), преобразующий последовательность длины N в некую другую последовательность. Выходные последовательности могут быть разной длины.
Исходное множество (набор всевозможных последовательностей длины N) использует N*(n^N) знакомест, где n — число символов в алфавите. Из общих соображений ясно, что архивированное множество будет содержать никак не менее N*(n^N) знакомест. Могу доказать строго, если надо.
Иными словами, любой алгоритм часть данных переведёт в более короткие последовательности ("сжав" их), а часть — в более длинные ("надув" их). Искусство состоит в том, чтобы в каком-то смысле "полезные"/"хорошие" последовательности попали в "сжимающую" часть, а "бесполезные"/"мусорные" последовательности — в "раздувающую". Поэтому, например, обычная телевизионная "статика" обычно не сжимается, а наоборот, делается больше.
Ясно, что чем уже "сжимающая" область, тем лучшее сжатие будет в ней достигаться.
Архиватор, основанный на числе Пи, просто имеет неудачную область сжатия. Данные, которые мы обычно считаем полезными (типа картинок, музыки и проч), будут почти всегда попадать в "раздувающую" часть.
Зато само число Пи можно будет закодировать всего несколькими битами (а в пределе — всего одним)! Притом что само число Пи бесконечно, получается, что за счёт сверхузкости "сжимающего" диапазона, получается буквально бесконечная степень сжатия.
Я считал 1080p тоже стандартным размером
То есть если раньше кодеки могли просто мылить картинку (выдавая это за качество), то тут высокочастотная информация вначале заменяется на нечто «похожее», но низкочастотное, а потом уже кодируется и мылится.
Не хотел бы я смотреть на мыло, хоть и в 8K.
Не знаю, где вы там замены нашли, на мой взгляд все совпадает
А такая штука может их придумать, нарисовать, вплоть до всех ворсинок.
Логично. Тогда можно и утку не снимать — пусть сам нарисует. а в видео все будет из маркеров — утка, человек, кусок булки — вообще в три байта уложится. Сценарий же типовой «кормление утки».
был такой анекдот про давних попутчиков — что анеки друг другу просто номером рассказывали. «1024!» — и все ржут. Вот это будет супер кодек.
PS. нам на ютубе в общем пофиг что утка, что лицо человека неизвестного. Можно заменять смело, включая ворсинки. ЧЧеерт, так и до новостей дойдет — представьте умный кодек дает 100500% на новостях! Палесы носят убиеннного на руках, нефть поднялась арабы вшоке, мы против войны, дом222 — знакомые все лица (сценарий типовой, 2й после утки).
Но вообще да. Лучше уж смотреть на мыло, чем «на пупки вместо глаз», поскольку «нейросети показалось, что это пупки».
- Было бы неплохо добавить оригинальное изображение, чтобы понять насколько сжатые изображения передают детали.
- По поводу скорости работы кодеков ИМХО это весьма незначительная проблема. В следующем году подтянутся аппаратные ускорители на ПЛИС, которые позволят в десятки раз повысить скорость работы нейросетей по сравнению с GPU и тогда это не будет преградой.
Дык вроде была уже статья здесь про японское порно, где такие "артефакты" успешно дорисовывают то, что заботливо вырезано цензурой. :-)
i.gifer.com/2qzN.gif
{kind=link}
Вот вы правильную идею выхватили — будут просто электроды в мозг подавать сигнал удовольствия, а там хоть ковёр смотри.
Вы сейчас описали кодер "Сценарист" и декодер "Воображение"
И поэтому они создали «новейший» формат, доступный только для компьютеров будущего (возможно).
(с) Рэй Бредбери «Марсианские хроники»
кодек ищет движущиеся объекты и пытается предсказать, где они будут в следующем кадре.А зачем предсказывать? Почему бы кодеку при кодировании, не «просмотреть» на несколько кадров вперёд и вместо предсказания движения (которого может и не быть, или быть но в другую сторону) зафиксировать то, которое есть на самом деле и именно это движение закодировать.
Или играть в угадайку интереснее?
Действительно, некоторые алгоритмы смотрят на будущие кадры, чтобы определить движение ещё более точно, хотя это явно не сможет работать для прямых трансляций.
Хотят тут огромной вопрос что проще и дешевле — доставить памяти (которая растет и дешевеет на глазах) и увеличить скорость Интернета (5G на подходе) или разработать достаточно мощный процессор для декодирования видео.
Кроме того, кодирование H.264/H.265/VP9 проводилось со скоростными профилями medium и slower, в то время как более медленные профили дали бы качество выше, за счет более долгого кодирования (требуемая вычислительная мощность для декодирования изменилась бы незначительно). Их кодек выдает 10 кадров в секунду на VGA-видео (640×480) при декодировании на nVidia Tesla V100 — самой быстрой в мире видеокарте, заточенной специально под сложные вычисления (самая дешевая модель стоит 500000₽), могли бы уж хоть сравнивать с максимально возможным качеством альтернативных кодеков.
