Comments 757
Почему не могут, если делают?В приведенных вами тестах не участвуют десктопные x86.
ни у интела, ни у амд, не будет больших проблем использовать его в своих x86-совместимых процессорах
И да, и нет. И да, потому что концептуально можно положить ARM ядро и назвать этот процессор Intel Core или там Ryzen. Более того, AMD в начале 10х экспериментировала с выпуском ARM процессоров.
С другой стороны, разработка ядер CPU и процессоров на их базе — основной бизнес Intel и бОльшая часть бизнеса AMD. Если они начнут эти ядра у кого-то покупать (а Apple, на сколько я понимаю, все таки разрабатывает сама и ядра, и процессор, а не покупает их на стороне, как делают многие производители мобильных чипов), то это будет означать фактическую смерть обоих компаний, так как основную ценность и главную компетенцию они потеряют.
Кроме этого, если у них нет туза в рукаве на базе «таких хороших ядер» на ARM (а у Intel его судя по всему нет) — разрабатывать его с ноля займет годы. И проблемы с техпроцессом. Кроме того, в случае с Intel и их собственными уникальными фабриками, придется еще и перепроектировать все это под собственно их фабрики, что тоже займет долгое время, т.к. нельзя просто взять условную пачку документаций и спецификаций с фабрики TSMC и начать делать то же самое на фабрике от Intel или от Samsung. Даже на одном и том же условном «10нм» техпроцессе техпроцесс у каждого производителя отличается и чип надо под него перепроектировать.
В общем — все на самом деле очень непросто.
повернуть в сторону и разработать нечто похожее для них большой проблемой не будет.
Будет. Intel вот пыталась пару лет назад и в модемы, и в процессоры мобильные. Слилась, не смогла.
Если бы могли — сделали бы. Intel/AMD и любая другая подобная компания каждый год миллиарды долларов в RnD закапывают. Пока в ARM и подобные показатели производительности у них даже близко не получилось.
А на счет покупать — во-первых могут и не продать, во-вторых — все, что доступно к свободной покупке не блещет показателями. Так то да, вон готовые Cortex ядра продаются.
Весь грешный инжиниринг делается купленными на стороне руками и головами.
Вот только процессоры они разрабатывают in house. Даже компанию для этого купили в начале нулевых, специализирующуюся на разработке процессоров. Там не только маркетологи работают все таки, с времен создания первого айфона поменялось достаточно много. Ну и контрактников конечно никто не отменял, они есть у любой крупной компани.
Кто мешает тому же интелу, если прям так сильно пахнет жаренным, точно так же перекупить тех, что умеет делать лучшие ядра?
А нет их доступных к покупке. А если представить такую ситуацию, что есть абстрактная команда, которая офигенно пилит новые ядра на ARM и она вдруг осталась без контрактов и решила продаться, то Intel может оказаться бедновата для получения над ней контроля. У Apple денег даже в кэше 75 миллиардов против 16 у Intel.
это ARM, а не что-то неведомо-новое, т.е. его архитектура прекрасно известна и доступна всем желающим.
Так и x86_64 всем известен и доступен всем желающим по лицензии. Проблем нет. Вот только архитектура != ядро или процессор под нее. Разница примерно как между алфавитом определенного языка и его грамматикой и написанной с помощью этого алфавита на этом языке книгой.
Знание языка необходимо, но совершенно недостаточно для того, чтобы написать книгу. Ну то есть что-то конечно можно изобразить, но до бестселлера этому произведению будет далековато.
Будет. Intel вот пыталась пару лет назад и в модемы, и в процессоры мобильные. Слилась, не смогла.
Не "пару лет", а побольше. И ушла не потому, что "не смогла", а потому, что эти рынки — низкомаржинальные. Затрат много, конкуренция высокая, прибыли (относительно десктопных и серверных процессоров) — низкие.
Реальная очевидная проблема у Интела сейчас одна — они впервые за очень долгое время потеряли лидерство в техпроцессе, и никак не могут его наладить. На этом фоне рассуждать о том, что у Эппла или АМД архитектура лучше, а Интел якобы "не смог" — занятие так себе.
Интеловская 64 разрядная технология (IA-64) вообще не взлетела.
Впрочем, ограниченную распространённость получила и до сих пор используется, но как раз наступает EOL.
Если уж HP и Intel, потратив огромное количество ресурсов на разработку технологии, решили от неё отказаться, значит есть другие варианты.
Я думаю, что выбор x86 <-> ARM был в другом — Apple уже давненько сама разрабатывает процессоры для своих телефонов и увидела, что это у неё успешно получается + провела моделирование быстродействия для десктопных задач. Результаты её устроили и поэтому она решила перевести на них Маки.
Купить болванку. А сделать ее быстрой, если дело только в наборе команд, должны суметь, иначе грош им цена.
Так дело же совершенно НЕ в наборе команд. Дело в том, как реализовано выполнение этих команд.
Вот про это я и говорю.
Поглощения компаний ради готовых компетенций — нормальный путь развития крупного бизнеса. В этом нет ничего удивительного. Посмотрите сколько компаний поглатила та же Intel — newsroom.intel.com/tag/acquisition/#gs.l7gq90
Большая часть из них была про микроэлектронику. Получается там тоже одни маркетологи сидят?
Apple даже светоча своего Джобса умудрилась просрать в свое время, опыт есть.
Причем тут конкретный человек и компания?
Конечно, но раз apple не стала пилить свой x86, а пошла на кардинальную смену набора команд и выбрала arm, значит архитектура решает, не так ли?
Нет, не так. Apple была в соучеридителях ARM, много лет разрабатывала мобильные процессоры на этой архитектуре и теперь пришла в другой сегмент. Они же не вчера этим занялись. Как раз те самые компетенции. Всмысле они научились очень хорошо работать в рамках этой архитектуры. Вероятно даже лучше, чем AMD/Intel в рамках своей х86 и лучше, чем Qualcomm в рамках той же ARM. Если бы дело было только в архитектуре, Qualcomm, Samsung, Huawei и еще пара десятков компаний помельче давно бы пришели и нагнули парочку Intel/AMD.
Известно, что лицензией на архитектуру Arm64, на которой построены все современные ARM процессоры (то есть возможность заглянуть вообще везде и во все детали и крутить ее как надо, а не купить готовые ядра в формате black box), есть как минимум у Apple, Samsung, Applied Micro, Broadcomm, AMD(да да), Cavium, Huawei, Nvidia.
У Intel есть лицензия на Arm32, есть ли она на Arm64 неизвестно, по крайней мере в открытых источниках я не нашел, но у них в линейке есть процессор Intel Movidius, а он на Arm64. Возможно ядра лицензированы, подробностей о нем мало. Процессор этой линейки ставился в Intel Neural Compute Stick.
Вообще, ARM как системе команд уже хрен знает сколько лет. Весь мобильный рынок на ней. Кое-кто экспериментирует с разработкой процессоров для более серьезных задач (Amazon, к примеру). Но это все совершенно не значит что интел или кто-то еще может пойти, взять эту систему команд и что-то внятное на ней изобразить. Архитектура достаточно удачная сама по себе, да. Но есть и другие, и даже открытые (OpenRISC). Что-то никому это особо не помогает делать какие-то особо быстрые и эффективные процессоры. Равно как и многолетняя разработка процессоров на ARM не помогает той же Qualcomm сделать такой-же быстрый и эффективный процессор, как M1.
Так дело же совершенно НЕ в наборе команд. Дело в том, как реализовано выполнение этих команд.
Дело в наборе команд. RISC при прочих равных всегда уделает CISC. Собственно и у Интела CISC уже давно аппаратно эмулируется поверх RISC‐ядра. Убираем слой эмуляции — получаем более холодные камни с большими возможностями для оптимиации компилятором.
youtu.be/1kQUXpZpLXI?t=782
Убираем слой эмуляции — получаем более холодные камни с большими возможностями для оптимиации компилятором.
Мсье теоретик? Где все эти "более холодные камни с большими возможностями по оптимизации" были, пока Интел по техпроцессам не отставал? :) x86 за время своего существования повыбивал самые разные "более эффективные" RISC-процессоры из разных ниш, так что объективная реальность несколько отличается от "сделаем без эмуляции — получим преимущество".
Где все эти «более холодные камни с большими возможностями по оптимизации» были, пока Интел по техпроцессам не отставал?
В телефонах и планшетах.
x86 за время своего существования повыбивал самые разные «более эффективные» RISC-процессоры из разных ниш
При этом с худшим техпроцессом чисто из‐за преимуществ x86 архитектуры, наверное. (нет)
В телефонах и планшетах.
Вы ещё стиральные машины забыли. Ещё раз — рынок мобильных процессоров, в отличие от рынка настольных и особенно серверных, низкомаржинальный. Есть некоторая разница между "проиграли технологически" и "не захотели сильно вкладываться из-за низкой нормы прибыли".
При этом с худшим техпроцессом чисто из‐за преимуществ x86 архитектуры, наверное.
Разумеется, нет, потому что внешняя архитектура команд с определенного момента вообще перестала играть существенную роль в производительности. О чем я вам и говорю.
Не настолько. В CISC-декодер сложнее вносить изменения и он имеет больше пространства для нежелательных сайд-эффектов в силу сложности, но транзисторного бюджета и TDP он в товарных количествах не потребляет.
А вот то, что у него L1I 192kB и L1D 128kB и 12 MB shared L2 — вносит огромный вклад в производительность.
Тот же АЛУ может какое‐то время не использоваться, и статическая память кеша не потребляет, пока в ней не меняются данные, а вот декодер должен отработать на каждом такте.
Но даже если модифицировать схему: убираем CISC‐декодер → снижаем сложность и избавляемся от сайд‐эффектов → упрощаем внесение изменений → делаем более производительный процессор.
Всё равно получается, что и таким образом архитектура набора команд играет существенную роль в производительности.
У них, как бы, довольно долго вполне получалось.
Тот же Haswell/Broadwell были крайне удачны.
Да и нельзя забывать, что M1 пока не поступили в массово в реальную эксплуатацию, и еще не понятно, какие у них по факту узкие места. Тот же RPi 4 на десктопе — не очень торт, а потребляет наравне с Atom.
Убрать декодер нельзя, ибо совместимость. Можно только добавить еще регистров и завести отдельный набор команд — но это новшество не будет востебовано еще долго и пока оно не будет востребовано, его обслуживание будет стоит транзисторного бюджета и tdp (даже если его немного совсем) которые можно было бы расходовать иначе.
Например, на раширение L1.
Так что это очень сложный вопрос даже на взгляд непрофессионала.
И это было бы замечательно, потому что можно делать очень быстрые n‐МОП транзисторы на германии, но из‐за высокого потребления в статике сверхобольшие интегральные схемы n‐МОП увы невозможны.
Декодер работает на каждом такте, если процессор что‐то делает. А вот АЛУ уже нужны не всегда. Регистры тоже простаивают, пока в них лежат промежуточные данные вычеслений. Кеш ещё реже работает.
Поэтому и тротлинг работает — уменьшение частоты существенно снижает энергопотребление.
А я говорю, что играет. Убираем CISC‐декодер, работающий на каждом такте → снижаем TDP
А вы не говорите, а маленький расчет сделайте — какую часть чипа занимает декодер и сколько потребляет энергии в сравнении с остальным. Вот тогда будет что-то похожее на предметный разговор.
Но тогда почему у Intel не получилось в мобильные процессоры
Я вам уже ответил, но вы проигнорировали — причины маркетинговые, а не технические. С технической точки зрения там всё прекрасно получалось.
А вы не говорите, а маленький расчет сделайте — какую часть чипа занимает декодер и сколько потребляет энергии в сравнении с остальным. Вот тогда будет что-то похожее на предметный разговор.
При этом вы почему‐то такой маленький расчёт не сделали, который показал бы, что не влияет.
Так что может влияет, а может и не влияет, но есть ещё одна гипотеза, по которой RISC позволяет сделать более производительные процессоры: habr.com/ru/post/528658/?reply_to=22333998#comment_22333328
Сколько вклад каждой из них посчитать, конечно, возможно, но у меня ресурсов для этого, к сожалению, недостаточно.
Конечно, но раз apple не стала пилить свой x86, а пошла на кардинальную смену набора команд и выбрала arm, значит архитектура решает, не так ли?
Apple делает ARM процессоры уже 17-лет, причем последние 10 лет на собственной микроархитектуре, так что ни на какую смену набора команд она не шла.
Весь грешный инжиниринг делается купленными на стороне руками и головами.
Простите, сотрудникам интел не платят, или что означает «купленными на стороне»?
повернуть в сторону и разработать нечто похожее для них большой проблемой не будетВы вообще представляете себе цикл разработки процессора с нуля? Вы понимаете, что от первых идей до релиза проходит 3-5 лет (в свете чего, кстати, хардварные косяки иногда исправляются через 1-2 поколения, а не сразу, ибо банально нельзя «повернуть в сторону» посреди процесса, не потеряв миллионы долларов, если не десятки-сотни оных), которые конкуренты на жопе не сидят, а тоже что-то делают? И это на знакомой архитектуре.
Нельзя просто взять и пересадить инженеров-хардварщиков, которые собаку съели на интеловском х86, на АРМ, и сказать «сделайте конфетку». Это так не работает. Это другие компетенции. Из тракториста не получится сразу сделать гонщика Формулы-1.
ARM продает много всего. В том числе лицензии на набор команд и на архитектуру.
Тае вот. Ни Apple ни Qualcomm не покупали ядра. Они купили лицензии на архитектуру и разработали свои ядра.
Использование RISC архитектуры набора команд процессора раздувает код программы до совершенно избыточных размеров
Это больше похоже на VLIW… где-то попадалась сравнительная диаграмма плотности кода: она для ARM/x86_64/RV64 примерно одинакова, но RISC, как правило, имеет компактную версию.
Ссылка на статью
Если, конечно, не брать за образец MIPS или Freescale.
Собственно, непонятно как
Использование RISC архитектуры набора команд процессора раздувает код программы до совершенно избыточных размеров
Армы да, имея RISC-основу они взяли некоторые черты CISC.
На практике в RISC реализуются разные сокращенные подмножества, а для CISC такое невозможно, так как он уже состоит из подмножеств. Причем, оптимальность изначальной нарезки бит в инструкциях определяет сложность дальнейшего расширения. А самое главное, нельзя просто взять и выкинуть некоторое подмножество (на самом деле иногда можно, но чтобы выкинуть что-то бесполезное сначала надо ввести что-то бесполезное, как было с командами мониторинга в Pentium, емнип, эволюционировавшими в префиксы AMD64).
Отчего CISC обречен пухнуть, а RISC — быть гибким и уменьшаться.
сокращенные подмножества
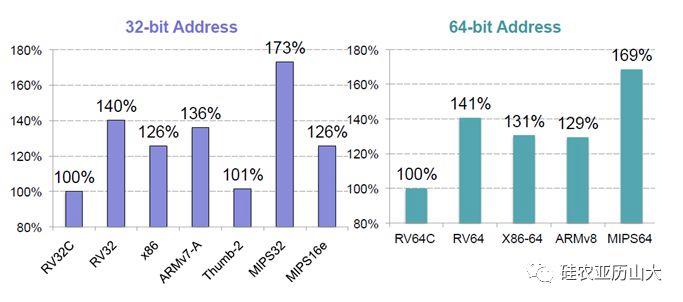
Thumb, Thumb-2, RV64C, RV32C — вот это вот все.
почему выкинуть что-либо из CISC проблемнее чем из RISC
Ну вот смотрите: пилите вы свой идеальный передовой 16-битный процессор.
- У вас есть некоторое количество базовых операций которые вам надо выполнять наиболее часть: загрузка, сложение/вычитание, сдвиг, условный переход, ротация возврат. Вы хотите сделать их как можно короче, одно байтовыми.
Кроме этого, у вас еще может быть i8/i16 операнд и косвенная адресация — все это должно влезть в инструкцию. А еще надо адресовать регистровый файл. Допустим, он будет состоять из 32 байтовых GPR, которые объединяются попарно для 16-битных операций.
CISC:
Адресуя 32 регистра пятью битами, вы можете реализовать всего 2³=8 команд. Сложение, вычитание и сдвиг вправо и влево в знаковом и беззнаковом вариантах, ротация и условный переход — это уже 10!
Ок, режем количество GPR до 8, освободим аж два бита для команд, потребуется всего три бита для кодирования регистра и можно сделать больше коротких однобайтовых инструкций. Теперь вы реализовали загрузки и сохранение и у вас есть даже задел на будущее в виде еще 16 (для простоты счета) свободных опкодов — круто!
При этом короткие инструкции всегда неявно подразумевают работу с R0/R1R0.
RISC:
Ок, используем два байта для команды. Адресуем Op0 и Op1 младшими 10 бит для команд, требующих два операнда, для остальных используем Op1 как расширение опкода. Immed-операнд размещается следом за командой, расширеный до 16 бит.
16-тибитные команды состоят из флага в 15 бите, 7 бит опкода (даже больше, чем у 8-мибитных) и двух нибблов для Op0 и Op1.
Результат:
Пока что системы команд обоих архитектур достаточно близки, и декодируются простой таблицей.
Какие смешные эти RISC, они на любую инструкцию тратят на байт, а то и три, больше! А ведь его из памяти прочитать еще надо!
- Добавляем косвенный переход и индексную адресацию.
CISC
Оукей, у нас в условном переходе используется 4 бита под номер флажка, двойных регистров у нас всего 4 — это всего 8 опкодов.
Черт, нам бы еще пару индексных регистров, а то ворочать массивы будет очень тормозно! Добавим еще опкоды… для всех операций, только теперь индексные… Нам нехватает опкодов — вводим двухбайтовую кодировку, пусть все опкоды 0xCx будут префиксами!
RISC
Вводит два новых опкода в 16-тибитную часть.
Результат
CISC: ладно, я все равно местами быстрее.
- Добавляется FPU…
CISC
Так, ребята помните, какая жопа у нас случилась в прошлый раз? Давайте теперь не будем маяться дурью и сразу сделаем команды для FPU — префиксными.
RISC
Добавляет еще несколько опкодов.
Результат
На 8-мибитной шине CISC показывает небольшое преимущество, на 16-бит они идут ноздря в ноздрю.
- Итак, парни, у нас новинка: 32 бита! У нас много работы!
CISC
Окей. Парни, во-первых, давайте расширимся: стыдно в наше-то время со всего 8 GPR ходить, сделаем их 16.
Кроме того, у нас уже большой, сложный декодер, давайте не изобретать велосипед, а просто его переиспользуем. Отпрефиксим новые инструкции, у нас еще этих префиксов полдюжины! За работу!
RISC
Невозмутимо расширяет командное слово до 32 бит. И все GPR. Теперь можно адресовать одновременно 3 GPR одной командой.
Добавляет условное исполнение.
Результаты:
CISC страдает на ветвлениях и переходах, но не подает виду.
- Гипервизор …
- SIMD
- Виртуализация…
- Еще SIMD
- 64-бит
ну, вы же уже догадались, да?
Вообще по этому поводу у меня была мысль ввести механизм эпох. По сути — что бы в специальном регистре можно было задавать разные режимы декодирования команд, и программы могли использовать такую упаковку, которая им по душе. Правда, не уверен, что зависимость декодирования от данных в регистрах может быть реализована без больших накладных расходов. Да и вообще, даже на x86 упереться во фронтенд могут не только лишь все, так что скорее всего оно того просто не стоит.
Это истории реальных RISC и CISC )
Во-первых, все свойственное CISC многообразие опкодов, структуры инструкций и регистров, оно не от хорошей жизни, а от кроилова, приводящего к сиюминутной выгоде — и попадалову в будущем.
Во-вторых, по мере развития CISC обратно эволюционирует в сторону RISC (увеличивает регистровый файл, лишает особенные регистры особенного статуса — что дополнительно приводит к росту сложности системы команд) а RISC приобретает некоторые черты CISC (у некоторых GPR появляются выделеные роли).
В результате через лет 20÷30 CISC вынужден поддерживать огромным, трудноотлаживаемым и труднооптимизируемым декодером все исторические наслоения наборов команд развесистого префиксного дерева, с самого своего появления — одна и та же ассемблерная мнемоника может быть реализована несколькими ассемблерными кодами, а современные компьютеры до сих пор стартуют в 16-битном режиме; в то время как RISC имеет простые и быстрые табличные декодеры для каждого поддерживаемого набора команд и волен не тащить с собой все легаси.
Идеальная система команд CISC, к которой стремится, например, x86 — это RISC, но отягощенный x86-legacy.
Опять же, Вы привязываетесь к конкретным архитектурам, а я оцениваю CISC и RISC концептуально. Это не CISC, а x86 тащит легаси из неоптимально спроектированных команд, CISC сам по себе к этому не обязывает. И это в x86 нет упрощенных наборов команд с разными декодерами — в самой концепции CISC я не вижу на это никаких ограничений.
В общем, у Вас аргументация вида «когда-то придумали передавать данные по сети в виде цифрового сигнала, потом появился веб, и вот, спустя 30 лет, он как-то не очень подходит для современных задач — значит надо было передавать сигнал в аналоговом виде».
истории x86 и ARM … они кстати обе CISC
ARM (Advanced RISC Machine)
У них есть одно важное отличие: они выжили и распространились настолько, что стали конкурировать друг с другом.
И это отлично иллюстрирует разницу Complex и Reduced систем: они обе начиная с одного и того же ставят разные цели — и получают разные результаты.
Это не CISC, а x86 тащит легаси из неоптимально спроектированных команд
Они были крайне оптимально спроектированы и востребованы на момент разработки.
Сейчас те их фичи не востребованы, но продолжают висеть в legacy.
CISC сам по себе к этому не обязывает
Вы знаете, техника развивается и требования меняются.
В истории x86 было три поворотных момента, когда можно было все переиграть и сделать как у взрослых.
- в 386, который ввел 32-бит, но использовался как быстрый 286
- в 486, который получил RISC-ядро (наверное, от идеальности CISC, да? нельзя быть слишком идеальным)
- в AMD64
Один раз — случайность, два раза — совпадение, три — уже система.
И этот выбор делали не комментаторы на хабре отнюдь
Просто вещи так устроены: либо вы делаете complex, но извлекаете прибыль сейчас, чтобы расплачиваться в будущем, либо KISS.
Если вы продумываете march&ISA на два шага вперед — вы делаете RISC, если вы извлекаете профит сейчас — у вас получится CISC. That's all.
В общем, у Вас аргументация вида
а вот это уже лежит на тонкой грани между wishful thinking и подменой…
ARM (Advanced RISC Machine)Можно называть утку медведем, но она все равно будет выглядеть как утка и крякать как утка.
они выжили и распространилисьТолько вот x86 распространился на персоналках и серверах, что повлекло за собой проблему обратной совместимости, а ARM — на single-program девайсах и мобилках с JVM. Но проблемы с легаси на x86 разумеется исключительно из-за CISC.
получил RISC-ядро (наверное, от идеальности CISC, да? нельзя быть слишком идеальным)Уже тоже не разграничиваете RISC-ядро и RISC-процессор? Я нигде не говорил, что нужно исполнять CISC-команды в том виде в каком они есть.
Если вы продумываете march&ISA на два шага вперед — вы делаете RISC, если вы извлекаете профит сейчас — у вас получится CISCА если CISC с разными декодерами и возможностью переключаться от одного к другому?
а вот это уже лежит на тонкой грани между wishful thinking и подменой…А натягивание ARM-совы на RISC-глобус — это другое.
Можно называть утку медведем, но она все равно будет выглядеть как утка и крякать как утка
Знаете
А натягивание ARM-совы на RISC-глобус — это другое
А AVR — тоже не RISC?
Вы заставляете этого цитировать самого себя:
по мере развития CISC обратно эволюционирует в сторону RISC (увеличивает регистровый файл, лишает особенные регистры особенного статуса — что дополнительно приводит к росту сложности системы команд) а RISC приобретает некоторые черты CISC (у некоторых GPR появляются выделеные роли)
Кроме того, вам всегда, независимо от микроархитектуры, необходимо иметь выделенный command counter, flags и stack pointer (если стек используется), data stack pointer (если есть стек данных, отдельный от стека адресов возврата); если используется сегментная модель памяти или изоляция приложений — то еще и регистры сегментов.
Кроме того, операции с неявным аккумулятором, который еще и может быть физически отдельным, для ускорения таких операций, подсоединенным прямо к ALU, но явно адресуемым как r0, добавляет, как это ни удивительно, производительности.
Разумеется, эти технические ньюансы накладывают свой отпечаток на ISA.
Поэтому какого-то там идеализированного полностью неспециалированного RISC в природе быть не может, так же как и идеально специализированного CISC.
Принципиальные отличия RISC — это большой регистровый файл равноправных регистров и простая регулярная система команд vs малое количество разнородных GPR и специальные регистры со специальными командами для обращения к ним.
И это различие — не догма, не божественное повеление, а условность, показавшаяся достаточно очевидной во время определения терминов.
А если CISC с разными декодерами и возможностью переключаться от одного к другому?
У вас уже — God Object, в виде декодера. Хотите добавить еще парочку?
Потому что первое C в CISC — это Complex. Сложно. Понимаете?
Complete оно станет тогда и только тогда, когда его перестанут производить.
Потому что тогда его перестанут дополнять.
Потому что полное не дополняется.
Что проще: реализовать пару альтернативных простых таблиц трансляции, или несколько God Objects?

UPD:
Уже тоже не разграничиваете RISC-ядро и RISC-процессор?
А вы можете точно сказать, где лежит граница между RISC-ядром с CISC-декодером и RISC-процессором с CISC-сабсетом, если кроме CISC-декодера у них все остальное — одинаковое?
И это различие — не догма, не божественное повеление, а условность, показавшаяся достаточно очевидной во время определения терминов.А, ну я оперирую терминами как они есть, а Вы подстраиваете их под ARM. Ладно, пусть будет так.
Что проще: реализовать пару альтернативных простых таблиц трансляции, или несколько God Objects?Тут расчет на то, что от того, что God Object'ов несколько, они будут не такие уж и God.
А вы можете точно сказать, где лежит граница между RISC-ядром с CISC-декодером и RISC-процессором с CISC-сабсетом, если кроме CISC-декодера у них все остальное — одинаковое?В моем понимании терминологии RISC-процессор с CISC-дополнениями — это уже CISC. То есть был такой строгий и тривиальный RISC, добавили сложные команды, добавили поддержку укороченных команд — все, стал CISC. Но, возможно, это действительно неправильное понимание. Хотя подстраивать термины под хотелки ARM — тоже выглядит странно.
Вы подстраиваете их под ARM. Ладно, пусть будет так.
Этот говорил об абстрактном RISC. RISCV тут подойдет ничуть не хуже, но у него история короче, и он не настолько известен.
Тут расчет на то, что от того, что God Object'ов несколько, они будут не такие уж и God.
А зачем вообще делать God Object?
То есть был такой строгий и тривиальный RISC, добавили сложные команды, добавили поддержку укороченных команд — все, стал CISC.
Эмм… то есть, даже наивная реализация гарвардской архитектуры и банальная оптимизация r0 — уже делает CISC?
Ну и ну и ну.
Это ж тогда Power и VLIW тогда — тоже CISC. И введение не то что FPU/SIMD, а даже стека и инструкции call/ret тоже делает CISC %)
Хотя подстраивать термины под хотелки ARM — тоже выглядит странно
Поэтому надо подогнать все под x86.
Разве наши слоны уже летают?
А зачем вообще делать God Object?Я могу сказать для чего делать переменную длину команд — для оптимизации размера кода программы. А проблему того, что со временем одни команды становятся менее используемыми, а другие наоборот — решать введением нескольких типов декодеров, между которыми можно переключаться.
И введение не то что FPU/SIMD, а даже стека и инструкции call/ret тоже делает CISC %)Э нет. FPU/SIMD/стек — имеют поддержку на уровне исполнительных блоков (ну или дополнительных кешей в случае со стеком). И команды эти нужны для того, что бы задействовать эти самые аппаратные возможности. А вот введение команд типа SSE-шных dpps и crc32, которые просто транслируются в набор элементарных математических инструкций — это уже CISC-элементы.
Поэтому надо подогнать все под x86.Почему подгонять под x86? Он-то очевидно CISC по самое не хочу.
для оптимизации размера кода программы
Что очень актуально, пока вы работаете с 8-бит внешней шиной, менее актуально с 16 и совершенно неактуально с 32+.
И заодно приводит к проблемам при появлении кэша.
И требует сложного декодера.
Но позволяет урвать немного производительности, пока вы на 8/16-битной внешней шине.
И делается гораздо эффективнее RISC с сохранением всех их преимуществ.
(ну или дополнительных кешей в случае со стеком)
Нет, к кешам стэк не имеет никакого отношения.
А вот введение команд типа SSE-шных dpps и crc32
А что именно делает объединение часто используемых вместе команд в одну — CISC?
То так, если что, все математические операции эмулируются сложением, инверсией и сдвигом. Запретить RISC'ам MUL и FPU? Они же просто объединение длинной последовательности простых команд — CISC-элемент!
Почему подгонять под x86?
Вы последовательно подгоняете идеологическую (не доказательную) базу под "если в RISC есть хоть какие-то оптимизации, то это CISC". x86 просто характерный успешный представитель, ну и от RISC/CISC уже в глазах рябит. Можете читать как CISC.
Что очень актуально, пока вы работаете с 8-бит внешней шиной, менее актуально с 16 и совершенно неактуально с 32+.Ну не знаю, мы точно не упремся в подгрузку кода с RAM на какой-нибудь простыне из арифметических инструкций на 0.1-0.2 такта каждая?
Нет, к кешам стэк не имеет никакого отношения.Спутал с call/ret — в Intel'ах есть кеш точек возврата, который с ними взаимодействует.
То так, если что, все математические операции эмулируются сложением, инверсией и сдвигом. Запретить RISC'ам MUL и FPU?Срочно запретить, если нет аппаратных умножителей чисел с плавающей точкой. Если есть — так же срочно разрешить.
Вы последовательно подгоняете идеологическую (не доказательную) базу под «если в RISC есть хоть какие-то оптимизации, то это CISC».Тут смотря какие оптимизации. Если что-то вроде «ой а тут надо сделать набор инструкций уменьшенного размера» или «ну нарушим разок load/store принцип, и что с того» — то да, подгоняю.
Ну не знаю, мы точно не упремся в подгрузку кода с RAM на какой-нибудь простыне из арифметических инструкций на 0.1-0.2 такта каждая?
Как насчет 15-байтных инструкций? Это почти 4 двойных слова, или почти 8 инструкций RV64C.
Про подгрузку данных в какой-нибудь AVX можно вообще не вспоминать, там объемы будут еще больше.
в Intel'ах есть кеш точек возврата, который с ними взаимодействует
Это старая оптимизация гарвардских RISC — локальный буфер на несколько точек возврата. Подразумевается, что несколько возвратов подряд невозможны, поэтому небольшой буфер может хранить несколько последних точек, и отлаженно выпихивать их в стек/подтягивать обратно.
Срочно запретить, если нет аппаратных умножителей чисел с плавающей точкой. Если есть — так же срочно разрешить.
Ладно, а с перехватом не реализованных в данной версии инструкций и их эмуляцией что делать? А с микрокодом?
Если что-то вроде «ой а тут надо сделать набор инструкций уменьшенного размера»
Осталось убедить полмиллиона квалифицированных инжеренеров, разрабатывающих процессорные архитектуры, компиляторы и прочее, что ваше мнение единственно верное, ага.
UPD:
Кстати, а чем альтернативный набор команд отличается от команд FPU/SIMD, которые вы так любезно разрешили? В железе он реализован.
Фиксированная длина машинных инструкций (например, 32 бита) и простой формат команды.Ну то есть с момента появления Thumb ARM RISC'ом не является.
Специализированные команды для операций с памятью — чтения или записи. Операции вида Read-Modify-Write отсутствуют.В целом ARM соблюдает это правило, но он ведь еще и atomic операции поддерживает, так?
Большое количество регистров общего назначения (32 и более)Тут да, хотя по этому правилу многие архитектуры подойдут.
По четвертому ничего сказать не могу, пятое не очень понял — оно предполагает, что, к примеру, TLB должна быть реализована полностью софтварно? Вот это правило уже кандидат на объявление устаревшим.
Вот так, в моем понимании, и получается, что ARM — не RISC. Что я упускаю?
Ну то есть с момента появления Thumb ARM RISC'ом не является.
С момента появления RV32C и RV64C — RISCV перестал быть RISC?
Сокращенные наборы команд исполняются в отдельном режиме процессора, работающем с одной, отличной от дефолтной, таблицей трансляции команд. Команды из дефолтной таблицы вызывают UB.
В рамках текущего набора команд все струтура командного слова продолжает оставаться регулярной.
Разницы между поведением процессора даже меньше, чем между привилегированным и непривилегированным режимами. Просто другой Instruction Set.
Если про распихивание immed в случайные дырки, то это в Thumb артефакт, решающийся банальным ремультиплексированием, возможно хардварным.
но он ведь еще и atomic операции поддерживает, так?
Некоторые вещи обязаны быть atomic.
Скажем, рестартовать загрузку/выгрузку может быть непросто, если речь идет о прерывании, а не об исключении обработки виртуальной памяти.
По четвертому ничего сказать не могу
пятое не очень понял
Это пример для DEC Alpha.
Там еще везде используются "характерно", "типично", и т.д.
То есть, ни один из этих признаков не является обязательным.
TLB должна быть реализована полностью софтварно?
Это ж аппаратный буфер. Вот обработчик исключений может быть реализован не закрытым микрокодом, а открытым кодом, использующим дефолтный набор команд.
Англовики немного более точна:
- Uniform instruction format, using single word with the opcode in the same bit positions for simpler decoding
Регулярный формат машинного слова - All general purpose registers can be used equally as source/destination in all instructions, simplifying compiler design (floating point registers are often kept separate)
Все GPR доступны любой команде. - Simple addressing modes with complex addressing performed by instruction sequences
Тут не совсем понятно, насколько простые режимы имеются ввиду. Возможно base + disp, без множителя и без двойной косвенной адресации.
В любом случае, это проблема компилятора, программист даже на C не будет видеть тонкостей адресации. - Few data types in hardware (no byte string or BCD, for example)
AAA, AAD, AAM, REPSB и прочий зверинец.
Как-то так.
Ну так, об этом каджит сказал уже пару раз, только другими словами )
UPD:
Не совсем.
С тех пор и от строго одинакового размера инструкций отказались
В спецификации Thumb — одинаковые регулярные инструкции. Ткните пальцем, где там по вашему что-то не так.
от "радикально" упрощённого набора инструкций
Это OISC, вырожденный случай.
So much reducing)
А теперь читаем определение в вики. Ссылки были выше.
В остальном да, вы примерно правы.
Использование RISC архитектуры набора команд процессора раздувает код программы до совершенно избыточных размеров
Не до совершенно избыточных, а лишь незначительно, и не раздувает, а сокращает.
на самом деле же уже все процы в том числе и x86 построены на архитектуре RISK как тот же ARM, только с эммуляцией CISC, получается x86 уже постепенно уходит в прошлое и в некотором будущем случится окончательный переход на ARM так как apple толкает индустрию к этому. После того как основные крупные разработчики окончательно уйдут на ARM и останется что-то узко специализированное.
Знаю что с тех пор intel «закрутили гайки» и запретили тем же E3-12** v5 работать на desktop чипсетах, однако выпускают и «игровые» материнки под эти процессоры, так что собирают и современные системы на новых Xeon.
для игр NUMA это смертный приговор.
А речь про «двуголовые» материнки и не идет, обычные, с одним сокетом, так что как минимум чисто экономически определенный смысл есть.
Но речь естественно была о архитектуре.
Если тема интересует то могу посоветовать изучить тему на overclockers и пару ютуб каналов 1, 2
С другой стороны, если уделить достаточно времени на исследование рынка этих материнских плат, то можно найти что-то подходящее и для топовых камней. Лично у меня 2680v2 на 10 ядер и 20 потоков уже два с половиной года работает на китайской материнской плате без каких-либо нареканий. Но это, конечно, не гарантирует, что у вас через год работы из области VRM не повалит дым. Впрочем, никто не застрахован, косяки вполне бывают и у классических десктопных производителей.
Нужно понимать, что любая затея с китайскими xeon-ами — это про соотношение цена\производительность, не цена\качество. Чем-то в итоге придется жертвовать.
Лично я планирую собирать переносную машинку для хранения и конвертации видео, и вполне буду снова рассматривать китайские железки для этих целей.
e5 2678 v3Надеюсь, что мой ответ не посчитают рекламой сайта. Посмотрите вот здесь информацию. Там по материнским платам есть рекомендации, плюс особенности работы.
От себя могу добавить, что фотошоп любит быстрые ядра, а не большое их количество, поэтому в зависимости от искушенности пользователя могут быть проблемы. И играться с вольтажом вроде как нельзя на китайских платах, ни в какую сторону.
Стоит ли оно того, если какой-нибудь ryzen 7 2700 при 16 потоках будет быстрее вашего процессора, при этом доступен локально и с гарантией? Да, оно слегка дороже будет — но при этом экономичнее и тише в повседневной жизни.
И да, для моих задач высокая производительность весьма желательна.
По задачам, требующим высокой производительности — лично мне выгоднее переносить их в облака. Это снижает как саму стоимость вычислений так и временные затраты на администрирование.
Тут я согласен, но речь вроде бы о том, насколько процессор от Apple подобрался близко к продукции Intel и AMD.
Я бы сказал что их «слабенький» начальный процессор на 15W очень так не слабо подобрался к продукции двух гигантов. И это начальный процессор, а обещали еще полноценный процессор, для тех, кому не только видео в браузере смотреть с ультрабука. Если они запихнут туда 12-16 своих мощных ядер вместо 4 в текущем чипе, и сделают нормальное количество оперативки, вот это будет мощно.
Невозможно сделать процессор одновременно и с высокой производительностью, и с малым энергопотреблением. Физику не обманешь.А теперь факты: процессор сравнительно легко наращивается вширь, до тех пор пока он не начинает превосходить свой тепловой бюджет. Процессор также можно разгонять, хоть это и менее эффективно (дает нелинейный прирост). Т.е. имея быстрое и энергоэффективное ядро мы точно можем сделать быстрый процессор с множеством таких ядер. Собственно, в M1 как раз то самое быстрое энергоэффективное ядро.
Скорее для простоя в минимальном состоянии, когда смысла нет крутить биги.ну это mac mini же, то, что в нём крутятся big ядра потребляя на целых пару ватт больше, это вообще не проблема для стационарного компьютера.
И это (xbox) уже в продаже и дешевле есть, жаль не в качестве ПК — я б взял.еще раз — консоли продаются в минус и окупаются за счет подписок и наценок, суммарная стоимость для среднего пользователя получается порядка $1000, если не больше. По крайней мере сравнимый ПК вы даже за $1000 не соберете
Ничего не замечаете? Да, энергопотребление скорей всего там выше, но и производительность видика — не сравнима.в M1 графика 2.6 tflops с 8 ядрами, в коробке — 12 tflops на 52 ядрах.
Если б можно было легко продать производителям распайку дорогих чипов у проца с заметным удорожанием всех чипов — они б так и сделалиКстати вот здесь видно как они интересно спаковали чип. Кажется, проблем расширения памяти быть не должно.
Увеличьте количество бигядер в 2 раза и нарастите видик до уровня амд.а еще уберите little ядра за ненадобностью в стационарных решениях
Почти в два раза кристалл больше размером, больше брака, больше цены.я же не утверждаю что им не придется перенимать чиплетный подход
процессор сравнительно легко наращивается вширь? Ну да, только вот у интелов не получаетсякажется, intel сейчас уперся в TDP а не в число ядер.
у амд за несколько заходов получилосьну да, в 2017, в сотрудничестве с той же foundry что и apple…
а еще уберите little ядра за ненадобностью в стационарных решениях
Intel с вами не согласен, потому свои будущие десктопные процы пилит с little ядрами.
То есть Эпл старались, старались, а вы лучше их понимаете как надо делать?little ядра нужны для экономии энергии, которая в стационарных решениях не является камнем преткновения.
да нет, именно что в ядра на своих 10нм процах. 4/8 могут, а выше — нетдаже если они уперлись в ядра, TDP до 265 Вт для десктопного проца это тоже многовато, не находите?
У вас отлично получается наглядно показывать почему макмини это прорыв )))а я и не говорил что mini — прорыв, лишь M1 как таковой, да и то больше в мобильном сегменте. Более того, это был бы скорее плохой продукт, если бы мобильный чип apple не оказался настолько хорошим (в некоторых типовых задачах), чтобы комплектовать им стационарник. А утверждаю я лишь то, что обладая технологией производства M1 apple вполне способны представить достойные решения и в других сегментах.
А дальше вы цепляетесь абсолютно за всё за что можете. И mini с консолью по цене сравнили, и air с игровым ноутом, и до числа транзисторов докопались, и до нейронки, и терафлопсов в GPU мало, и тип памяти не тот — абсолютно до всего. Только конечно же опустили пару совершенно незначительных нюансов — десятикратная разница в энергопотреблении, фиктивность цены, разный сегмент у продуктов… но это же не важно, верно? Как там быстро коробка видосы монтирует да код компилит?