Короче, сравнение не то чтобы некорректное, но нужно понимать детали, иначе журналисты опять всех изнасилуют.
Пример с утками какой-то странный, будто использовали фильтр типа warpsharp. У H.264 деталей заметно больше.
Да, на битрейте скажем в 0.5 бит/пиксель и выше он конечно жмет существенно лучше (дает выше качество при том же потоке сжатых данных либо позволяет сократить поток при том же качестве). Вот только никто такие битрейты на практике сейчас не использует (а если иногда в виде исключения и использует — то с качеством тогда и так все очень хорошо, на глаз оно просто отличное — лучше уже просто некуда, отличия от несжатого оригинала там надо на компьютере выискивать и высчитывать, а на глаз при просмотре разница уже не заметна).
0.5 бит/пиксель это потоки:
31 Мбит/с для стандартного FHD видео
62 Мбит/с для FHD@60fps
125 Мбит/с для 4К
250 Мбит/с для 4К@60fps
+ поток со звуком сверху к этому
На практике сейчас для современных кодеков используются потоки примерно от 0.05 до 0.25 бит/пиксель, очень редко больше. Ютуб вообще частенько издевается и до 0.03-0.04 бит/пиксель ужимает.
А на таких потоках у кодека нет вообще нет никаких преимуществ, одни недостатки: хорошо еще если традиционным кодекам работающим в десятки раз быстрее не проиграет по качеству/сжатию:
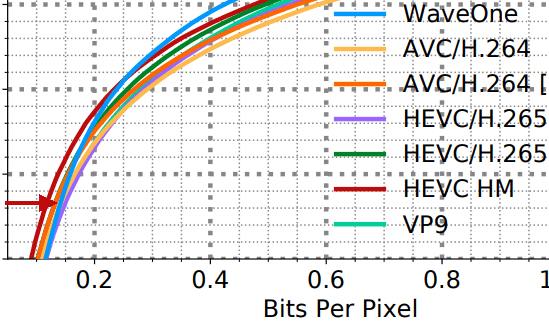
(стрелочка на ~0.14 бит/пиксель, это например 2х часовой фильм в FHD будет весом в 8-9 ГБ)
А на потоках ниже 0.1 бит/пиксель — проиграет точно и по качеству и по скорости одновременно. Так что комментаторы выше которым не понравилась «размазня вместо утки» правы. При таких битрейтах (пример с утками 0.057 бит/пиксель) — качество хуже не только субъективно, но и объективно (при попиксельном сравнении с несжатым оригиналом и вычислении разницы).
31 Мбит/с для стандартного FHD видеоНа Ютубе где-то в 2-3 раза меньше, фильмы «в хорошем качестве» можно скачать с трекеров с таким битрейтом, гигов 30-40 выйдет. (H.264)
125 Мбит/с для 4КНа Ютубе в 4 раза меньше, у фильмов — в 1.5-2. (H.265)
Так что для FHD смысл еще может иметь, для фильмов, но сомневаюсь, что у консьюмерского железа хватит мощности. Плюс, если уж кодировать с такой скоростью, то у того же HEVC можно очень много настроек поменять, а не пользоваться стандартным профилем — и сильно обогнать это машинное обучение.
Вот для примера взял достаточно качественное (по меркам Ютуба) HD видео: www.youtube.com/watch?v=Bey4XXJAqS8
Кодек VP9 для видео/Opus для звука (хотя может отличаться от машины и браузера — у ютуба неск. разных версий даже для одного разрешения хранится у меня в FireFox подгрузился вариант сжатый VP9)
Померил — в FHD@30fps средний поток около 300 КБ/с (2.6 Мбит/с) причем это уже вместе со звуком.
в 4К — около 1500 КБ/с (12 Мбит/с)
Или порядка 0.04 бита на пиксель видеоизображения в обоих случаях.
Тут в статье такие битрейты даже не показали (графики обрезали снизу, начинаются где-то от 0.1 бит/пиксель только), т.к. в этом случае новый кодек проигрывает в хлам даже самым старым кодекам типа AVC(H264) и по качеству картинки и по степени сжатия(битрейту/занимаемому месту), не говоря уже и проигрыше в сотни раз по скорости/используемым выч. ресурсам.
Да ладно, у вас какой-то собственный особый Ютуб? Потому как на обычном Ютубе не 2-3 раза, а раз в 10 меньше битрейты используются.И действительно, аж барские 2 МБит\с. Я ориентировался на рекомендации гугла, с какими характеристиками видео заливать.
Format : WebM
Format version : Version 4 / Version 2
File size : 415 MiB
Duration : 29mn 36s
Overall bit rate : 1 958 Kbps
Writing application : google/video-file
Writing library : google/video-file
Video
ID : 1
Format : V_VP9
Codec ID : V_VP9
Duration : 29mn 36s
Bit rate : 1 873 Kbps
Width : 1 920 pixels
Height : 1 080 pixels
Display aspect ratio : 16:9
Frame rate : 29.970 fps
Bits/(Pixel*Frame) : 0.030
Stream size : 397 MiB (96%)
Language : English
Default : Yes
Forced : NoВ AVC/H264 кодеке (поток отдаваемых для клиентов не поддерживающих VP9) поток на том же видео где-то процентов на 15-20% повыше, чтобы компенсировать меньшую эффективность сжатия и получить на выходе примерно то же визуальное качество (хотя ИМХО AVC у гугла выглядит всегда хуже чем VP9, речь причем не о детализации и артефактах, у них что-то с цветопередачей — AVC какие-то более блеклые получаются).
Так лучше, если пользователь на своей стороне будет использовать самую минимальную степень сжатия. Идеально было бы конечно, вообще не сжатое заливать, но объемы и трафик в этом случае просто гигантские будут. А с указанными рекомендованными параметрами, выставленными с большим запасом это весьма близко к loss-less сжатию получается при еще вменяемых объемах и трафике.
Благодаря этому влияние подобной двойной конвертации незаметно за счет того что 2я конвертация идет с заведомо (в разы) большей степенью сжатия — тогда потерями на 1й стадии можно пренебречь. А вот если пользователь будет сразу стараться попасть примерно в тот поток, что использует Гугл — итоговое качество после 2х конвертаций окажется заметно хуже.
и получается что-то типа такого(на примере этого же видео):Да, я уже посмотрел выдачу mediainfo, правда она далеко не полная — неизвестны дополнительные параметры, вроде alt-frames и прочего. Интересно было бы посмотреть.
Что касается пережатия — тут проблемы будут всегда, качество в любом случае упадет, если не пытаться это фильтрами поправить\предотвратить. Но минимизировать можно, да.
Дешевле винчестер купить, чем за электричество для такого кодирования и декодирования платить.
Наверное вы хотели сказать про более дорогой интернет тариф.
А еще у меня есть Kindle, но также полный шкаф книжек и абонемент в библиотеку.
Что вас в этом удивляет?
Пару лет назад смотрел видео с этого канала на Ютубе.
17 октября полтора часа Ютуб не работал по всему миру.
Всякое случается, по самым разным причинам.
Дело в том, что поддержка HEVC исправляется расширением набора инструкций. А вот сильно ускорить машинное обучение — это большая проблема. Нужно увеличивать количество ядер.
через 2-3 года наверняка появится железная поддержка, какой-нибудь ускоритель машинного обучение
Этот кодек в 100 раз медленнее допустимого. В 100 раз увеличить количество ядер? Именно для этого кодека?
Окей, я помножил разрешение первого попавшегося видео с компа (1280x692 * 24 fps) и получил гигантскую экономию в 8500 байт/секунду.
Конечно затраченная на кодирование электроэнергия безусловно стоит экономии этих 8500 байт. [сарказм]
Нет, я не против развития технологий, но всерьез рассчитывать, что кодирование и декодирование видео переведут на этот новый кодек повсеместно я бы не стал. Ни в ближайшие два года, ни в ближайшие десять лет. Накладные расходы делают эту технологию совершенно нерентабельной. Даже для гиков.
Это их прошлый кодек для изображений (но возможно не их реализация).
Сейчас даже видео с ютуба загружает Core i7 по самые помидоры.
Предсказуемость истории удручает. Дальнейшая цифровизация кино в исполнении ИИ это лишь очередной шаг в сторону отмены как такового вида искусства. Очень скоро станет очевидно, что не надо больше снимать кино, а надо делать геймификацию. Всё придёт к ролевым постановкам с накладкой лиц, габаритов и прочих характеристик актеров на заданную сюжетную линию. Можно будет посмотреть один и тот же фильм в исполнении разных актёров, не меняя всего остального. Но будет ли уже это искусство?! И будет ли оно достаточно качественным?!
То что проблемы будут — не сомневайтесь:
Такое уже проходили с копировальными аппаратами
habr.com/post/189010
Может быть даже кто-то и посмеется, когда алгоритм ошибётся и автоматически заменит Сашу Грей на Джастина Бибера. Но может пора уже начать думать в том ли направлении движется человечество подтягивая ИИ туда, где ему нет места.
декодирующий поток мал, даёт возможность прерывать его, на определенном уровне детализации, и работает сразу со всем полем изображения, в отличии от остальных методов.
Но вот кодирование, тут математики столько, что таки да, hd видео делать не стоит производить.
ИМХО с тем же успехом можно было сделать сглаживание картинки перед сжатием. Потом посжимать классическими кодеками. Какая разница, как терять детали?
Первый видеокодек на машинном обучении кардинально превзошёл все существующие кодеки, в том числе H.265 и VP9