Ещё раз, вы лучше эпла значете зачем они это делают?а что, надо быть гением чтобы понять что они просто запихали в мак мини такой же процессор как и в ноутбуки? Я думал это можно предположить из названия проца.
Но тдп и скорость отличные.не такие уж и отличные, но это и не принципиально. Мы, кажется, по второму кругу идем. Если бы у intel не было проблем с yield'ом на 10nm, мы бы эти 10nm во всей линейке процов увидели еще несколько лет назад.
О, вы ж сверху утверждали, что в декстопах это не важно?так вас это и применимо к ноутбуку не смутило. Там, правда, «всего» в 5 раз.
Я уже вам отвечал, что если будет windows mode (да, даже если это будет через подписку на игры за 15$) — то коробка станет вообще отличным решением и заодно узнаем, как быстро она код компилит и видосы монтируетчтобы ввести windows mode майкам придется поменять модель распространения xbox.
а что, надо быть гением чтобы понять что они просто запихали в мак мини такой же процессор как и в ноутбуки? Я думал это можно предположить из названия проца.
Что здесь удивительного? Производить несколько разных процессоров дорого.
Это вы про то, что максимальную энергоэффективность форсят? Например, если для показа видео хватит и 4 малых ядер, на кой чёрт задействовать большие?на кой черт вообще делать мелкие ядра в стационарниках? Там не стоит задача вычислить с минимальным энергопотреблением, там надо лишь уложиться в лимит.
Эм, их 10 нм процы вполне себе на ядро уделывали же свои декстопные, о чем вы? с ноутным тдп.1185G7 разгоняется примерно до 50 Вт.
правда не в пять… а в 10, у M1 TDP 10-18W, а у коробки 200 Вт.
в режиме 120 Гц при 4Kэто маркетинговое название режима «нет ограничения в 60 FPS», на самом деле даже 60 не гарантируется. Спору нет, это всё еще круто, в сравнении с mini, я и не говорю и не говорил что mini так может. Я утверждал лишь что apple могли бы сделать сопоставимый продукт, а сравнивать коробку с air'ом, а потом с mini начали вы.
Или вы про то, что в процессорах тдп проца в ноуте в 20 ватт в 5 раз ниже тдп 25 или даже 45 ватт?18 Вт против 45 в 4800H плюс 50 в 1650. Заметьте: я предлагал сравнивать с ноутами на мобильном 4800U, на 4800H с dgpu переключились вы.
Как вы там сказали? «Ворота едут»?
То есть ещё раз, ваш аргумент: у чипа м1 тдп 10 ватт, а у всего иксбокса 165 в реальном тесте, значит в 10 раз?вот только M1 это SoC с CPU, GPU и RAM — основными потребителями электроэнергии в коробке.
Люди играли в игру и получили потребление. Тут вы начинаете рассказывать, что они играют не правильно и вообще не могли таких цифр получить?я лишь для вашей просвещенности привел факт, подтверждающий, что консоли в очередной раз делают ровно то же самое, что они делают уже десятилетиями — выдают примерно половину заявленной производительности.
Не могли. При цене в 3 коробки продать получится только вам.это ваши личные спекуляции, основанные на едва релевантных данных. Которые вы пытаетесь выдать за факты, попутно подменяя все понятия, которые вам неудобны в рамках спора.
и я вам даже ответил почему, только вы раз за разом отказываетесь читать что вам пишут, что ж с этим поделать.
— давайте сравнивать устройства на мобильных чипах между собой
— я же написал что я буду сравнивать что хочу и с чем хочу, но вы же не читаете что вам пишут! А коробка дешевле air'а, ололо
Как с вами аргументированно спорить вообще?
Так «номинальная мощность» нового макмини 150 заявлена. Эпл врут?потому что она у intel версии 150 Вт
в два раза дороже коробки.
А какой смысл сравнивать стоимость с устройством, себестоимости стоимость которого даже не известна, но по косвенным данным (правда кое что есть только по соньке, которая +- на том же железе) она практически равна продажной стоимости, а по совокупным расходам консоли вообще в минус продаются (что подтверждает анализ отчетов от той же Sony для предыдущих консолей)?
Цель продажи консоли — заработать не на ней, а на комиссиях с подписок и продажи игр. Если бы у Apple была такая же структура дохода, то макбук бы стоил 299 долларов, но заставлял вас покупать приложения на каждый чих. И браузер был бы платным, да. И софт сторонний тоже запускать было бы нельзя вот прям совсем. В общем — экономика несколько по другому работает.
суммарная стоимость для среднего пользователя получается порядка $1000, если не больше
Это для кого они столько стоят?
Да, доступ к памяти соседнего чипа будет медленнее, но вряд ли медленнее, чем доступ к отдельной оперативке v Intel‐маках.
Но это просто мысли в слух
Это ужасное решение. Либо надо как у амд — отдельный котроллер общения с оперативкой для двух чиплетов. Но это сожрёт процентов 10 производительности. В вашем варианте сожрутся все 30.
30 % по сравнению с чем и почему?
Но даже если так, то это ж всё равно позволит наращивать производительность, при этом выпуская один и тот же чип, а не делая совершенно другой продукт.
Надо лицензировать IF?
Понятно, что здесь есть накладные издержки по сравнению с просто большим по площади аналогичным кристаллом. Но выпуск кристалла с большей площадью тоже связан с издержками и проблемами.
А тут её как без изменения чипов добавить?
А если переделывать чип, то тогда да, что-то подобное придумывать придётся для увеличения всего.
И тут же дело в том, что всё необходимое вполне может быть уже добавлено в чип.
Тут будет что-то типа NUMA, то есть обращение к соседней памяти через другой процессор.
Вот именно это я и имел в виду. Вот прям неизбежно будет медленнее, чем обращение просто к чипу памяти на таком же расстоянии? Или от реализации зависит?
И я не думаю, что у M1 вообще есть шина для межпроцессорного взаимодействия.
Может нет, а может и есть. Документации к M1 у нас то нет.
Такая шина это куча неиспользуемых на текущих устройствах контактов, потраченный впустую транзисторный бюджет. Никто такое не делает «про запас».
А куча разных процессоров — это потраченный долларовый бюджет. Когда бракованное ядро отключается, то тоже вроде как впустую потраченный транзисторный бюджет выходит, но так дешевле получается.
А он и не нужен. M1 для того, чтобы объединить платформы и запустить процесс переползания на новую платформу пользователей буков и десктопов.
Как появится интерес менее массовых пользователей — так будет повод выкатить новое.
Где кодирование видео? Производительность на ватт в различных задачах? Тепловыделение реальное? Да хотя бы игры в конце концов?
Это и понятно, все смартфоны сейчас ориентированы на медиа контент, и процессоры у них соответствующие. В тех же мессенджерах когда видео передаешь оно на лету конвертируется, сжимается. Запись 4к 60FPS HDR тоже надо кодировать на лету чтобы место сэкономить
По данным Wiki (Целочисленных регистров/FP регистров):
x86-64 — 16/16
ARM 64-bit — 31/32
Кстате именно по этому эмуляция x86 на ARM проходит более хорошо (быстро) нежели наоборот.
Переименование регистров не позволяет адресовать больше регистров.
FPU/MMX/SSE/AVX ∉ GPR
Все это есть и у ARM.
Тогда для чего же нужно переименование, если не для этого?) Оно как раз заменяет архитектурные регистры на микроархитектурные и позволяет адресовать больше, чем доступно архитектурных. На линейный участок это не повлияет, а вот на независимые вычисления — ещё как.
Разница как между линейной ram и переключаемыми банками.
У вас на современной архитектуре всегда есть регистровый файл. Часть его доступна явно: это архитектурные регистры. Их количество влияет на возможности оптимизации использования памяти компилятором, некоторые вычисления при малом количестве доступных регистров или недостаточной их разрядности потребуют сохранения промежуточных результатов в память. И сохранить, в общем случае, GPR в SIMD вы не можете, потому что SIMD делает свои вычисления, возможно даже завязанные на другой поток — а это penalty.
Теневые регистры — остаток регистрового файла — менее быстры в обращении, потому как их использование предполагает смену маппинга и, фактически, работает через аппаратный хук.
То есть, при недостатке регистров в общем случае вы должны еще где-то найти регистр или два свободных, чтобы загрузить в них адрес ячейки памяти для сохранения временного значения, что лишает компилятор уже трех регистров в сумме.
И даже если запушить регистр в стек (лучше чтобы при этом был отдельный data-stack, но это еще минус один GPR), это обращение к медленной внешней памяти, которое, в общем случае, непредсказуемо по penalty.
С большим количеством адресуемых регистров эта проблема возникает существенно реже.
А теперь если еще вспомнить, что половина x86-GPR сохраняет специализацию (у ARM их, на самом деле, примерно столько же) то увеличение адресуемой части в два раза дает компилятору втрое больше регистров для маневра.
или, спецверсию кодека, типа для аниме :)
NVEnc заметно уступает в качестве кодирования обычным процамКак и любой потребительский аппаратный кодировщик. Чуда не случится. Потребительские кодировщики жертвуют точностью в пользу скорости. Есть серьезные аппаратные кодировщики, которые не уступают программным в качестве, а даже их превосходят (см. Main report (Objective comparison, FullHD videos) summary), но я в живую не видел ни одного, и даже не знаю, где и за какие деньги их покупают.
Чудеса.
Не знаю, где вы там нашли "в РАЗЫ хуже". Вполне на уровне и с Intel и AMD. (UPD: в том же классе устройств, конечно)
Комментарии о самом Cinebench написал ниже
Выиграет от этого покупатель в любом случае.
Покупатель в любом случае проиграет.
И с системой команд x86 надо все же что-то делать, ведь даже Интель внутри уже давно не x86, а стоимость хардварной поддержки старины все выше и выше, и вот сейчас яблочные демонстрируют, насколько. Если очень надо запускать винду — уже имеет смысл делать это в виртуалке под софтварным транслятором. И очень скоро так будут делать вообще все.
Беспокоиться лучше все же заранее, потому что потом будет просто поздно. Телефонный рынок в Интел упустили полностью, потому что не побеспокоились заранее.
Они ещё годами сливали на него 20-30 миллионов и продавали в убыток, пока не утомились кота за уши тянуть. Там лет шесть подряд был убыток, но они каждый год писали, что вот сегодня эффективнее на 15% и быстрее аж на 5%. Так победим!
заранили
Копьями что ли?
Сам Windows давно портирован, собирается и выпускается под ARM.
Динамическая трансляция для x86 приложений в активной разработке и выкатывается уже в ноябре по Windows Insider:
We are excited about the momentum we are seeing from app partners embracing Windows 10 on ARM, taking advantage… of Qualcomm Snapdragon processors.… we will soon release a native Microsoft Teams client optimized for Windows 10 on ARM. We will also expand support for running x64 apps, with x64 emulation starting to roll out to the Windows Insider Program in November.
Ошибся, вот тут говорят что они берут куски кода(скорее инструкций) и компилируют их в арм х64
docs.microsoft.com/en-us/windows/uwp/porting/apps-on-arm-x86-emulation
Динамическая трансляция для x86 приложений в активной разработке и выкатывается уже в ноябре по Windows Insider:
Скорее вы имели ввиду x64, ибо эмуляция х86 работает с первого Surface Pro X (Хотя пользователи жалуются на проблемы с производительностью того же фотошопа)
Это проблемы закрытого софта. Открытый никуда не нужно портировать, он и так собирается под полдюжины архитектур.
Так если у открытого софта есть деньги на компиляцию в несколько архитектур, то у закрытого, по идее, и подавно найдутся?
Вот знает ли такое слово конечный выгодоприобретатель — тот еще вопрос…
отличаются от потребностей среднестатистического пользователя ПК
Довольно странный посыл. «Среднестатическому» пользователю ПК по сути ПК и не нужен, телефона\планшета (чаще всего iPad) хватит.
Все, что делает «среднестатистический» пользователь — браузер, социалочки, документики, игрушки казуальные — новый чип делает лучше, чем существующие. Лучше — это всмысле так же быстро или быстрее и при этом компьютер меньше просит розетку.
То есть сам по себе ПК — уже давно именно что нишевый продукт. Большинство людей пользуются другими устройствами.
Какими-то «специфичными» потребностями относительно общего рынка обладают не так много категорий пользователей — программисты, инженеры различные, ученые. Процент их от общего количества пользователей при этом ничтожен.
Просто для понимания — количество программистов в мире оценивается в менее чем в 28 миллионов на текущий момент с ростом до 30 миллионов к 25 году и до 45 миллионов к 30-му.
Количество же проданных только ноутбуков в 2019 году оценивается в 261.2 миллиона с тенденцией к падению.
Даже если представить, что ученых и инженеров, которые реально работают со специфичным софтом на ноутбуках (что совершенно нетипичный кейс, для этого есть рабочие станции), столько же, сколько и вообще всех в мире программистов (то есть 56 миллионов всего) и если представить что все эти «специфичные» люди покупают ноутбук каждый год (что конечно же не так), то все равно они будут составлять лишь 20% от ежегодных покупателей ноутбуков.
Вот только ученых (вообще всех) в мире меньше чем программистов, ученых в RnD по оценкам WorldBank вообще только полтора миллиона, так что с шансом процентик еще и поменьше будет. А если вспомнить, что ноутбук покупается обычно на 2-3 года, то процент покупателей с «особенными» запросами, которые теоретически не может реализовать маубук на arm — упадет менее чем до 7%.
Далеко не все инженеры в CADах сидят, а python и прочее популярное в научно-инженерной среде и на arm прекрасно работает.
В общем — думается вы ошибаетесь.
Потребности «среднестатического» пользователя закрываются машинками от Apple на ARM более чем, даже с избытком. По сути, именно проблемы там сейчас только с одной категорией софта — виртуализацией x86, которая нужна по сути ничтожному проценту пользователей.
Покупатель в любом случае проиграет.
Ага, бедный-несчастный, у него ноутбук начал уверенно жить под нагрузкой дольше рабочего дня, за него начали просить меньше, чем раньше, новый виток конкуренции начался, который приведет к «быстрее, выше, дешевле», а он все равно проиграет.
P.S. Кстати — Windows под Arm уже давно есть. Surface не первый год на рынке, процессоры там от Qualcomm. Главная его проблема в том, что там нет аналога Rosetta, а значит количество софта ограничено. Вот только ее аналог обещают выкатить вот вот, что очень сильно поменяет картину. Так что беспокоиться еще как стоит. Я не думаю что Qualcomm не сможет сделать процессор, по скорости равный M1, который в свою очередь даже в режиме трансляции в x86 и пенальти по производительности порядка 30% из-за этого все равно быстрее low/middle линеек мобильных процов от Intel и AMD.
Какими-то «специфичными» потребностями относительно общего рынка обладают не так много категорий пользователей — программисты, инженеры различные, ученые. Процент их от общего количества пользователей при этом ничтожен.
Этот если считать, что «особыми» потребностями обладают все пользователи из этих категорий. Большей части разработчиков для работы достаточно браузера, текстового редактора и ssh клиента.
А я ещё тогда считал, что майковцы ошиблись, надо было в своё время сделать так, чтоб их винду можно было ставить на любые андроидные девайсывся современная история microsoft состоит из ретроспективно упущенных возможностей
Неа. Там и набор инструкций другой и системный API. И вообще все другое кроме PE заголовка, наверное.
Как же? Тот же ARM, тогда, правда, он был без hf, но его наличие в современных процессорах ничем не должно помешать.
Ну я не думаю что девайсы с winCE выпускались на armv8. Конечно, в режиме aarch32 оно должно заработать, если ядро его поддерживает и будут все нужные либы для aarch32.
То есть Win32API таки зарубили? Или как еще это понимать? Ведь WinCE работал с подмножеством обычного winapi.
Мне вот что-то кажется что winapi на winCE был не подмножеством, а скорее сделан по образу и подобию. Но могу ошибаться, конечно.
В Surface Pro X совсем другие чипы от Qualcomm. У них с M1 общая только базовая система команд.
А всё остальное — другое. Прям начиная с загрузчика, NVMe контроллера совмещённого с Secure Enclave и системы управления питанием, через свой собственный GPU к уникальным сопроцессорам для ML и Image processing.
Для всего этого кто-то должен сесть и написать драйвера, и я почему-то уверен, что эппл этим заниматься не будет.
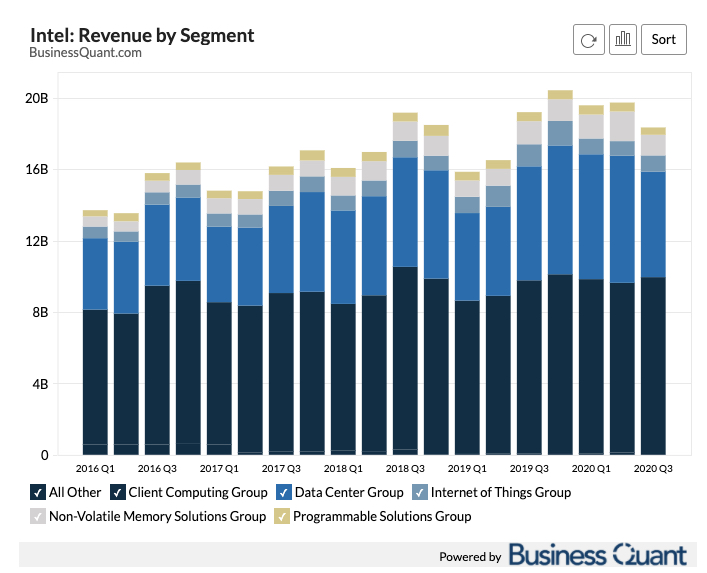
Вот распределение доли Intel/AMD.

А вот наглядное сравнение как и в серверном железе они проигрывают сражение.

Между прочим, мы сами в закупках перешли на сервера на базе AMD, потому что они производительнее и дешевле. Отказываемся от Xeon.
у Intel и AMD нет конкуренции на уровне обычной домохозяйки-школьника
Если за серверные решения я с вами согласен, то на счет школьников и домохозяек не особо.
Совсем дешевых устройств мало (пожалуй только хромбуки могут составить конкуренцию дешевым x86 ноутбукам), но вот в средней и высокой ценовой категории все сильно неоднозначно. Мало того, что весьма большая доля пользователей вообще пользуется телефоном\планшетом как основным устройством, так еще и их задачи прекрасно ложатся на ноутбук с очень долгим временем жизни, где браузер, офис и условный фотошоп прекрасно работают. И казуальные игрушки для домохозяек, и даже фортнайт для школьников.
При стоимости базового эира (которого с избытком хватит для их задач) на M1 для школьника в 900 долларов и для домохозяки в тысячу — это весьма неплохое предложение. Ноутов с таким времением жизни за эти деньги практически нет (что важно для школьника\студента), равно как и сама платформа Apple удобна для домохозяйки, если у нее уже есть iPhone (а он с большой вероятностью у нее есть). Тут еще и приложения универсальные подвезли, через полгодика на маках будет доступно все то, что доступно как минимум на iPad.
Ну то есть да, в дешевом нискомаржинальном сегменте властвует AMD/Intel, но вот в самый вкусный сегмент — middle/high зашла Apple со своим «за те же деньги, но лучше, 20 часов работы, единая подписка, привычные приложения, а еще можно в один клик фоточку перенести с айфона на комп».
Ну это при условии, что школьнику (ну, почему сразу школьнику) не нужен комп (десктоп с достаточной производительностью GPU), чтобы играть в игрушки (не проводил статистических исследований, но, кажется, большинство хотят игровые компы и играть в игрушки).
не нужен комп (десктоп с достаточной производительностью GPU), чтобы играть в игрушки
Статистика продаж игр говорит, что главная игровая платформа сейчас — мобилки, а главная игровая ниша — разнообразные мобильные
Я кстати без осуждения говорю, просто статистика.
Вот в целом данные по рынку игр:
Consoles account for 30% of the 2019 global gaming market at $45.3 billion.
PCs fall slightly behind with 24% market share or $35.3 billion.
Mobile, which we’ll discuss shortly, represents the biggest market with 46% share or $68.2 billion.3
Так что судя по всему не особо нужен, а если даже и нужен (представим, что доля у школьников между платформами такая же, как и общая, что не так, т.к. денег у них меньше, а значит покупать дорогие игровые компы, которые стоят как топовый iPhone + консолька последнего поколения на сдачу возможностей у них меньше), то только каждому четвертому.
В целом, если ты взрослый дяденька\тетенька с деньгами, или школьник с состоятельными родителями, никто не мешает тебе одновременно иметь и мак для документов, и игровой комп с 3080, и пару приставок для эксклюзивов. Вопрос то именно в приоритетах.
Сугубо по моим ощущениям и наблюдением за нынешними школьниками, игровой комп им не особо и нужен. Хитовый мультиплеер на мобилках, остальное есть на консоли. Статистика вроде +- об этом и говорит.
а зачем два компа?
"- А зачем им два телевизора?"
Задачи у них разные. У меня вот два личных компа. Жирный десктоп с 64 гб памяти, парой ТБ SSDшек, стареньким, но вполне еще бодреньким зионом и 2070 для игрушек и тяжелой работы с Linux+Windows in KVM и старенький MacBook Pro 13" 15 года, который я беру тогда, когда мне нужен терминал с браузером и я не за рабочим столом или еду куда-то. Просто разные задачи и оптимальный под них инструмент.
да нет, она про деньги обычно. Где зарабатывают больше. Ну в мобилках за счёт доения денег больше. А вот по количеству игроков речи нет
Ну тут статистика весьма мутная, я в целом согласен. Вот инфа от PC Gamers по рынку США:
If you extrapolate the computer percentage against the 67% total figure, that means roughly 35% of those in the U.S. game on PC. NPD rep Mat Piscatella says that PC gaming, for the purposes of this survey, means anything played on computers, likely including browser and social games. Still, games are games, even when you’re not tweaking settings to push your GPU to the limit.
IGN пишет несколько иначе:
1.5 billion, or 48% of global video game consumers, are PC game consumers. It's important to note, however, that «this includes some overlap with gamers that also use console systems and mobile devices.»
а главная игровая ниша — разнообразные мобильныедрочильнимногопользовательские игры вроде фортнайта и ему подобных.
Так вы уж определитесь,
Так, ну давайте пример pay2win в Fortnite, раз разницы нет)
В-баксы могут использованы для приобретения таких предметов, как экипировки, кирки, обёртки, эмоции и боевые пропуска.
Это всё косметика?
В общем, тут классическое «я Пастернака не читал, но осуждаю». Это как говорить, что Хабр – экстремистский ресурс. На вопрос, почему – привести список 100 статей с вопросом: «Они все неэкстремистские?». Вместо того, чтобы указать на конкретные признаки экстремизма в конкретной статье. И что, по абзацам их разбирать?
Так что я ничему не удивляюсь, а лишь написал о самых вероятных причинах.
Ну а во-вторых, не переживать же из-за виртуальных плюсиков :)
С налогами и другими сборами (в РФ еще курс валюты) выходит что цена базового air ~1300
Ну, если говорить и том, что происходит в РФ, калькуляция выйдет еще веселее, но давайте.
За такие деньги можно собрать хороший игровой пк или 2 неплохих ноута.
Нет и нет. 1300 долларов — это 100.000 рублей. 2 неплохихи ноута даже близко не стоят по 50к каждый.
Более того, хоть как-то стравнимая по качеству материалов и эксплуатационным характеристикам машинка от Lenovo серии Thinkpad по стоимости легко перешагивает сотку. И еще и фиг достанешь, я не так давно пробовал, как раз в РФ. Есть исключение в виде L серии, которая дешевле, но лучше никогда не сравнивать ее и макбук 1к1 на столе. Они просто из разных миров по качеству «всего». За 50к сейчас в России можно купить или кучку пластика, которая будет работать без розетки часа два и греться как утюг, или где-то за 70 «игровой» ноут от Asus или того же Lenovo в средних комплектациях в варианте «замена стационарнику». При том, что там тоже проблемы со временем жизни от батарейки, общим качеством и т.д. Они кстати все тоже не про апгрейд, а для такой машинки это важно. Можно с уверенностью сказать, что эир будет делать все то же самое, что он делает сейчас, еще года 3-4 как минимум. А вот «игровые» ноутбуки обычно за пару лет превращаются в тыкву. Хотя кому как, если для киберспортивных игрушек, то и подольше проживет, там требования обычно ниже. Если система охлождения не деградирует и оно само по себе не развалится по какой-то причине, а то есть у меня нехороший опыт с дешевыми ноутами про чисто механический износ.
А на счет хорошего игрового компа за сотку… это будет сложно. Но давайте попробуем прикинуть сколько обойдется именно системник, который потащит QHD на high/ultra хотя бы сейчас и в ближайшие пару лет без переферии вроде монитора. Про 4к за сотку можно смело забыть. Ну то есть что-то будет работать, что-то нет, но в целом целевым разрешением это назвать нельзя.
25к за Ryzen 3700x (пятой серии в продаже в РФ еще нет, но не думаю что 5600 будет стоить дешевле);
54к за RTX 3070 (представим что его можно купить по этой цене);
11к за материнку на B550, по низу рынка фактически;
10к за две плашки хорошей памяти, если быстрой — то 2х8, если средненькой, то 2х16;
4к за обычный дешманский корпус, но черт с ним;
5к за блок питания, тоже не самый топовый, но от приличной фирмы;
10к за 1tb SSD, тоже почти по низу рынка, что маловато по объему, но минимально для игрового компа сойдет.
Итого — 119к. И ужиматься толком некуда. В сотку по сути поместится только апгрейд-комплект проц+память+видюшка+мать, и то при большом везении. Ну или это будет уже не «хороший игровой комп», а комп из рекламы эльдорадо, кажется, которые «два ядра, два гига», а на выходе пшик:)
За 160 можно взять ноут с 3700x и 2070 (https://eurocom.com/ec/configure(2,463,0)NightskyARX15)
Наверняка игровой системник должен быть прилично дешевле
Ну не все так просто. Там B450 чипсет, 2 тысячи долларов стоит комплектация с одноканальной 8Гб памятью и HDD, да и 2070 это все таки предыдущее поколение. Если с такими расчетами то да, будет дешевле. Хотя вот у меня 2070 и не сказать чтобы она прям уж быстрая, 4к вообще чаще всего не может на настройках выше среднего, 1080 на ультах всегда, да. 1440p да, скорее всего будет достаточно хорошо, но у меня 4к дисплей, так что или 4к, или 1080.
Берём за 4к не дешманский корпус, а нормальный.
Найдете хороший удобный корпус не из полумиллиметрового силюмина и мгновенно царапающейся плексовой крышкой за 40 баксов — дайте ссылочку пожалуйста, я такого не видел уже лет 10.
в начальном эире 16 или даже более того 32 гигов и 1 тб ссд?
Нет. Так и не надо.
Я хочу заметить, что это вы же изначально начали сравнивать ультрапортатив (хороший, топовый ультропортатив) с «хорошим игровым компьютером» и «хорошим ноутбуком». В рамках класса эир очень хорош. Задачи, которые решает он, за эти деньги с тем же качеством не решает практически никто, есть только дороже.
Сравнивать имеет смысл только в рамках ниши, причем я изначально об этом говорил, но в итоге написал вам ответ с ценами, пойдя по вашему же пути сравнения.
Я в целом понимаю вашу позицию. Почти всегда можно вымутить варианты подешевле любого предложенного, пойдя на компромисы. Но если реально сужать рамки и конкретизирвать представление о «хорошем ноутбуке» или «игровом компьютере» то по сути результат сравнения будет напрямую зависить от интерпретации.
Лично я себе просто не возьму ноутбук, который работает меньше 6-7 часов без розетки, с дисплеем ощутимо хуже чем макбуковский, в пластиковом корпусе без гарантированно хорошей механической прочности, с гигантским блоком питания, плохим тачпадом и дюймовкой больше 15. При этом мне терафлопсы в вакууме нафиг не нужны, все реально тяжелое у меня CI собирает на облачных машинах, а всякая мелочевка дольше зависимости качает и распаковывет, чем реально компилирует. И в этом кстати опять мак выиграет, там обычно очень быстрые диски, и чем дальше — тем быстрее.
Это важно для меня, все эти вещи мне нужны на практике. В этих рамках что продукция Apple, что Lenovo, что Dell по стоимости особо не отличаются, а новые эиры вот еще и дешевле на круг. И это я не говорю о том, что просто надежность тоже важна. В маке я уверен, так же как в XPS, и в Thinkpad. Я знаю что для них есть куча сервисов в любой точке мира где мне их починят, я знаю что я двумя кнопками смогу в случае любых проблем откатить софт на машине, а если с ноутом что-то фатальное случиться, то мне нужен новый любой макбук и часок времени, чтобы развернуть бэкап из time machine и получить машину 1в1 с утраченой. И я знаю, что если я его потеряю или у меня его украдут, то данные из него не вытащат (хотя тут bitlocker тоже поможет). В общем много у этого плюсов. Равно как и у альтернативных решений.
В категории терафлопс на доллар вообще скорее всего победят китайские зионы с алика вкупе с китайской материнкой и БУшной памятью. Но для меня такое решение просто не приемлимо, наковырялся. Я хочу предсказумости, удобства и ощущаемого качества. И ноут одной рукой открывать, да:)
Найдете хороший удобный корпус
Define 7. Выглядит классно, но многое можно было бы сделать лучше, в том числе крепления дисков (как в 5), например.
И шлейф не доложили.
Нихарашо, ниудобна!
А так, до 4500 вместе с более приличным, чем low-levew, БП вписывается, например, InWin, который давно стандарт де-факто для "дешево и сердито".
Я в Польше, так что приведу местные цены, но в рубли перевести легко (20 рублей 1 злотый) — Define 7 обойдется в 739 злотых, или почти в 15 тысяч рублей.
Единственная доступная (из 3) модель этой ценовой категории от InWin mATX вот эта. Без БП. Она да, где-то около 3500. Но там ни удобства, ни качества.
Где вы в 2020 году нашли за 4500 корпус с «более приличным чем low level БП» — ума не приложу. Даже беглый поиск по рунету дал младшенькую модель InWin EFS052 без БП за 3940р по скидке при стандартной цене почти в пять тысяч. Вариант с совершенно убогим блоком питания на 400 заявленных ватт (и хз сколько фактических), стоит уже как раз 5 тысяч. Вот только ничего более-менее мощного и современного в такой корпус просто не упаковать. Да и он тоже ну никак не тянет на «качественный и удобный».
Нет, про цены второй абзац. Первый — это пример того, что неформализуемые критерии удовлетворить невозможно по определению.
У инвинов — поверманы, примерно уровня FSP БП'шки. Не Q'Dion, старого FSP.
Каджит собирает от случая к случаю, но пока осечек не было )
SuperFlower/Chieftec хорошо себя показывают, можно смело брать с загрузкой под 75-80% от номинала. Конструктивно они идентичны.
Seasonic тоже неплохи.
Из коплектных к корпусам — «beQuiet!», Inwin-Powerman и, на удивление, Exegate.
Новые дешовые чифтеки — 2 года в эксплуатации, пока без жалоб.
Вообще, если электричество не прыгает, то лет 5-7 протянет даже какой-нибудь китаец — но их надо брать с запасом по мощности раза 2÷3 — что-то вроде 600÷700W на шестиядерник + 2060 + диск.
А powerman — все тот же перекрашенный cwt только в профиль.
там хуже не то, что вы указали (кроме экрана и тачпада)
Это пожалуй две самых важных вещи из того, что я перечислил, потому что я в ноутбук обычно смотрю и работаю на нем без мышки.
Кроме того, судя по реддиту и характеристикам:
1. Нет вебки. Она нужна обязательно, 2020 год, удаленка, куча митингов. Да и до этого весьма активно ей пользовался. Вообще не представляю как можно сейчас ноут без вебки выпускать.
2. Действительно так себе экран (говорят в старшей модели лучше, но она уже перешагивает за тысячу долларов, что как по мне дороговато за сяомишный ноут, тем более остальные замечания остаются).
3. Проблемы с охлаждением. Пропилы снизу — беда. Еще и большие. Мусора там будет ой-ей. И надо обязательно на твердую поверхность ставить. У макбуков кстати такого нет, там конструкция такая, что если охлаждение активное, то он дует и забирает воздух сзади.
4. Медленный SSD.
5. Не поставляется официально за пределы Индии и Китая. Гарантия прощай.
Вообще вот тут есть обзорчик полный, правда на 16 дюймовую версию — www.notebookcheck.net/Xiaomi-RedmiBook-16-Ryzen-5-4500U-laptop-review-attractive-price-warrior-from-the-Far-East.482604.0.html
Если предположить что 14 дюймовая +- такая же, то как-то не однозначно. С одной стороны — в 2 раза дешевле. С другой стороны — SATA SSD в 2020 году. Ну то есть за свои деньги он топ (внезапно, как обычно сяоми), но с большими оговорками и все-таки не конкурент эиру, слишком уж много всего набирается, даже если не считать качество материалов и гарантии.
Корпус Chieftec CI-01B black mATX CI-01Bу сейчас за 3300 там же.
Все бы ничего, но тут (в Польше) он стоит где-то 4300 на рубли и он microATX. Это эм… весьма специфичный формат. Хотя в целом, если надо именно мелкий-мелкий корпус, то наверно пойдет, спасибо за инфу.
отыщит разницы с pcie кроме как в бенчмарках — это проблема?
Кому-то нужна причина, а кому-то — повод… )
на сайте эпла только 8 гб
Нет, объем накопителя и оперативки выбирается на втором шаге, когда вы выбрали первичную конфигурацию. Все конфигурации официально продаются везде.
sata ssd с которым большинство не отыщит разницы с pcie кроме как в бенчмарках
Это кстати весьма себе неправда. Разница чувствуется, в первую очередь по IOPS. Вот прям физически чувствуется. Поиск к примеру быстрее работает, всякие копирования документиков пачками и т.д.
Ну и проблема то не только в SSD. Остальное пожалуй даже более важно, чем собственно тип SSD. Считайте мое высказывание про диск просто фигурой речи:)
То есть 8гб/256гб в 2020 году
Вот кстати удивительно, но у меня есть прошка 15 года ровно в такой конфигурации. Она все еще достаточно бодро шевелится, причем именно потому, что там из коробки распаян весьма быстрый SSD (ну, по тем временам), который ощутимо быстрее SATAвского, что прилично ускоряет своп, а значит — не так страшно если память кончится.
Ну то есть да, лично мне уже некомфортно на нем работать, но жена к примеру меня не понимает, говорит что «все быстро же, что ты придумываешь». А я вижу эти полусекундные задержки, когда он в своп уходит и они мне кажутся вечностью. С другой стороны, если чисто серфить и документики править, то все еще вполне теплится, не смотря на весьма дохлый i5 и большинство затупов все таки связано с тем, что процессор в полку уходит, а не с тем, что памяти не хватает.
Бекап спасал уже несколько раз, в том числе и от внезапного выхода из строя встроенного SSD (который поменяли по гарантии).
У Synology DSM, которым пользовался некоторое время ранее, иногда бывали проблемы с TM. В самых тяжелых случаях лечились созданием новой копии Time Machine «с нуля». Предыдущая копия при этом или переименовывается или удаляется (через web или через командную строку).
С самой Time Machine тоже бывают «приколы», но со стороны операционной системы. Один раз по логам долго искал из за чего внезапно перестал работать бекап. Оказалось — из за файла с очень «кривым» названием. На файловой системы файл существовал и открывался, а вот TimeMachine не могла его скопировать и аварийно прерывала бекап.
Иногда TimeMachine прекращает работать, если на файловой системе остается мало места для создания локального Snapshot.
Обычно по логам можно найти причины проблем. Команда для вывода в консоль логов, параллельно работе TM:
log stream --style syslog --predicate 'senderImagePath contains[cd] "TimeMachine"' --infoНа счет ноута, это не по ценам РФ, конечно, взял пол года назад LG gram 17, 16/256 по цене базового air мака. Это более чем альтернатива. Где он и где 17-дюймовый ноут еще и меньший по весу, лол.
На счет ноута, это не по ценам РФ, конечно, взял пол года назад LG gram 17, 16/256 по цене базового air мака. Это более чем альтернатива. Где он и где 17-дюймовый ноут еще и меньший по весу, лол.
Он весит всё-таки больше Air (совсем немного 2.98lbs/1.35kg vs. 2.8lbs/1.3kg), меньше работает от батареи и очень проигрывает в производительности как CPU, так и GPU. Плюс хуже корпус, тачпад, спикеры.
Компенсируется ли это большим по размеру экраном, портами и наличием Windows? Кажется, это больше о личных предпочтениях, чем об объективном сравнении.
Про цены мне сложно судить из-за границы, но я вижу $1500+ по скидкам в крупных магазинах (за 16Гб/1Тб).
По начинке не уверен, мне кажется примерный паритет по cpu (с i7 8565u) и отставание графики, ок. Держат ноуты lg 8-10 часов или больше.
Корпус сделали специально такой, чтобы максимально снизить массу. Чувствуется не как пластик, а что-то напоминающее металл.
Про цены мне сложно судить из-за границы, но я вижу $1500+ по скидкам в крупных магазинах (за 16Гб/1Тб).
Сейчас все непонятно с ценами, но можно было взять хороший вариант за недорого.
Если сравнивать с предыдущим поколением air то там проигрыш был бы по всем фронтам, кроме может алюминиевого корпуса (кому надо) и звука. У граммов конечно все печально со звуком.
По начинке не уверен, мне кажется примерный паритет по cpu (с i7 8565u) и отставание графики, ок. Держат ноуты lg 8-10 часов или больше.
Если сравнивать с предыдущим поколением air то там проигрыш был бы по всем фронтам, кроме может алюминиевого корпуса (кому надо) и звука. У граммов конечно все печально со звуком.
Если сравнивать с предыдущим поколением, то как раз примерный паритет производительности и автономной работы. С новым же выглядит как избиение лежачего.
Я смотрел вот эти обзоры, там выдерживают примерно один набор тестов и бенчмарков, так что можно хоть какие-то цифры напрямую сравнить:
LG Gram 17 (2020)
Macbook Air (Early 2020) — Intel
Macbook Air (Late 2020) — M1
Я открыл сайт Эпл и взял из сравнения параметры cpu макбука air 2020 retina (не m1):
Processor
1.1GHz dual-core Intel Core i3
1.1GHz quad-core Intel Core i5
1.2GHz quad-core Intel Core i7
Turbo Boost up to 3.8GHz
Вы точно уверены что базовый air early 2020 с 2 ядрами и 4 потоками может составить конкуренцию граммам даже с i5?
И старший air не быстрее, а на том же уровне: www.cpu-monkey.com/en/compare_cpu-intel_core_i7_1060ng7-1327-vs-intel_core_i7_8565u-893
Что до M1. В графике 100% быстрее, как и лучше в энергопотреблении.
Тесты в ваших статьях (особенно гикбенч) — это тесты чего угодно, но не точной производительности.
Нормальный бенчмарк — это, например, cinebench. Пока что оба процессора не протестированы в одной версии, но давайте все равно посмотрим в разных версиях через косвенное сравнение с райзеном:


Прикину на глаз, 8565u = 75% однопотока m1. Уже не похоже на разрыв, правда?
Вы скорее всего скажите что i7 начнет троттлить. Я соглашусь и добавлю что m1 тоже это делает. И еще не забудьте добавить затраты на исполнение x86 на арм первые годы.
В кучу смешались кони, люди.
И после этого вы набросали каких-то рандомных фактов, сравнивая произвольные версии процессоров в неизвестно каких устройствах по непонятно каким критериям.
Мы начали со сравнения конкретных ноутбуков, кажется.
Я и привёл обзоры последней модели LG Gram, Intel-версии и M1-версии макбуков, в которых даны результаты запуска Cinebench (который вы почему-то считаете единственным нормальным бенчмарком CPU) и нескольких других тестов, включая время проигрывания видео.
По результатам, Intel-версия макбука и LG Gram близки как по производительности, так и по автономной работе.
Macbook Air M1 при этом выдаёт намного большую производительность (даже через Rosetta), и работает в 2 раза дольше от батареи.
По поводу сравнения с Ryzen — это даже не смешно. 12 Вт против 4 Вт, и всё равно проигрыш в производительности. Intel, если что, в однопотоке с турбо-бустом ещё больше потребляет.
И да, M1 в Air с пассивным охлаждением действительно троттлится при полной многопоточной загрузке (15 Вт) дольше 7-8 минут. При этом энергопотребление падает до 8 Вт, а производительность просаживается до 85% от максимума и остаётся такой неограниченно долго.
Если бы Intel или AMD завтра представили такой процессор, весь мир бы сходил с ума, а конкуренты вешались. Ноутбуки на других процессорах было бы просто бессмысленно делать.
Я и привёл обзоры последней модели LG Gram, Intel-версии и M1-версии макбуковВы привели 3 ноутбука с разными ценами.
Раз изначально шла речь о цене, предлагаю ее и взять и посмотреть на выбор моделей в начале 2020. Что можно было купить за:
$1000
macbook air 13.3" с i3
lg gram 15.6" с i5
$1300
macbook air 13.3" с i5
lg gram 15.6" с i7
Не буду дальше продолжать т.к. сложно искать цены старых маков. И на счет msrp на грамм, смысла смотреть на нее особо нет, т.к. в отличии от ноутбуков Эпл другие производители почти всегда ставят скидки на постоянной основе.
Получается вот что, на любую модель air (кроме самой топовой) всегда будет ответ с более старшей моделью cpu и опционально большим количеством оперативной памяти и диска. И младенцем здесь оказывается не грамм. Смысла, кроме академического, в сравнении моделей за условные $1000 и $2000 нет, разные сегменты.
Я надеюсь мой посыл понятен.
По поводу сравнения с Ryzen — это даже не смешно. 12 Вт против 4 Вт, и всё равно проигрыш в производительности. Intel, если что, в однопотоке с турбо-бустом ещё больше потребляет.
И да, M1 в Air с пассивным охлаждением действительно троттлится при полной многопоточной загрузке (15 Вт) дольше 7-8 минут. При этом производительность падает до 85% от максимума и остаётся такой неограниченно долго.
Вы так напираете на энергоэффективность потому что оцениваете ультрабуки по трехчасовому рендеру?
M1 безусловно эффективнее по потреблению, только в обычной работе оба едва будут тротлить и оба покажут результат близкий к своему максимальному.
Раз изначально шла речь о цене, предлагаю ее и взять и посмотреть на выбор моделей в начале 2020.
Так в обзорах как раз и сравниваются модели LG Gram с i7 и macbook air с i5.
Получается вот что, на любую модель air (кроме самой топовой) всегда будет ответ с более старшей моделью cpu и опционально большим количеством оперативной памяти и диска. И младенцем здесь оказывается не грамм. Смысла, кроме академического, в сравнении моделей за условные $1000 и $2000 нет, разные сегменты.
И более медленным SSD, хуже тачпадом, корпусом, динамиками… Это один и тот же сегмент. Был до недавнего времени.
Но эти модели Air уже и не производятся, а с M1 сравнивать цены вообще сложно, потому что конкурентов с такими характеристиками нет.
Вы так напираете на энергоэффективность потому что оцениваете ультрабуки по трехчасовому рендеру?
Потому что без энергоэффективности ноутбук греется, шумит, тормозит и часто требует розетки. Меня вот очень печалит, что запуск IDEA сокращает время работы ноутбука с 12 часов до 4, при том что процессор едва загружен.
M1 безусловно эффективнее по потреблению, только в обычной работе оба едва будут тротлить и оба покажут результат близкий к своему максимальному.
Пиковая производительность у i7-1065G7 и M1 отличается в 2 раза в многопотоке и в полтора раза в однопотоке.
Да, с i5 vs i7 разница не сильно большая, но она была. Сюда же троттлинг от отсутствия плстины на кулер в air.
И более медленным SSD, хуже тачпадом, корпусом, динамиками… Это один и тот же сегмент. Был до недавнего времени.Медленее ssd ок, тачпад не думаю, динамики хуже, да. Про корпус я же писал выше:
Корпус сделали специально такой, чтобы максимально снизить массу. Чувствуется не как пластик, а что-то напоминающее металл.Раз опять зашла речь за корпус, у макбуков до сих пор уродские рамки из 2016. Для вас это скорее всего достоинство, ведь конструкция жестче. Но это пока, когда Эпл сделает их тонкими в следующим году или позже, тогда уже тонкие рамки станут достоинством.
Потому что без энергоэффективности ноутбук греется, шумит, тормозит и часто требует розетки.
Пиковая производительность у i7-1065G7 и M1 отличается в 2 раза в многопотоке и в полтора раза в однопотоке.Это не на долго, ждем ответа Интела и Амд. Пока Rosetta 2 актуальна у них есть время.
Я понимаю удобно брать модель с i5 зная что та что шла с i3 сливала в ноль со своими 2 ядрами.
Ну да, поэтому модель с i3 — невыгодная покупка, и её никому бы не посоветовал.
Да, с i5 vs i7 разница не сильно большая, но она была. Сюда же троттлинг от отсутствия плстины на кулер в air.
Там разница на уровне погрешности, а троттлинг в тестах уже учтён. LG Gram не сильно лучше охлаждается.
Раз опять зашла речь за корпус, у макбуков до сих пор уродские рамки из 2016.
Лично меня они не волнуют вообще, но можете записать в недостатки.
Это не на долго, ждем ответа Интела и Амд. Пока Rosetta 2 актуальна у них есть время.
Боюсь, ждать долго придётся, судя по планам компаний на 1-2 года, а макбуком уже сейчас можно пользоваться.
Я не очень понимаю, как "актуальность Rosetta" что-то решает для Intel и AMD. Во-первых, приложения под ней в большинстве работают лучше, чем на предыдущих Intel моделях. Во-вторых, этих моделей маков на x86 мы больше не увидим, вне зависимости от "ответов".
Наверное, в первом моём посте в этой ветке я неправильно расставил акценты. Мой ответ был связан конкретно с фразой "Новые с м1 примерно то же самое", и сравнение там, конечно с новым Macbook Air.
Если сравнивать предыдущие модели ровно в тех ценах, которые вы приводите, я склонен с вашими доводами согласиться, если отбросить предпочтения по корпусу и ОС.
У интела уже готовы новые процессоры на 10нм, если бы их сейчас ставили в маки, результаты были бы намного лучше (Intel Core i5-1030NG7 vs Intel Core i5-1130G7), хоть и проигрывая m1.
Амд выпустит мобильные процессоры с zen3, возможно, на 7нм. Это не даст буста производительности на ватт, но +15-20% производительности ядер будет.
Пока есть Rosetta 2 есть неоптимизированное ПО которое в любом случае будет работать со штрафом к производительности, насколько помню, ~30%. И еще на новых маках винду не запустить (пока) что тоже не плюс к арм.
M1 все равно останется самым энергоэффективным, хотя бы потому что он сделан по технологии 5нм.
Тех.процесс 5FF у TSMC в сравнении с 7FF (который используется сейчас в мобильных AMD) даёт выигрыш по потреблению не больше 20%.
https://www.anandtech.com/show/12727/tsmc-details-5-nm-process-tech-aggressive-scaling-but-thin-power-and-performance-gains
Этого явно недостаточно, чтобы сократить текущую разницу между потреблением ядер M1 и Zen2.
У интела уже готовы новые процессоры на 10нм, если бы их сейчас ставили в маки, результаты были бы намного лучше (Intel Core i5-1030NG7 vs Intel Core i5-1130G7), хоть и проигрывая m1.
Tiger Lake тоже не показывает выдающихся результатов. При нагрузке на одно ядро ограничение по потреблению до 15 Вт приводит к падению производительности: https://www.anandtech.com/show/16084/intel-tiger-lake-review-deep-dive-core-11th-gen/8
Пока есть Rosetta 2 есть неоптимизированное ПО которое в любом случае будет работать со штрафом к производительности, насколько помню, ~30%.
Для большинства популярных задач Rosetta или уже неактуальна, или станет в ближайшие месяцы.
И всё-таки, как это относится к Intel и AMD?
И еще на новых маках винду не запустить (пока) что тоже не плюс к арм.
Может и к счастью :)
Для большинства популярных задач Rosetta или уже неактуальна, или станет в ближайшие месяцы.Это вы загнули. Пока что даже докер не работает. Вряд ли месяцев хватит чтобы адаптировать весь софт, разве что самое популярное ПО.
И всё-таки, как это относится к Intel и AMD?Люди не побегут покупать арм пока есть проблемы совместимости, это не упрек, а просто факт. Много читал комментов типа будем ждать вторую версию что в принципе логично. И пока она не вышла, Амд и Интел могут готовить свой ответ. Так я это вижу.
Кстати, у меня вот лежит айпад про 2020 с a12z, а до этого был еще с a12x. Так вот, несмотря на то что по однопотоку эти чипы рядом с i9 я все таки предпочитаю писать комментарии в этой статье именно с i9 потому что на айпаде каждая буква вставляется с задержкой в пол секунды, тогда как на компе даже не замечаю что пишу текст на странице с сотнями комментариев.
Ну вот, 20% энергоэффективности здесь, 10% производительности там и вот уже достойный конкурент. А то что х86 не сможет победить по потреблению арм это вроде очевидно.
Сейчас разница perf/W в 3-4 раза, что эти проценты дадут?
Это вы загнули. Пока что даже докер не работает.
Запуск докера — это не популярная задача для среднего владельца MBa. Напомню, в мире много профессий, кроме программистов.
Много читал комментов типа будем ждать вторую версию что в принципе логично.
Вы читаете комментарии гиков, делайте поправку.
И пока она не вышла, Амд и Интел могут готовить свой ответ.
Этот ответ никак не повлияет на тех, кому нужна/хочется macOS, а на новых пользователей не повлияет несовместимость с редким софтом.
тогда как на компе даже не замечаю что пишу текст на странице с сотнями комментариев
Вангую, у вас firefox на компе.
Хабровские скрипты как-то отвратительно работают в webkit/blink браузерах.
У меня на этой статье терпимо ещё всё, как раз с айпада печатаю.
А если замедлить топовые процессоры до частоты M1 — они станут в полтора раза медленнее, а потреблять будут те же самые 5-7 ватт на ядро, нет? И вот уже каждые десятки процентов начинают выглядеть значимыми.
Станут медленнее примерно в 2, и эту разницу будет так же сложно нагнать.
Не удивлюсь, если мобильные процессоры той же АМД выйдут на low power техпроцессе и окажутся существенно холоднее)
Если они используют N5P, то будет интереснее, конечно.
А если замедлить топовые процессоры до частоты M1 — они станут в полтора раза медленнее, а потреблять будут те же самые 5-7 ватт на ядро, нет?M1 таки поменьше 5 ватт на ядро потребляет, не забывайте про преимущество в техпроцессе — там на всю SoC 10-18 Вт.
Станут медленнее примерно в 2, и эту разницу будет так же сложно нагнать.не вдвое. Производительность растет нелинейно от частоты CPU, т.к. она не влияет на латентность памяти. Но на частоте в 3 гига они конечно же к M1 не приблизятся.
Anandtech в статье замерял потребление от розетки, не самым точным прибором, о чём говорится в начале статьи.
Вот это максимум, что удалось выжать из CPU в синтетической нагрузке: https://twitter.com/andreif7/status/1328777333512278020
А вот полное максимальное потребление всего пакета:
https://twitter.com/andreif7/status/1328820823877095425
На компе пользуюсь Хромом. Вот ради интереса проверил в Firefox и тоже ничего не тормозит. И с ноута писал и все было норм, а на планшете и айфоне невозможно печатать.
Не буду дальше продолжать т.к. сложно искать цены старых маков.
everymac.com
Существует кучу лет, вся инфа как на ладони.
У меня как-раз 16гб, запущен Докер на минималках с ограничением памяти в 4гб (наче сожрет всю), запускаешь ide, открываешь Фигму и всё, ты уже страдаешь. Объясните, как вы работаете на 16гб так, чтобы вам хватало?
И во вторых когда до руководства доходят реальные размеры проблемы, «эффективные» менеджеры и прочие протиратели штанов быстро вылетает пинком под зад.
Имея их бабки и видя перед собой работающее решение, они могут быстро закрыть брешь, особенно если сбросят балласт.
Объясните, как вы работаете на 16гб так, чтобы вам хватало?Легко! Избегаю приложений на электроне.
Ладно М1 (и то, уверен что его "чудеса" — следствие низкоуровневой оптимизации под бенчмарки и потребности "домохозяек"), но чем мак на интеле лучше обычного ультрабука то?
Oh, you wanted the same chart but unzipping the Xcode beta? sure. Note that the M1 shows no signs of throttling on the MacBook Pro. pic.twitter.com/jKdJD6QWo7
— Matthew Panzarino (panzer) November 17, 2020

Но надо дать должное Apple — чип M1 хорош.
А с многопоточностью не совсем честно сравнивать. У интела все ядра жирные, а у эпла толко половина. С другой стороны у интела ещё и гипертрединг есть
Ну, типичный график дефолтной сборки для CI выглядит так: 5 минут качаем, 1-2 молотим CPU.
Так что утилизовыватель-то утилизует, только толку немного.
Прекрасно утилизирует все ядра даже банальный make.
Ну в общем-то чем банальней система, тем её проще параллелить. Компиляция с прогонами оптимизаторов и так далее, кажется, к таким не относится — иначе где мои GPU-компиляторы?
А отдельные тесты сборки разных проектов — линукс, хром и т.д. есть на профильных ресурсах и ускорение там замечательное.
Линукс, хром и так далее не написаны на джаве, например, и не компилируются андроид-тулчейном. В мире есть не только c/c++ разработчики, если что.

Взято отсюда.
6 ядер против 16, а результат почти тот же, потому что на 6 ядер процесс нормально дробится, а не 16 — уже нет, и большую часть времени ядра тупят.
Также, патчи безопасности от Spectre и Meltdown должны были снизить производительность x86.
Со временем умрет и эта новая компания, когда првретится в бюрократическую машину, которая защищает свою позицию и тратит на это ресурсы.
Intel много денег и усилий тратил на борьбу с конкурентами, поставил во главу финансиста, а не инженера, вот и получили этот эффект.
Я не по iPhone едиому сужу, который уже много релизов подряд инноваций не показывает.
Это конечно сильное заявление, учитывая таймлайны что у кого когда вышло и кто еще не смог догнать яблоко с 2017 года в плане отсутствия "бороды" и Face ID. А если вспомнить какой фурор был в гиковском комьюнити, когда яблоко засунуло NVMe в 6S...
А кто тут "молодая компания"-то из вашего примера? Эппл или АМД? :D На рынке в лоб столкнулись три кита, и еще парочка плавает рядом.
Да и в целом посмотрите на историю микропроцессорных войн. Интелу в тяжелых ситуациях бывать не привыкать, в конце 90х-начале 2000х была отчасти схожая картина (с теми же конкурентами, что характерно). Сейчас, конечно, иная коньюнктура, но "закат/не закат" — это гадание на кофейной гуще в чистом виде.
Хорошо написано, но какая из компаний в списке — AMD, Apple — молодая?
Сложно выбить стул у компании, которая десятилетиями вкладывала в исследования миллиарды долларов и покупала лучших инженеров.
Nokia покинула чат.
Но даже там не спешат переплачивать за технику эппл.
Дело то в том, что техника от Apple стоит совершенно не дороже своих одноклассников, у них просто нижней линейки нет. Вообще, никто из моих знакомых оттуда (я работаю во вполне себе американской компании, почти вся моя команда сидит в США, общаемся и вообще видно кто чем пользуется), да и я сам не считаем, что Apple — это прям переплата. Просто все выбирают соответственно своим вкусам и потребностям.
Корректно сравнивать Apple девайсы по поддержке, материалам и гарантии с моделями вроде Dell XPS или Lenovo Thinkpad начиная с T серии, а если уж совсем честно, то с X серии. И вот там разницы в цене уже нет. Более того, купить качественную долгоиграющую и достаточно производительную машинку за тысячу-полторы долларов (ниша новых Air-ов) практически невозможно, там кругом будут компромисы и непонятный срок жизни.
Из практики вот что скажу. Месяц назад мне надо было купить в России (я живу уже не там, но ноут был нужен там) хороший надежный живучий ноут, при этом достаточно мощный, с возможностью получения хотя бы 3 летней гарантии и собственно примерно таким же предсказуемым сроком службы. По сути, в этих рамках продукция Apple более чем конкурента.
В итоге выбор пал на Thinkpad T14 AMD на Ryzen 4800 Pro, 16Гб памяти и 512 ssd. Видео — встройка в проц, экран обычный FullHD, 3 года гарантии из коробки. Стоимость — 118 200р, или чуть больше 1500 долларов на тот момент. За отсутствие дискретки, за так себе дисплей, но за материалы, общую надежность, предсказуемость и гарантию.
В то же время, Air на M1 с теми же 512/16 стоит +- те же 1500 долларов. При сильно лучшем дисплее и сильно дольшем времени автономной работы. Если не нужна винда и виртуалки, то это более чем оправданный выбор, потому что машинки с такими дисплеями, качеством и сроком жизни вкупе с мощностью от того-же Lenovo стоят уже больше 2 килобаксов.
В общем, вы просто смотрите с другим набором критериев и запросов, а так то у всего этого вполне есть своя ниша, и у Air-ов за 1500, и у Dell XPS за 2800 долларов, и у MacBook Pro 16 за 3500.
Более того, есть столько хейтеров Эппл, что только по этой причине им будет трудно переманить значительную часть потребителей с решений на интел/амд.скажем так: насколько легко хейтить apple за продукты типа intel-версии macbook air (существуют аналоги которые одновременно дешевле, производительнее, легче и дольше держат заряд), настолько же сложно хейтить apple за тот же M1 macbook air, windows-аналога которому по совокупности параметров попросту не существует.
Вот если бы вместе с новыми процами и цены стали более приятными. Но мечты, мечты…Mac mini подешевел на $100, правда в нем теперь память не расширяется.
Я брал в свое время в районе 70, если правильно помню. Ну да, тогда курс доллара был немного поменьше, но не настолькоВо-первых, в долларах M1-macbook'и стоят так же как предшественники. Во-вторых, за последние пару лет рубль относительно доллара как раз «настолько» и упал — почти в полтора раза.
1) Мощный процессор и так, чтобы под 100% загрузкой он не уходил в троттлинг/не сбрасывал частоты через 5 минут (а то и через 15 секунд)
2) Много памяти — 32 Гб это вообще самый минимум, 64 очень хочется, ну а 128 это идеально будет
3) 13-14" в идеале, 15" терпимо, ну 16" ещё вытяну, но никак не больше
4) Дискретное видео — вообще без него, ну может быть вытерплю какой-нибудь мусор уровня десктопной затычки GT1030
5) Нормальная клавиатура, а не то дерьмо, которое сейчас ставят Dell и HP
6) Возможность поставить линукс.
7) Чтобы под полной загрузкой он смог от аккума 1-2 часа протянуть.
И тут, что удивительно, уже «старый» макбук про 2019 вполне себе проходил (единственное, что мне абсолютно не нравилось — это тачбар), только ценник не радовал. Новые решения на ARMе мне абсолютно не подойдут, т.к. нужный мне софт есть только под x86-64 Win/Lin и он в бинарниках.
4) Дискретное видео … какой-нибудь мусор уровня десктопной затычки GT1030
Вот дискретное видео должно быть или мощным, и тогда у него будет своя термотрубка-другая, или не должно быть вообще. Варианты вроде 1030 — хуже нет, видеочип сидит посредине единственной термотрубки, которая представляет из себя горячий и холодный конец. Соответственно, идет в лес функционирование всей системы охлаждения (и без того удешевленной).
А если видюшка сколько-нибудь интенсивно используется, то привет отвал шаров.
Нафиг-нафиг, есть только одно видео для бука, и это вега.
Тем более, нафиг эту лишнюю железку. 5-7 Вт в простое просто так ей кормить…
И если брать память выше 32 Гига, то ресурс будет уходить на их синхронизацию. Просто от объема памяти толка не будет.
Ну а зачем — она вообще не нужна, но ведь блин почти никто не делает так, чтобы мощный проц и памяти много, но видюшка — интегрированная. Мне блин для задач хватило бы даже GMA950 или кто там FullHD у интела научился отображать первый.
XMG Apex 15 Видео
Правда, с видюхой — R9 3900X своей не имеет.
Lenovo E495 — 2 SO-DIMM, но проц максимум 4 ядра. В руках не держал, про лимиты теплопакета сложно сказать, 3500U может быть как на 12Вт сконфижен так и на 25… Зато amdgpu в ядре.
Lenovo T14 на AMD только с одним слотом, вроде.
Ну, у HP — их любимая дочка вместо вафли, у Dell тоже свои причуды по железу, ASUS/MSI больше геймерские (свитч amd/nvidia — как это будет под линуксами?), и вообще, производители стали зажимать слоты памяти, отчего три четверти буков сразу можно отправлять в помойку.
А насколько этот понял, 64ГБ — mission critical.
Да, задачка.
На сайте Lenovo практически все — soldered, 4/8/16 ГБ, и еще 32 можно добавить.
Кмк, остается только типа такого: 2 слота (до 64 ГБ), 4 ядра, память 2400.
Пару фоток докину, думаю корпус вполне ищется в интернетах, надеюсь помог.



Я тоже взял lenovo legion 5 15 с amd ryzen 4800h и GTX 1650 (и без винды!). Поставил 32Гб.
Железяка волшебная. Два-три браузера на 40+ вкладок каждый, десяток открытых проектов на 300К строчек в сумме (python, js, sql), 4К монитор 60Hz, всё летает.
Вот только после thinkpad'а очень не хватает кнопок PgUp, PgDw рядом со стрелочками. Ну и по мелочи: сканера отпечатков и хард-кнопок на тачпаде, очень к ним привык.
Больше всего не хватает ощущения ноутбука-девочки — для выделения текста они просто незаменимы )
После них бесполые клавиатуры не возбуждают кажутся беспомощными от слова совсем.
Ну, с эти все просто: нужен ноутбук с кли… трекпонтом, поллитра вискаря и три-пять друзей для партии в контр-страйк 1.6…
За каждую смерть — 10мл.
Вообще, если серьезно, на блютусной клаве его резкость регулируется Fn + Up/Down Arrow.
На T440s похоже тоже, но диапазон регулировок поуже. Или это аутоиммунное…
Но раз вы не хотите ответить, позволю себе поразмышлять:
Предположим что у нас есть «ноутбуки», «компьютеры» и «сервера». Первые два можно смело объеденить в «десктоп», так как разница только в мобильности не мобильности и производительности, в остальном же выполняемые задачи примерно одинаковы.
Идем дальше: есть 3 основных группы операционных систем (ну топ, конечно же)
— windows
— linux
— macos
Windows неоспоримый лидер в дектопах (мы же про них сейчас тут рассуждаем), как минимум в России.
Linux очень сильно отстает, но всячески пытается доказывать что и они тоже готовы к десктопам. Лично по мне (5 лет разных дистрибутивов) говорят что нет, пока еще не готовы. Тем не менее есть успешные примеры когда и линукс перекроет все хотелки обычного пользователя. Пример: моя сестра долго время сидела на какой-то древней убунте и не жалела что отказалась от windows которую ей постоянно приходилось восстанавливать из пепла.
macos стоит особняком так как просто так ее на «десктоп» (в контексте моего определения) не накатить. А начать пользоваться мешает довольно высокая цена на устройства. Причем эту os сразу можно вписывать в «десктопную» так как сразу из коробки и на ноутбуках, и на системных блоках (мини и про), и на моноблоках
apple выпускали некоторый софт под windows, но этого софта крайне мало, сходу вспомню itunes, quicktime и safary. Последний уже довольно давно перестали выпускать, но в пямяти он отложился.
Собстввенно, что именно в вашем понимании «десктоп» и за какие такие «свои пределы» Apple может выйти?
PS: Линуксоиды, правда, мне не понравилось, я пересел на macos и получил для себя «иделальный линукс». Так что не обижайтесь, это сильно субъективно.
Не стоит забывать, что все, что делают коммерческие компании, делается для получения прибыли.
Кроме того, для тех, у кого есть только $400 и задачки вокруг браузинга и офиса, они выпускают iPad, который со всем этим прекрасно справляется. Разве что офис там конечно ограничен, даже MS Office, но для бытового применения его более чем хватит. Да и фото и видеоредакторы там тоже отлично работают.
потому что нет денегКакой смысл делать что-то для этой ЦА, если у Apple и в сегменте 1000+ всё отлично с продажами? Кроме того, для таких пользователей есть iPad, который со всем справляется на ура и точно быстрее и удобнее, чем ноуты за 250$-400$.
а за счёт чего?
и сколько стоит такой ipad?
а клавиатура к нему?
а 1с на нём работает?
то есть браузинг и работа с доками на ipad происходит быстрее?За счет более быстрого процессора, наличия быстрой памяти, вылизанности Safari и общего подхода iOS к UI. Всё это мы сравниваем с ноутом за 250-400, не забывайте. Удобство экрана retina iPad против экрана такого ноута не надо обосновывать, надеюсь?
а за счёт чего?
и сколько стоит такой ipad?как вы и заказывали, 400 usd = 29 990 рублей.
а клавиатура к нему?Цены на родные клавы есть на сайте Apple. А вообще работает любая BT с Али за 15$-20$, если что.
а 1с на нём работает?Что за новые вводные? А почему не сразу VSC, WebStorm и Postgres? Вы в изначальном посте не обозначали такие требования.
Какой смысл делать что-то для этой ЦА, если у Apple и в сегменте 1000+ всё отлично с продажами?
Смысл в захвате рынка десктопных ОС, пока нет аналогичных ARM‐процессоров под Windows.
И я скажу, что ноут за 450 баксов, конечно, в плане шашечек уступает макам, но это офигенно крутое устройство за свои деньги.
За ноутами вижу в большем числе случаев коллег-программистов, в основном да, Apple, Desktop же за Win/Lin. Планшеты чаще вижу не iPad. Что же по статистике о планшетах, то Apple-планшеты на первом месте, но даже не лидеры в общем массе.
А вот и по ноутбукам статистика. Там, как видите, Apple, даже в 3-ку не входит.
Не забывайте, что ваш личный опыт и человечества — это несколько разные вещи.
"Если сойдутся звезды, то и MS присоединиться к гонке."
Да что же творится то такое последнее время, винда (не RT) уже года 3 или больше на qualcomm чипах работает (и даже на Raspberry Pi), 20+ часов с постоянным подключением к LTE и тачскрин в подарок. Тут скорее не присоедениться, а наконец то активнее пилить начнет девайсы и софт, судя по новостям x86_64 прослойка подъехала (было 32bit), линукса в винде грузится (и да, докер тоже говорят работает).
* — 14.1" с тонкими рамками
* — 1080р камера
* — М2 или М1х чип с достойным iGPU
* — цена в базе за 16Гб/512Гб до 1800 у.е. Как у конкурентов в виде Dell XPS 9310 или Razer Book 13
* — большой пул приложений оптимизированных под Apple Silicon
OLED вчерашний день. Ждем Micro LED (не путать с Mini LED) в течение 2–3 лет. В списке mimohodom не хватает Face ID, вот уж чего я жду больше всего!
Ну, может, Интел и Амд сподобятся выкинуть 300 неиспользуемых инструкций и всякое легаси, чтоб остался только современный x64-остов.
А какой прок от 128 бит адресации? Тут и 64-то некуда девать.
В отдельно взятом процессоре какой смысл адресовать 16 более чем эксибайт? Он к ним всё равно прямого доступа иметь не будет. А для непрямого доступа битность процессора не важна. Тут разве что может быть польза в точных вычислениях с плавающей запятой или большем диапазоне в случае фиксированной запятой. Но это весьма специфические области.
Я, конечно, понимаю, что Apple — лучшая компания с лучшим железом, а MacOS — лучшая ОС, экосистема, юзабилити и все такое, но можно мне нативный линукс + винду в дуал-буте? Боюсь, тут дела на ARM будут обстоять куда хуже, чем с х86-64, даже когда подтянутся другие вендоры, потому что (вангование):
- транслятор есть у Apple и MS, все остальные ОС идут лесом
- если судить по опыту Android-телефонов, то практически все будут иметь заблокированный загрузчик, но даже в случае возможности установить что-то стороннее, не кривой порт другой версии ОС будет достижением. Боюсь, возможности споконйо поставить Windows, Linux, их одновременно, да что угодно, и не получить проблем (зачастую), как это происходит с х86-64, тут (на ARM) будет существенно, существенно меньше.
о можно мне нативный линукс + винду в дуал-бутеИ обо всём этом на маках тоже Apple должен позаботиться?
Ну они как минимум могли бы не мешать. Дайте техническую возможность (не блокируйте загрузчик) и чуть документации — сообщество сделает все остальное.
Ну они как минимум могли бы не мешать.
То есть должны ставить палки в колеса собственному бизнесу, это слишком наивно.
палки в колеса собственному бизнесу
Знаете, если кому-то нравится железо в макбуке, но нужна именно и только винда — могли бы купить макбук-тушку и установить свою винду, Apple всё равно бы получила пачку денег за сам аппарат. Но поскольку винду нормально поставить нельзя — Apple не получает ни копейки. Будь у них хоть трижды распрекрасное железо в ноутубке — если туда невозможно поставить нужную мне ОС, я куплю не его, а ноутбук другого производителя. То же самое и с десктопами, только в этом случае я и вовсе могу из компонентов собрать.
И это принесёт бизнесу Apple гораздо бОльшие убытки, чем та незначительная прибыль от любителей натягивать сову на глобус. Потому что компания славится своим хорошо работающим железом и софтом. За исключением некоторых моментов в прошлом, связанных со спешкой.
Обо всем этом должна позоботиться индустрия и другие вендоры, которые, как предсказывают многие, подтянуться. Ну, не должны, кончено же, но очень-очень хотелось бы
Покупка по бросовой цене заводов Intel… Wait.
Сильно зависит от систем команд, между которыми трансляция происходит, и механизма. AOT-трансляция с оптимизациями в теории может давать код, более оптимальный, чем исходный, исполняющийся нативно.
Другое дело, что в данном случае выглядит так, что у M1 просто есть запас производительности, достаточный, чтобы неидеально оттранслированный код исполнялся достаточно быстро.
• RISC‐процессоры проще оптимизировать
• не требуется CISC‐декодер, то есть появляется некоторая экономия как по площади, так и по TDP.
• ARM доступен для лицензирования, что в конечном итоге позволяет использовать более совершенный техпроцесс TSMC.
Вы просто повторяете рекламные мантры, без понимания что за ними стоит.
Какие ещё рекламные мантры?! Вы несёте какую‐то дичь.
Проще оптимизировать — почему?
Потому инструкции имеют фиксированную длину, потому что они более простые, потому что их меньше.
Не требуется CISC-декодер, зато требуется RISC-декодер
Так он и в x86‐процессорах требуется, потому что в Intel уже давно поняли, что проще и эффективнее сделать RISC‐ядро, поверх которого будет эмулироваться CISC.
или думаете там всё ещё 1985 год и процессор выполняет в чистом виде по порядку инструкции, которые читает из памяти по одной?
Исходя из чего вы сделали такой вывод?
RISC не подразумевает, что в нём не может быть АЛУ для чисел с плавающей точкой или ускорителей для AES.
Имхо, тут решающий фактор — время. Будь хоть 10 суперуниверсальных конвейров — нельзя загрузить работой второй пока не декодируете первую инструкцию. Разбивать ее на µops можно уже потом, но чтобы фронтенд декодера мог что-то съесть, он должен знать, что и где начинать есть.
Увеличили время парсинга фронтом до 4T — можно поставить 4 декодера в надежде на то, что пока один фронт уже определился с длиной но еще приводит инструкцию к пригодному для спуска в конвейер виду, можно будет занять соседний декодер.
В то время как RISC может начать одновременно декодировать хоть всю строку кэша в параллель — хватило бы фронтендов.
А запас производительности как раз появился, потому что:
Потому что Apple потратила миллиарды долларов и десяток лет, чтобы сделать ядро с 8 параллельными декодерами команд и реордер буффером в районе 630. Ни один другой дизайнер RISC чипов на такое не решился, имея перечисленные вами преимущества.
ARM доступен для лицензирования, что в конечном итоге позволяет использовать более совершенный техпроцесс TSMC
А это вообще глупость. Любая компания, разрабатывающая свой чип на любой архитектуре может сделать заказ хоть на TSMC, хоть на Globalfoundries, хоть на Samsung, если договорится. Лицензии на архитектуру или систему команд вообще никак не связаны с заказами на производство.
Ну как сравнимую… При частоте 3.2ГГц (M1) выдавать производительность как у 4.9ГГц (Zen3) на ядро.
Для десктопов сейчас есть запас по энергопотреблению и на повышение частоты, и на увеличение количества ядер, даже если никаких улучшений микроархитектуры не предвидится.
Ну то есть компромисс такой — или в ширину 2x сделать или "в длину", частоту повысить 1.5х.
Мы пока не видели, компромисс ли это, или сознательное ограничение частоты, чтобы вписаться в ноутбук без кулера.
И опять же — память, не забывайте насколько память у эпла быстрее.
А насколько она быстрее? Я видел только вот такие картинки latency M1 и Zen3, и из них сложно сделать однозначный вывод. Пропускная способность памяти влияет на очень небольшое количество тестов из того же пакета SPEC.
{kind=link}
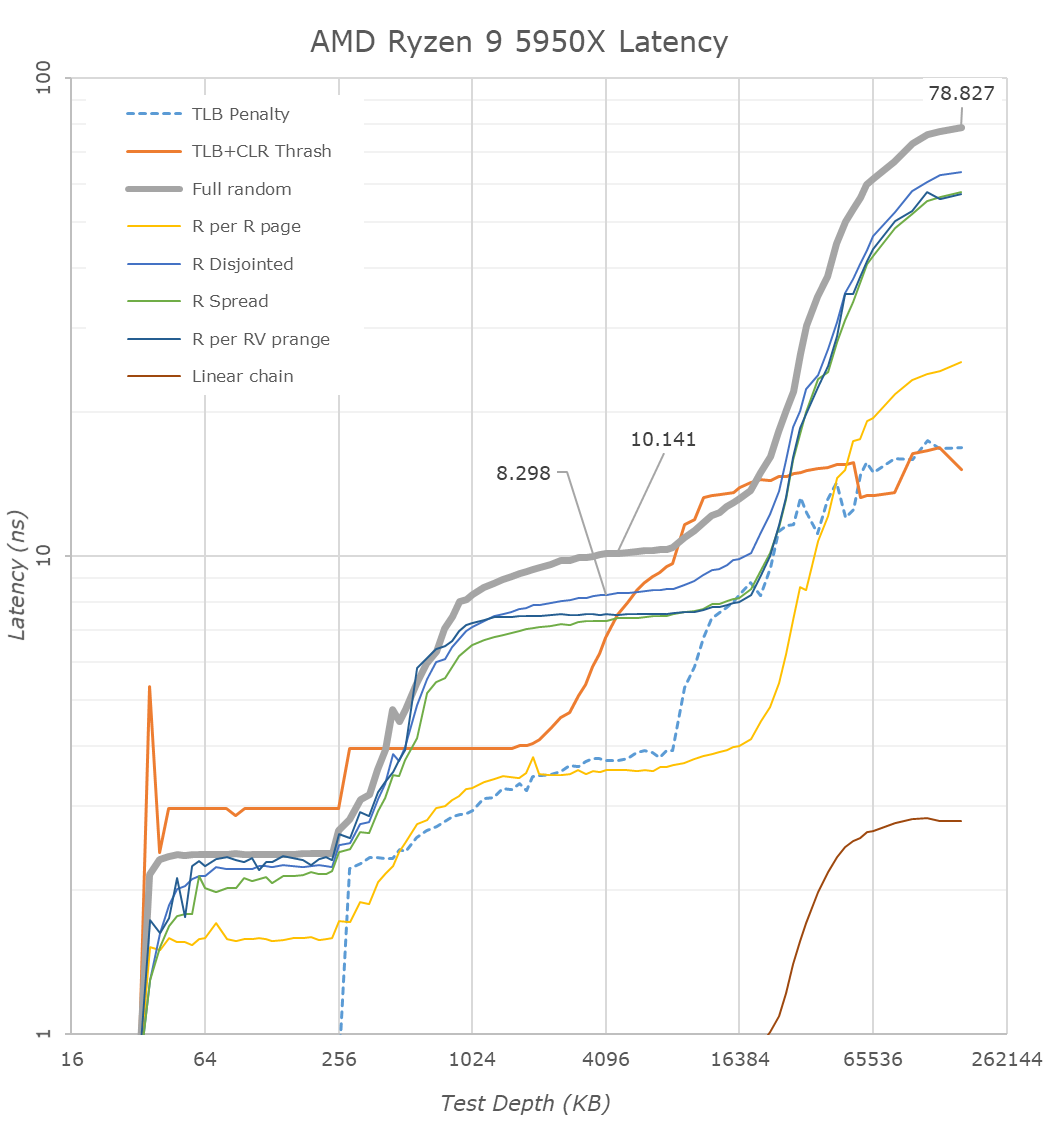{kind=link}
А это вообще глупость. Любая компания, разрабатывающая свой чип на любой архитектуре может сделать заказ хоть на TSMC, хоть на Globalfoundries, хоть на Samsung, если договорится.
Но Интел так почему‐то не делает. И чтобы у Apple появилась возможность так сделать, им пришлось перейти на ARM.
Ну, раз по вашему на TSMC можно заказывать только то, что там уже делают
Не надо придумывать какие‐то глупости и приписывать их мне.
И, как это мешало Эплу использовать любую другую архитектуру или даже накатать свою (Эльбрус передаёт вам привет)?
А зачем им любая другая или своя, если у них уже есть наработки по ARM, и эта ISA полностью их устраивает?
Зачем им Эльбрус с VLIW, если эта ISA хуже абстрагирована от микроархитектуры?
Да даже лицензировать архитектуру у АМД, забацав совместную контору для разработки и заказа процов, например?
Зачем, если ARM лучше и по другим параметрам, которые я перечислил?
В мире очень много разных ISA придумано, и ещё больше не придумано.
ARM там сейчас просто по историческим причинам, которые уходят корнями в первые чипы на iPhone, которые дизайнил ещё Самсунг.
Где отставание то?
7 против 5
Вы в курсе, что там если мерять правильно, то совсем другие цифры получаются по разным физическим причинам. И слои и расстояния между, и если внимательно копнуть, что 7 может внезапно оказаться такой же плотный как и 5
Примерно так оно и работает.
Ну вот видите, я написал то же самое ранее, но менее развёрнуто. После пояснения стало понятнее?
Написав «предыдущее сообщение», я ссылался именно на конкретное сообщение, которое предшествует текущему. Если бы я хотел сослаться на все написанные написанные мною ранее сообщения, то я бы написал «предыдущие сообщения» во множественном числе.
Так претензия была к тем словам, сейчас вы пытаетесь выкрутиться и сказать что не говорили того, что говорили?
Всё, что я писал здесь, сохранилось, так что вы можете без проблем это перечитать и освежить в памяти.
Если вы как‐то формализуете и сможете объяснить, где вам там видятся логические несостыковки, то может быть я вам смогу дать ещё большие уточнения.
чип получится И производительнее, И менее жрущим
И такое тоже может получиться, если производительность не до уровня потребления чипа на предыдущем техпроцессе повышать, а выбрать что‐то среднее.
Особенно, когда на новый ТП с улучшенного старого.
Да они уже десятки лет являются улучшениями старого. В основе всё тот же кремний, на котором удобно делать КМОП‐схемотехнику.
Далее, даже внутри одного по циферки ТП так же можно увеличить плотность или понизить потребление, а после улучшения понизить потребление или повысить частоты просто потому, что отработали технологию или повысили качество.
И это довольно очевидно, ведь при повышении плотности и токи утечки возрастают.
И, кстати, что при переходе на другие ТП частоты падали — бывало.
Не падали, а их опускали. Ну если увеличили плотность, и токи утечки возросли, то нужно это компенсировать. Понижение частоты как раз для этого подходит.
И потом про проблемы с русским у других спрашиваете?
«По умолчанию» относилось к переходу. То есть что только от факта смены циферок магически всё становится лучше.
Но я не писал, что от смены циферок магически всё становится лучше. Я писал, что «5 при этом будет потреблять меньше, что позволит сделать более производительный чип».
означает, что вы не понимаете процессов, а судите с дивана?
Это означает, что я согласился с вашей репликой, и не вижу в ней противоречия с тем, что я сказал ранее.
У вас есть какое‐то возражение по сути?
Ну а в Intel, Apple или TSMC я не работаю. А вы?
Ок, приводу реальный пример: интел при переходе с 14 нм на 10 нм смогли сделать чипы с меньшим потреблением. Но не смогли сделать более производительные чипы, чем на 14 нм.
Так это ж интеловский тик‐так, при котором либо менялась микроархитектура, либо менялся техпроцесс. То есть не не смогли, а даже не пытались.
Второе поколение на 10 нм уже лучше, но опять же только в рамках ограниченного потребления.
Ну как я и писал, можно не повышать производительность до прежнего потребления, тем самым получив и более производительный чип, и менее потребляющий.
То, что потребляет меньше, не означает, что чип можно в итоге получить более производительный.
Но вот примеры с Интелом как раз показывают, что можно.
но жрал бы больше при этом, зато и охлаждать было бы проще, чем сейчас, например.
Это как?
Или на 7+ можно было бы сразу в два раза больше больших ядер напихать, а на 5-ке это привело бы к большому проценту брака и остановились на этом.
Ну да, процент брака тут тоже влияет. Ну раз выбрали 5, значит он их устроил.
Вот к этому и возражение, что вы вначале получаете нужный вам ответ, а потом под него подгоняете решение…
Ну да, ответ уже есть в виде M1, который в однопотоке уделывает почти все процессоры. И это не чудо какое‐то, а вполне закономерный результат, которому есть разумное объяснение.
Тут и техпроцесс, и более удачная ISA.
Уже дважды не пытались, ага. Декстопные процы уже дважды выпустить не пытались, отстав от конкурентов, но нет — не пытались.
Это означает, что они не могут освоить более тонкие техпроцессы. Скорее всего это связано с тем, что они до сих пор не внедрили EUV‐литографию
Ппц. Извините, но вы в очередной раз подменяете реальность выдумками, дабы получить нужный вам ответ
Не надо врать.
В очередной раз вы подменяете производительность «удельной производительностью».
Если бы хотел написать про удельную производительность, то так бы и написал.
даже у 7нм чипов амд проблема с тем, что их размер меньше и труднее охлаждать, чем предыдущие, которые потребляли даже больше.
Ну значит либо с плотностью переборщили, либо с частотой. Либо с плотностью часто переключающихся вентилей, и сложные плохо масштабирующиеся декодеры x86 накладывают на AMD дополнительные ограничения.
Называется 15,5 млрд транзисторов на 4 ядерный проц. Тогда как чип в иксбоксе с процом 8/16, но видиком не в 2,4 терафлопса, а в 10-12, имеет 16 млрд транзисторов.
Да, это фактор легко масштабирующейся микроархитектуры под ISA ARM. Хотя напрямую число транзисторов нельзя сравнивать, потому что у Apple ещё и нейроускоритель есть.
Но и фактор лучшего техпроцесса тоже присутствует, потому что иначе зачем Apple стоило бы предпочитать 5 nm.
А потом начинаются танцы. Какой раз за тред?
Какие ещё танцы? Вы о чём вообще?
Ну то есть вы утверждаете, что чипы интела на 10 нм производительнее чипов интела на 14 нм? Конкретный пример того, как в реальности изменение техпроцесса не приводит к тому, что заявляли вы.
Я тут руководствовался исключительно тем, что вы же сами и написали. Я предоставленную вами информацию не перепроверял.
Ок, приводу реальный пример: интел при переходе с 14 нм на 10 нм смогли сделать чипы с меньшим потреблением. Но не смогли сделать более производительные чипы, чем на 14 нм. Второе поколение на 10 нм уже лучше, но опять же только в рамках ограниченного потребления.
Ну и естественно, что на более тонком техпроцессе можно сделать менее производительный чип. Обратного я нигде не утверждал.
Если у Интел были проблемы с сохранением прежней площади кристалла, ну значит у них явные проблемы с этим техпроцессом. Зря они не хотели внедрять EUV‐литографию.
Если у них были проблемы с наращиванием числа исполнительных блоков, ну это у них проблемы, вызванные ISA x86.
Ну значит либо с плотностью переборщили, либо с частотой
О, вы опять выдумываете из головы подгонку под нужный вам ответ.
Хотя ответ вам был дан прямо в моих словах, но это нужно логику иметь: меньше чип -> меньше пятно теплоотвода с которых нужно снять всё больше ватт -> сложнее охлаждать.
Это у вас спор ради спора или что? Вы написали ровно то же самое, что написал и я, только другими словами.
Да, это фактор легко масштабирующейся микроархитектуры под ISA ARM.
Доказательства сего вы не сможете кроме как из головы выдумать?
Ну да, это ж в интелах и амд дебилы сидят, тут у нас есть диванный эксперт, который утверждает, что проблемы наращивания ядер не существует!
Доказательств чего? Что в ISA с фиксированной длинной инструкций можно декодировать больше инструкций за такт? И причём тут ядра вообще, если я вам про архитектуру набора команд и микроархитектуру? Ну прочитайте хотя бы «Архитектуру компьютера» Таненбаума, чтобы в общих чертах понимать как работают процессоры и не нести ахинею.
Только в данном случае это не важно, так как обсуждается ваша уверенность на выдуманных вами фактах, что изменение техпроцесса автоматом делает всё лучше.
Вы продолжаете спорить со своими фантазиями, а не с тем, что я утверждал.
Ну вот и будет x86 планомерно отставать и из‐за техпроцессане факт что AMD не выкупят те же 3nm первыми, тут уж кто первым встал того и тапки
Или вы думаете, что ради процессора Apple свернет прибыльные области, чтобы вложиться в нанометры для пары гиков и потерять миллионы клиентов?
И больше десктопов → больше разработчиков → больше приложений.
Что значит "свернёт"? Они эти процессоры по самому новому тех. процессу ставят в айфоны.
Процессоры M1 для компьютеров появились как бонус от разработки мобильных чипов, и их производство в несколько раз меньше.
Не стоит в лоб сравнивать M1 с процессорами AMD/Intel. Сходу не припомню у последних SoC с памятью для программ на борту (Intel с их eDRAM в Iris не в счёт). Доступ в близкую память сильно быстрее и меньше потребляет.
Честно сравнить можно только программы, умещающиеся в кэш.
О тестах на латентность или пропускную способность M1 гугл пока не знает.
на anandtech есть тесты латентности памяти.
https://www.anandtech.com/show/16252/mac-mini-apple-m1-tested
Хорошая латентность. Видимо в этом весь секрет скорости M1
Их секрет не в памяти, а в широкой микроархитектуре, подобную которой на x86 не получается сделать, в частности, из-за устройства набора команд.
Из приведённой ссылки у M1 выше разрядность к память 128бит против 64 у обычного DDR. Больше разрмеры кэшей L1: 192L1I и 128L1D. Скорее всего и размеры остальных буферов (rename, dispatch/commit) так же больше чем у большинства AMD/Intel. Вот и набирается.
По числу исполнительных слотов вроде столько же, сколько у AMD/Intel.
Всю программу запихивать в кэш не надо, т.к. программы состоят из циклов и подпрограмм, вот их и достаточно засовывать в кэш. БОльшая часть программы вообще не будет исполняться, например, отвечающая за экспорт текстового документа в PDF, если пользователю это не надо. Тем более что ОСы сейчас многозадачные, и одновременно крутятся сотни программ.
Кэш — это кэш, контроллер и банки SRAM. Он прозрачен для программиста и только содержит некоторые части программы, и редко когда используется как непосредственно память для программ (в некоторых архитектурах линии кэша можно перепрограммировать как SRAM, а иногда и залочить, но это уже совсем другое).
Под памятью для программ я подразумевал любой тип SRAM/PRAM/DRAM и другие варианты, доступные по адресам. Разница между накристальной и на материнской плате огромная. Задержки и потребление будут кардинально отличаться. Можно сравнить HBM и обычный GDDR в GPU.
Если сравнивать user experience, то да, можно запускать в ОС бенчмарки и смотреть кто быстрее. При сравнении микроархитектур такие бенчмарки неточны из-за большого различия в коде как ОС, так и самой программы. Да и поведение недетерминировано. Правильнее взять маленькие программы для baremetal, умещающиеся в кэше, которые будут выполнять какую-то одну функцию. Вот тогда сравнение точное.
Уже тогда один из звоночков пошел, хоть и в специфической задаче
молодёжь уже не помнит, что WindowsNT работал на MIPS на Alpha и на PowerPC раньше.
А MacOS X изначально была тоже на PowerPC, потом перешла на Интел, и одно время бинарные файлы были в версии "fat" — скомпилированные под обе архитектуры.
С PowerPC G5 перешли на Intel когда G5 так грелся и кушал Вт что в ноутбуки его было невозможно поставить (последний ноут Applе был на G4 кажись). Тогда на презентации Джобс долго говорил и показывал графики что им важен показатель Power to W и Intel как раз тогда подвернулся с Core 2 Duo.
Теперь подвернулся прохладный ARM с лучшим показателем Power to W нежели у Intel и они перешли на ARM — вроде все логично…
Да и опыт смены платформы у Apple есть — уже 3 раза меняли Motorola -> PowerPC -> Intel. Теперь вот ARM.
Кроме того, если продукт действительно годный, то его станут пихать и в суперкомпьютеры, серверы, игровые приставки и т.п.
Что же касается тестов яблочного м1, то велика вероятность что в soc запихнули «немножко асиков» ускоряющих операции именно для бенчмарков. А вот «универсальная» производительность будет заметно ниже. Но это на самом деле не плохо, потому что у эпл есть возможность влиять на экосистему софта и максимально его оптимизировать.
ускоряющих операции именно для бенчмарков
Откуда ж вы такое берёте? Почитайте, из чего состоят бенчмарки SPEC2006, например, а потом мельком посмотрите графики, ну и текст вокруг них.
Да я признаю что не в курсе что там под капотом у бенчмарков из поста, но я и не утверждал нигде что ими манипулировали, просто высказал предположение что есть такая вероятность.
9400F стоит наравне с 2600X, 3500X и, почему-то, 2700 PRO, 10400F на 2000 дороже, наравне с обычным 9400.
При этом 3600X будет работать и позволит гнать память на дешманской доске, а интелам меньше Z чипсета для этого не подавай.
Остальная комплектуха все равно одна и та же будет.
2600, наверное. но 3500X предпочтительнее: больше IPC, частоты и кэш, в результате большая однопоточная производительнось при почти равной многопоточной.
Задержки это отдельная тема, вкратце — чем больше кэш, тем меньше чувствительность к задержкам памяти.
Разгон у интелов сразу выводит систему из бюжетного уровня, потому как растут требования к чипсету, плате, питанию и охлажению — а вы сами настаивали на бюджетной сборке.
Разгонять память на Ryzen можно и на A320, причем совершенно бюджетную, неоверклокерскую.
А вообще, блин. i9 — топчик гоницца, куплю себе гиперпень — перестало быть смешным до выхода i9.
Раз начали брать аналог, то и нужно брать аналог. А он уже на 3,5к дороже.
Ну раз уж аналог, то мать с разгоном для Intel +5к дороже, судя по DNS. Или у них память уже гонится без заветного Z?
Я настаивал на адекватной сборке
Озвучьте тогда уж бюджет, а то, может, после сборки у вас не останется даже на 1030.
1600AF/2600 это и есть адекватно: -2÷4к от 2600X/3500X, а если с авито, то еще и мать войдет в сумму нового проца (а с 1200 так и память). У интеляк с ценами на б/у вообще все печально, нет?
Каджит на Sempron 2600+ s754 с DDR400@500 и тюнингом таймингов имел latency порядка 34нс, как сейчас помнится. Так что этот ваш интел — лагодром статтерящий =)
Ой, оказывается, не все упирается в задержки.
Эти Z материнки ещё откопать нужно
Ну, из имевшегося в наличии:
Asrock X370 Killer SLI
Ryzen 3900X
M391A4G43MB1-CTD
Заводится и работает на 3333 без повышения таймингов.
Passmark Memtest находит десятка полтора жалоб ECC на проведенную коррекцию памяти.
Но!
Эта плата вообще крайне неудачна для 2R2S.
Разгонщики на нее орут "круто!" и "говно!" с одинаковой громкостью.
Под разгон берут 1R1S 8Gb, реже 2R1S или 1R2S.
Это самые первые планки с повышенной плотностью.
В ECC-планки идут самые поганые чипы, ибо они "для серверов".
Ох уж эти волшебные задержки, которые не мешают тащить кваду с 1060, не мешают стримерам одновременно кодить на проце и играть, но жутко мешают нефанатам…
Переводя на русский — проблема в том, что не Intel.
Asrock X370 Killer SLI. Купил 3900X, ибо 59x0 будут по кошмарным ценам еще год, а там через пару лет и на DDR-5 будет пора переезжать. И не факт, что его поддержка будет таки завезена.
Были сомнения по поводу лишней точки отказа в виде мелкого вентилятора, но рассмотрел его — все цивильно, отключается от материнской платы и заменяется, если что. Очумелые ручки наверное и на пассивное охлаждение этот чипсет могут пересадить при желании.
TL;DR: активное охлаждение — странное решение, но проблем не доставляет. Я и забыл уже о том, что там вентилятор, только из-за этой ветки вспомнил.
Интересно, а с (потенциально скорым) приходом PCI-E 5 как ситуация изменится? Все на активное охлаждение перейдут, или найдется решение получше?
Радиальные до 2500÷3000 можно считать silent, потом шум от самого вентилятора становится громче шума воздуха.
Потому что вентилятор этого типа не пытается взлететь.
Возможно, тут как раз такой.
Возможно дефект сборки (несбалансированость вентилятора относительно оси, непроклей верхнего кольца, если оно есть) или неудачная конструкция радиатора, создающая резонанс?
Такая же турбинка на ASUS1060TURBO слышимо шипит на скорости ~2700 и выше (но практически никогда до нее не разгоняется).
Sapphire 7970 шипела на ~2000, после 2500 добавлялся ощутимый свист, дальше к 3000 она начинала подвывать и до ~5000 уже характер звука не менялся.
CB 20 ST score
Rocket Lake 655
R9 5950X 649
Если это так, то вполне неплохо учитывая что это инженерник против серийного проца. Конечно нужно больше инфы чтобы делать объективные выводы, но я думаю по производительности вполне возможен паритет и война будет с помощью цен и разных фичь.
Я не могу говорить за всю Одессу за весь интел, но на каком-то семинаре Интела докладчик так вскользь сказал, что в общем, Интел не особо парится от проигрыша в дестопной/мобильной нише, рассчитывая наверстать упущенное в нише корпоративной и нише "тензорные процессоры для ML"
Разумеется, за что купил — за то и продаю, то есть это даже не моё ИМХО.
Я уверен, что основная причина не перехода на 7нм и 10 нм были финансовые, нафига делать с огромной себестоимостью, если можно клепать за бесценок на 14нм?
www.cpu-monkey.com/en/cpu_benchmark-cinebench_r23_multi_core-16
Например,
5950x — 28,641 попугаев
M1 — 7,508 попугаев.
Intel Core i7-8700 — 7,969 попугаев.
Т.е. процессор 2017 года на 14нм процессе с 6 ядрами быстрее. Если его выпустить на 5нм, во сколько раз он будет быстрее?
Не спорю с результатами, но замечу cinebench надо осторожно смотреть:
1) как минимум на M1 он не нагружает процессор в полочку: https://twitter.com/andreif7/status/1328777333512278020
2) это только один тип нагрузки
3) движок Cinema 4D много лет оптимизировали под x86, в том числе с помощью инженеров AMD, а под ARM у них было несколько месяцев на портирование.
4) в M1 всего 4 производительных ядра. 4 эффективных ядра в сумме слабее одного производительного.
Ах, да. Я не обратил внимание на то, с чем сравнение-то идёт.
5950x — топовый 16-ядерный процессор с энергопотреблением в 130 Вт, в котором только внутрипроцессорная шина потребляет больше, чем весь ноутбук с M1.
Intel Core i7-8700 — 6-ядерный старичок, который под нагрузкой может неограниченно долго потреблять 165 Вт с пиками до 215 Вт.
Apple M1 — 4-ядерная кроха с 4 микро-ядрами на подхвате, которая в Cinebench R23 multicore потребляет 15 Вт.
А при чём здесь память?
Вы приводите многоядерную производительность десктопных монстров с неограниченным энергетическим бюджетом и бОльшим количеством полноценных ядер.
Давайте на конкурентов с тем же количеством ядер посмотрим? Или на single-core производительность? И тут выходит, что из всех (вообще всех существующих) процессоров на всевозможных бенчмарках, только Zen 3 и топовый Tiger Lake (и практически исключительно в Cinebench R23) кое-как обходит M1, даже без учёта энергопотребления.
Это феноменальный результат для чипа, который предназначается для ультрапортативных ноутбуков с пассивным охлаждением.
И вот вполне вероятно, что тут могут возникнуть проблемы при увеличении числа ядер. Например физические размеры кристаллов при 8-16 ядрах в М1 могут феноменально увеличить процент брака и следовательно стоимость. Или память припаять в 32-64Гб станет проблемой. А разделив М1 на 2 чипа и вынеся память, появятся задержки и производительность упадет.
Более того, я абсолютно уверен, что текущая цена компов на М1 — это в убыток. После того, как они пересадят людей мы узнаем реальную цену всем этим однокристальным компоновкам на 5нм
Меня не интересует мобильный рынок практически совсем. Чтобы подорвать АМД или Интел нужно конкурировать на рынке десктопов и серверов.
Десктопы появятся в течение 2 лет, но врядли "подорвут" Intel и AMD. Далеко не всем в принципе нужен Mac, без разницы, какая у него производительность.
А серверов от них, я почти уверен, мы не увидим вообще никогда.
Более того, я абсолютно уверен, что текущая цена компов на М1 — это в убыток.
Apple не делает устройств с маржой меньше 30%. Вообще не делает, никаких, её акционеры сожрут за снижение маржи. А выпущенные сейчас устройства — это наиболее продаваемый сегмент маков, с большим отрывом.
Плюс они уже много лет продают iPad Pro с процессорами аналогичной конфигурации, и примерно той же площади, за более низкую стоимость.
Про конфигурацию же ожидаемых десктопных чипов пока рано рассуждать, тем более строить прогнозы, что у них что-то не получится, когда они уже публично рассказали про 2-х летний план полной миграции всех линеек.
Zen 2 на 15-25 Вт пока крайне слабенько выглядит с 8 ядрами. Это если по-честному ограничить энергопотребление, а не на бумажный TDP смотреть.
Но да, думаю Zen 3 в мобильном исполнении вполне неплохо себя покажет.
По крайней мере, в том же районе TDP будет выглядеть конкурентом. Осталось их дождаться.
- специализация че там они гоняют через т.н. нейрочипы
В бенчмарках Geekbench и SPEC2006/2017 никак не задействуется Neural Engine, это всё-таки тесты CPU, а не сопроцессоров.
маркетинговая брехня про 3х-5х быстрее
Если вы про презентацию, то они там явно говорили, что это сравнение с теми устройствами, которые были как раз обновлены с M1 (на сайте Apple в сносках есть полные конфигурации моделей и обтекаемое описание нагрузки). Эти результаты все обзорщики подтверждают.
Но ребятам из anandtech похоже занесли чемоданы денег на обзор, так как в синглкоре сравнение с 5950x есть, а результат в мультикоре под 30к (в сравнении с 8к M1) куда-то пропал. То есть, когда удобно — сравниваем с десктопным топом, а когда нет — ну уж извините, результаты 5950x мы уберем. От таких манипуляций складывается ощущение, что где-то меня пытаются надурить.
Еще тестов компиляции более релевантных и повторяемых бы найти.
Да потому что это просто бессмысленно — сравнивать многоядерную производительность 16 ядер и 4.
Если у вас стоит выбор между десктопом с 5950x и макбуком на M1, а решающим будет производительность многопоточной компиляции — берите десктоп, не ошибётесь.
Вышедшие сейчас эппловые процессоры — самая младшая линейка, для ультрапортатива.
Цена за чип конечного пользователя вообще не должна волновать, только цена устройства целиком. Отдельно они не продаются.
В том, как может быть устроен сильно-многоядерный десктопный чип на той же архитектуре, пока ни у кого нет уверенности. Вполне возможно, что вынесут GPU, Neural Engine, на отдельные кристаллы. И/или чиплетами начнут наращивать. Или многопроцессорные системы сделают. Или сдадутся на полпути кинув всех разработчиков и первопроходцев :)
Я пророчествами не занимаюсь, и предлагаю просто ждать, а пока пользоваться тем, что есть на рынке и решает возникающие задачи.
А мак мини может и куплю родителям, но только потому, что им и планшета бы хватило так-то.
И я вот себе взял Mac Mini для работы над домашними проектами, благо не собираю ничего сверх-тяжёлого. Да и поиграться с ARM интересно.
А десктоп у меня уже есть, я на нём в VR играю.
А то в этом обзоре складывается впечатление, что М1 чуть-чуть не дотягивает аж до самого 5950x.
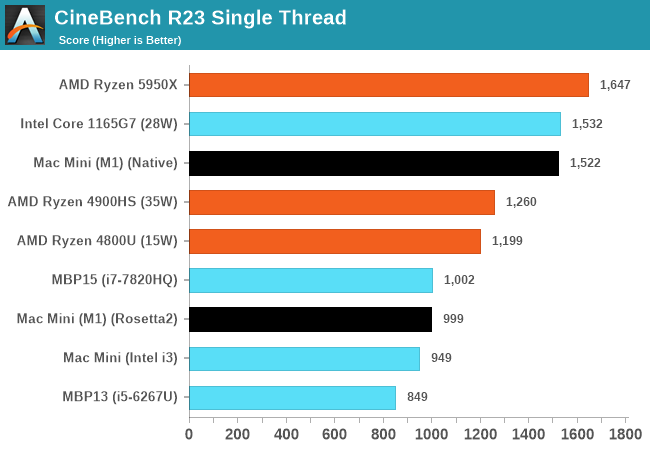
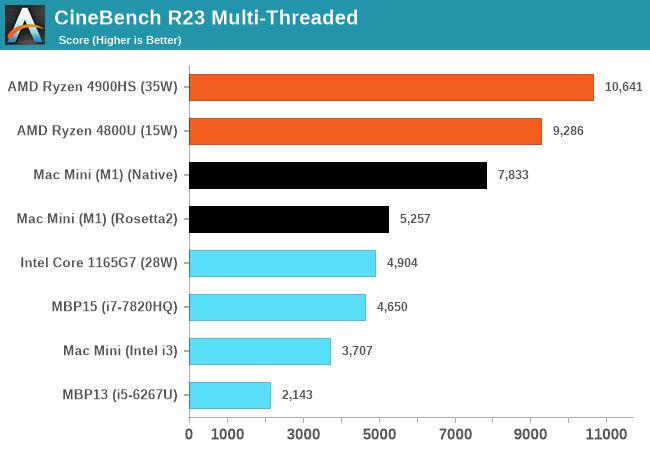
Это все совершенно никак не сочетается с вашими заявлениями.
Сочетается. Может у домохозяек и есть время читать статьи Anandtech от корки до корки, у меня же при беглом просмотре графиков отложилось, что M1 тестируется в том числе и с десктопным 5950X и при этом постоянно оказывается где-то сверху в рейтингах. А уже потом замечаешь, что 5950x в неудобных тестах куда-то пропал.
У меня аж мышь затряслась в припадке от кликбейтности заголовка.
Всё очень просто, я еще пару лет назад говорил, что ARM перегонит x86 по простой причине, что рынок ARM растет гигантскими темпами и денег в разработку и производство вкладывают такие же гигантские суммы, которые бысто отбиваются. Кто-то может тешить себя мыслью, что пока в реальных задачах еще х86 выигрывают, но для примера — на днях снял на 865 snapdragon 8k. Так десктопный проц Ryzen 2600+radeon rx580 — при простом воспроизведении 8к тупит безбожно. А на телефоне и запись и плей все без тормозов и прочего. То получается, что в практичных задачах — запись, обработка видео, и заливка на ютуб ARM уже 1-2 года как обогнал десктоп. Так что apple вовремя пересела на ARM, а скоро интел и амд за ней — после 1-2 года отрицания будут в роли безнадежно отстающих, особенно если софтовые гиганты подсуетятся. Ну и в пользу арм говорит выбор эппл — не помню чтобы эппл стратегически ошиблась.
2. И техпроцесс 7нм против 12нм.
3. У Snapdragon 865 специализированный сопроцессор для обработки изображений Spectra 480, наверняка «на телефоне и запись и плей все без тормозов и прочего» только благодаря ему, а не какому-то волшебству ARM.
В очередной раз в комментариях сравниваются не особо сравнимые вещи и делаются выводы о какой-то непонятно откуда взявшейся исключительности ARM.
Плюс тут ещё разница в том, что Snap 865 это SoC, а Ryzen 2600 просто CPU. Ваша видеокарта может и содержит аппаратный кодек для видео, но софт не умеет с ним работать.
Это я не к тому, что ARM не заборет x86, а просто пример не очень.
Такие сопроцессоры, какие захочет поставить Qualcomm или Apple или ещё кто-то. Какая по сути разница?
Разница в том, что с ARM могут и ставят, а с x86 не могли и не ставили, и приходилось колхозить чип Tn. А нейрочипа просто не было, в том числе и у меня в ноутбуке не было.
Вы же не можете собрать процессор себе.
Могу, если буду как Apple или Qualcomm. Да даже есть процессор Baikal, так что лицензию ARM себе может прикупить любой желающий, только деньги нужны.
В очередной раз в комментариях сравниваются не особо сравнимые вещи
Никто напрямую не сравнивает, ведь тут не про обработку, а про простой плей формата видео который появился в далеком 2013! году, а соответсвенно rx 580 (2017) и ryzen2600 (2018) устройства среднего диапазона в которых не реализован простой плэй формата четырехлетней давности. Я понимаю, что упор был на криптовалюты и прочее, но пару баксов на аппаратное декодирование могли бы добавить — ведь уже пару лет были 8k контент и устройства. Но основной посыл комента был в том, что ARM выигрывает не за счет архитектуры, а за счет гигантских вложений в разработку и производства на фоне более быстрого роста рынка и большего объёма АРМ процессоров в сравнений с х86.
то есть вы хотите чтобы AMD в 2013-2014 году предугадало, что ваш телефон в 2019 будет снимать тяжелые видео ещё не существующего кодека и реализовало для него поддержку? Смешно.
- 8k и устройства и контент уже были в 2013-2014. HDMI 2.0 поддержкой 8k в rx580 уже был.
- Из вики про h.265: "29 февраля 2012 года на выставке Mobile World Congress компания Qualcomm показала HEVC-декодер, работающий на планшете под управлением ОС Android с двухъядерным процессором Qualcomm Snapdragon S4 с частотой 1,5 ГГц. Показывались две версии видеозаписи с одинаковым содержанием, закодированными H.264/MPEG-4 AVC и HEVC. На этом показе HEVC показал почти 50%-ное снижение скорости передачи по сравнению с H.264/MPEG-4 AVC"
- Декодирование видео — это тяжелая задача? как-то celeron 266 нормально воспроизводил mpeg4. Просто тут имеем дело с элементарной
жадностьюэкономией в пару $ производителей на x86.
это вы наверное с 4к путаете.
Согласен, перепутал по памяти с 4k c 60fps.
Декодирование видео — тяжелая задача… патентные отчисления на весь комплект кодеков..
тут тоже согласен что задача тяжелая, но всё таки декодинг значительно легче кодирования. А вот патентные отчисления за кодеки, то тут не со всем согласен — плата за кодек не зависит от разрешения. h.264 одинаков для 2к, 4к, но для 8к уже используется модификация h.264 -> h.265 или HEVC (2013 год) и вот тут уже и открывается причина нереализации 8k аппаратно, оказывается h.265 имеет три патентных пула с различными условиями ценообразования и даже в 2020 особенно при появлении кодека AV1 ситуация с кодеками 8k не совсем определена. Поэтому также соглашусь, что в 2017 году реализовывать аппаратно h.265 не было смысла, так массового его использования ещё не намечалось.
P.S. Хочу сказать спасибо за аргументированное обсуждение, в результате которого добрались до сути вопроса по аппаратному 8к.
как 8К стало "фактом жизни", чем-то таким, что чуть ли не всегда было с нами :)
никто не говорил так про 8K, просто был шокирован, что ПК с неслабой и нестарой начинкой не сможет воспроизвести записанное смартфонным процессором.
Пример с 8k может и не совсем в тему, как я писал выше суть первоначального комента не в этом, но просто меня эта недееспособность моего ПК задела. А 8к мне вдруг стал критично нужен после пробного захвата кадра из видео, учитывая, что в телефоне реализовано слежение фокуса за объектом — то получается серийная съемка в 30к/сек с кадром в 32МПкс.

Это ведь идеальная находка для получения уникальных фото с активного отдыха и прочих трудноуловимых событий. И при увеличении качество аналогичное фоткам с таким же разрешением.
Так десктопный проц Ryzen 2600+radeon rx580 — при простом воспроизведении 8к тупит безбожно.Как уже написали в комментариях, это заслуга аппаратного ускорения, сам процессор на ARM в задачах с активным аппаратным ускорением условно отдыхает. При кодировании видео с видеокарты NVIDIA через NVENC загрузка CPU тоже не сильно отличается от простоя.
Кроме того, нельзя забывать, что пользователи ПК жертвуют производительностью в угоду универсальности, по крайней мере в моей сфере деятельности (работа с видео). Если на ПК я могу пользоваться любыми мыслимыми эффектами и инструментами, то на телефонах функционал ограничен тем, что работает с приемлемой скоростью.
Как пример из той же области (не зарезанный функционал, но завязка на «свое»): хорошо работает на маках (можно даже сказать «летает») сильно ограниченное количество кодеков профессионального видео. Доходит до того, что снятое в другом кодеке видео проще сконвертировать в любимый Apple ProRes, нежели терпеть тормоза оригинального кодека (и речь не про консьюмерские кодеки, типа H.264, для монтажа не предназначенные, а все еще про профессиональные). На Windows в том же софте проблема не так выражена.
То получается, что в практичных задачах — запись, обработка видео, и заливка на ютуб ARM уже 1-2 года как обогнал десктоп.А вот это целиком и полностью зависит от глубины погружения в вопрос. Снять свой заезд на велосипеде, обрезать, подложить музыку — несомненно. Какие-то в меру серьезные проекты при большом желании тоже можно целиком и полностью сделать на телефоне (хотя не помешают внешний монитор и клавиатура). А такие вещи как профессиональная цветокоррекция, работа с дополнительной графикой, да и много чего еще — на телефонах просто пытка. Как и на ноутбуках, собственно. Да, ПК в 2020 по ощущениям — скорее инструмент профессионала, нежели развлекательный комбайн (отсюда ПК был выдавлен телефонами и планшетами, причем давно), но до теоретической смерти ПК в целом, и x86 в частности, еще ой как далеко.
Ну и в пользу арм говорит выбор эппл — не помню чтобы эппл стратегически ошиблась.ЕМНИП, архитектуру они меняют не в первый раз и как минимум один раз (второй?) они это делали не от хорошей жизни. Я в истории Apple не силен, но уверен, что кто-нибудь в комментариях подсобит статьями на тему.
А вообще, прогресс — это прекрасно. И воевать в комментариях за какие-то корпорации или архитектуры — странно. Главное, чтобы фактическая производительность продолжала расти, желательно с уменьшением энергопотребления и цены, но последние два уже хотелки, а не необходимость, по крайней мере лично для меня.
И воевать в комментариях за какие-то корпорации или архитектуры — странно.
Что-то я не помню, чтобы где-то начинал войну, просто сообщил, что ещё пару лет назад мне было очевидно, что при настолько быстром развитии процессоров АРМ и дальнейших больших финансовых вливаниях АРМ догонит и обгонит x86, откусив у x86 значительную часть рынка. Так и произошло, а пример с 8к привел, так как меня не устраивает копеечные экономии на аппаратном декодировании производителей для х86, ведь впервые столкнулся задачей, которую средний десктоп не тянет и ведь задача не архисложная. А ведь зачем мне 8k видео? Ответ прост — в телефоне есть слежение фокуса за движущемся объектом и объект всегда в фокусе и если взять стоп кадр из видео, то будет не хуже аналогичного фото. Только тут у меня серийная съемка 30! кадров в сек на долгом протяжении времени для фиксации нужных мне кадров! Если для отпуска и активного отдыха — эта фишка позволит запечатлеть неуловимые моменты. А тут вдруг на нестаром десктопе такая засада, и позиция производителей под x86 — нужен плэй 8k? -заплати нам 500$ за новую видяху, ведь даже на 1060 у колеги тоже не тянет.
Вот тут мы подбираемся к сути борьбы и вероятного исхода этой борьбы. Производительность АРМ за последние 5-6 лет выросла в 8-10 раз, а процессоров ПК в 3-5 раз. Понятно что все равно упрутся в технологические ограничения, но даже в этом вопросе АРМ вырвался в лидеры и уверенно наращивает обороты быстрее, чем в лагере х86.
Моя ошибка в том, что я исходил из предпосылки, что за три года на рынке ПК мощность выросла в небольшие 1,5-2 раза и зазор мощности у х86 2017,2018(ryzen 2600) годов должен был с легкостью справляться с аналогичными задачами ARM процессора 865 (2019). Но АРМ движется семимильными шагами и за 3 года рост мощности и освоения новых технологий опережает пока более консервативный рост х86 в 1,5-2раза.
Ради баланса предлагаю сравнить через три года топовый компьютер с вашим сегодняшним телефоном на рендеринге или компиляции или ещё какой неспецифической для телефона задаче
Согласен, что мой пример не совсем удачный, но лично для меня было шоком, что относительно свежий по начинке ПК не тянет простую задачу по воспроизведению, а телефон успешно выполняет более сложную задачу по кодированию и записи.
даже в этом вопросе АРМ вырвался в лидеры и уверенно наращивает обороты быстрее, чем в лагере х86
Интел тоже показала невероятный рост году так в 2006.
Правда, для демонстрации такого роста потребовалось 5 лет впаривать тормозные кипятильники PIV и отстать по IPC аж на треть от конкурента)
Вот и арм — они, конечно, очень молодцы, но до потолка, в который давно бьются x86, им пилить еще и пилить.
Вы правильно рассуждаете, но посыл моего первоначального коммента, что ARM песпективнее не из-за архитектуры, а из-за большего финансового стимулирования, быстрорастущего рынка, жесткой конкуренции и все возрастающими требованиями рынка. На рынке х86 эти стимулы намного слабее. Это было для меня очевидно пару лет назад, и в одной дискуссии большинство говорили, что я не прав и что АРМ в ПК никогда не будет, но теперь АРМ прочно уже застолбилась на рынке ПК и это лишь начало. Дальше будет ещё интересней, и выбор для нас будет шире и цены ниже — это замечательно! главное пережить восстание машин :)
Давайте ещё по количеству мегапикселей встроенной камеры сравним — ой, в ПК 0, в смартфоне 42
Сравнение производительности кодирования и декодирования используется во многих бенчмарках, а декодирование видео одна из востребованных функций, как на ПК так и на смартфонах, а ваша шутка сравнения неадекватна.
А за телефон на топовом снапдрагоне вы не заплатили 500$ что ли?
телефон взят для работы — предметной видеосъёмки, последующей небольшой видеобработки и заливки — с этой работой справляется на все 100%, видео штампует как горячие пирожки, и окупает себя полностью. А 8k декодирование на ПК далеко не основная задача и вкладывать 500$ лишь на её решение нецелесообразно.
на этой задаче с бюджетным "нестарым" железом четырёхлетней давности и внезапно оно проигрывает
snap 865->ryzen 2600 лишь 1,5 года, и учитывая что десктопный проц vs мобильного, то вполне уравнивает разницу во времени.
И вообще-то плей идет — но 10-15кс и ещё бы пару оптимизаций и было вполне смотрибельно. Так что мой пример адекватный, ведь никто не предполагал, что 4k 60fps это граничный предел перехода на новый уровень технологий.
Что-то вы далеко ушли от обсуждения статьи про M1, Epyc, Ryzen, Intel. Мой коммент был что Арм в лице М1 успешно начал боевой поход против х86 и вскоре эта война выйдет на новый уровень, вам есть что сказать по теме статьи? Потому как я высказал свое мнение по теме статьи и никаких посторонних вопросов для обсуждения темы 8к не задавал и считаю это обсуждение тут не уместным.
На новый уровень — напихивания специализированных чипов?
Это вы про Apple M1? а тесты в статье вам тоже не показатель? Через 1-2 года потомки М1 заменят интел в apple в нижних и средних моделях, а возможно и в топах — а это такой немаленький кусок рынка, плюс остальные вроде гугла, мс и прочие со свежими энергоэффективными моделями на арм подтянутся. АРМ начнет так неплохо снизу вытеснять х86, если х86 промолчит в ответ.
что вы будете делать с чипами вшитыми в SoC если завтра ютуб переедет на новый кодек — большая загадка.а что будут делать текущие 2.5 ярда пользователей ведра, 1 ярда iPhone? Видимо страдать.
Это девайсы на пару лет,
это почему же? лично сейчас хожу с айфоном которому 4 года и всё устраивает, у близких и знакомых такая же ситуация.
эти самые 2,5 лярда пользователей,но их больше ведь :) 2.5 google play + 1 iOS + ~1 china.
из-за чего продажи смартфонов и растут на фонерынок уже не растёт. проникновение смартфонов в большинстве стран 100%.
Я согласен, что смартфоны живут в руках меньше чем десктопы, но
1) время жизни смартфонов 4-5 лет, это думаю Гугл будет учитывать это в случае выкатки нового кодека
2) при этом 2/3 НОВЫХ смартфонов строятся на старых чипсетах. А это ещё +2 года к сроку актуализации достижений.
Когда начинает тормозить, то его меняют даже если, оказывается, это всего лишь батарейка села.это раньше было, во времена 4-5-6, у меня 7+ и работает шустрее чем одногодка жены на Snapdragon 835, когда truecaller вешает телефон, или чем прошлогодний RN 8 Note у тестя.
Ну вот они будут выжираться быстре и садиться, вынуждая пользователей сменить на новый не через 3 года, а через полтора.экономическая обстановка этому не способствует.
А вот статистика, что уже как года 3 нет роста продаж смартфонов
МТС: россияне стали реже менять смартфоны
Средний срок владением гаджетов в 2020 году составил 39 месяцев — на 18% больше, чем годом ранее
tjournal.ru/tech/239523-mts-rossiyane-stali-rezhe-menyat-smartfony
неуместным стало:
продайте ваш райзен и rx580 (7-9тысяч + 6-8 тысяч) и поставьте туда AMD Ryzen 5 PRO 4650G — 200$ в российской рознице, будет декодировать 8к замечательно и аппаратно. И заодно на электричестве сэкономите — TDP 65w, против 185+65w.
сомневаюсь, что это кому либо из читателей хабра интересно и хоть как то проходит в русле обсуждения статьи.
От чистого сердца совет, сам бы так и сделал :)
Спасибо, но смысл — шило на мыло менять? Я регулярно обновляюсь — и так чтобы был хороший запас мощности для моих задач на 3,4 года. Пока ещё мне хватает с избытком, а процессор Ryzen 5 PRO 4650G — я не уверен, что его будет хватать мне через 3,4 года. Разумнее подождать 1,5-2 года и обновить платформу под задачи — снова таки с запасом. А play 8k, чтобы выцепить кадр — мне и 15 к/сек. хватает — ведь я не говорил, что это проблема — просто не ожидал тормозов и привел пример к слову.
Ребята из этого офиса могут подсказатьРебята из этого офиса практически гарантированно не могут распространяться про полимеры и вообще будущие продукты.
Встречный вопрос: а почему «полимеры»? Что в вашей жизни изменилось с выходом M1? Или что изменится в ближайшие года три, вы считаете?
С дешевыми ядрами (читай — чиплетами), они тоже уже возятся какое-то время. Так что прогресс идет. Посмотрим, что получится.
Вы точно фанат Apple))
А я эпл хейчу. Вот из недавнего, про Big Sur. www.youtube.com/watch?v=URyWODVhxak
Кстати, как там в 2023, Интел умер, М1 захватил мир?
Ему по прежнему нет альтернатив, захвату мира мешают исключительно заградительные цены: +48ГБ памяти и +4ТБ ssd стоят как три макбука — с дисплеями и другими такими же M1 или даже M2.
А вообще Apple дурак. Mac итак не очень популярны, а Mac с Arm тем более. И что касается производительности, то я сидел на M1 и Core i7, и M1 по крайней мере Intel'у и в подмётки не годится. И вообще, Apple уже делал свои компьютеры на Motorola, PowerPC, x86, x86_64 и это наводит на мысль, может не архитектура виновата, а просто Apple что-то не так делает?
Сейчас, когда вышел уже m4, самое то m1 сравнивать, ага.
Ну и даже в то время - а на чём сравнивали? Нативку х86 на родном интеле и её же на арме через розетту? Полностью нативных арм приложений тогда не сильно много было, в основном родные эпловские. Плюс надо учесть, что m1 - это всего лишь проба пера, там и памяти больше 16 Гб не было. А основной плюс эпл силиконов - в едином чипе, в котором и цпу и гпу и память, что даёт дополнительный прирост производительности.
Гпу же сейчас такое, что можно гамать по вечерам без проблем (уже довольно много игр под мак есть). Даже трассировка лучей есть.
И при всём этом эпл силиконы греются меньше интеловских чипов. У меня макбук м3 про например в простое 40 градусов показывает и стоячие вентиляторы, под нагрузкой - 60-70.
За PowerPC не скажу, а Intel Apple себе выбирала отборные, с интегрированным видео Iris, немаленький видеобуфер которого можно было использовать как дополнительный уровень кеш-памяти. И отказалась от Intel после многократных проблем со стороны производителя.
Да и с Apple Silicon пока всё порядке. Они не так чтобы и особо энергоэффективные, но видимо после уплаты лицензионных отчислений за Arm остаётся чуть больше прибыли, чем при покупке дорогих интелов.
Да и производственные мощности TSMC Apple зарезервировала капитально, выкупив львиную долю передового техпроцесса.
Новый Apple M1, AMD Epyc, AMD Ryzen… Если Intel ничего не предпримет, то мы можем увидеть его закат