
Atomic Regular Expressions
Medium
8 min
Review

Regular expressions have the ability to track the path and some reflection. We'll try to use these features to capture and colorize text parts and output them to the console using AutoHotkey.
Regular expressions have the ability to track the path and some reflection. We'll try to use these features to capture and colorize text parts and output them to the console using AutoHotkey.

Yesterday (November 27), Habr hosted an 'Author's Fireside Chat'.
It was very interesting, and one of the speaker's statements struck me. It was that AI can help write simple pieces of code but doesn't work with complex things. Thus, large language models are likened to a junior programmer.
I decided to write an article about it this morning, drawing on my knowledge and experience in computational mathematics (I used to do modeling in the past, and for the last few years, I've been teaching computational mathematics at MIPT). Let me know what you think.
I think this is the main myth of vibe-coding. It's exactly the opposite — AI is often good at writing quite complex things and retrieving important information that is difficult to find on your own. But it gets confused in the most elementary things. It's a reverse junior.
The problem is that this is a dangerous illusion, and I will now clearly explain why, and how it can be dangerous. Brew some coffee and get ready for a debunking that might save your millions, your career, or even human lives in the future.

What are ANSI codes and how does the terminal process them? Why terminal emulators even exist? How to format the output to PowerShell from AutoHotkey? Let's dive in!

How to write console output algorithm on AutoHotkey, why this language is awesome and what to consider when writing on your high-level language.

What if the “spooky” correlations of quantum entanglement could confirm receipt of a one-way message, ending the acknowledgment (ACK) regress in the Two Generals’ Problem, without sending anything back? This Opinion explains, in everyday terms, why standard quantum mechanics forbids that hope and offers a clear yardstick for testing claims: the quantum trigger, a hypothetical local device that would behave like an ACK if it existed. We show why such a device has zero advantage under the no-signaling rule, unpack how ordinary timing, spectral and physical-emission leakage, shared schedulers, and post-selection can impersonate a “quantum ACK,” and provide quick diagnostics any team can run.

Abstract. This work examines the physical foundations of Ekahau Sidekick measurements and the device offset mechanism from the perspectives of antenna theory, receiver noise theory, statistical signal theory, and the IEEE 802.11 standard family. It is shown that the scalar received signal strength indicator (RSSI) offset constitutes a linear level shift and does not model the true signal-to-noise ratio (SNR) of the client device, the quadrature amplitude modulation (QAM) constellation structure, the rate adaptation algorithm, or roaming behaviour. In addition to five independent physical and systemic sources of inaccuracy, the paper addresses modeling assumptions in Ekahau with respect to multiple-input multiple-output (MIMO) gain, multipath propagation, airtime estimation, and SNR visualisation. Verified numerical error estimates for representative deployment scenarios and practical recommendations are provided.

Mandelbrot set. 32-bit TrueColor. 60 FPS. 80-bit long double. OpenMP. Supersampling 2x2 (4 passes). Color rotation. I want to say. This is the most necessary thing in the Universe. The most profound. And now, in my entire life, I finally started writing code and did it. Quite complex. And the most beautiful. Download and see! It's an executable file, on GitHub.

The Mandelbrot set. And it's a program! I made it in g++, a freely distributable C++ compiler. Read it! Very interesting. Using OpenMP, you do parallel programming at the multithreading level. And I decided - this would be a completely different level of quality! I implemented honest supersampling (antialiasing) - with 8x8 antialiasing (64 passes per pixel!!!) That is, not 1920 by 1920 pixels, but 8x8 more! 15360 by 15360 pixels! And then these 64 passes reduce by one pixel, but smoothly - and no longer 8-bit, but 24-bit TrueColor!

Short video apps have completely reshaped how people consume entertainment. Instead of sitting down for a two-hour movie or a 45-minute TV episode, viewers are now hooked on bite-sized videos that fit into their busy schedules. This shift has been accelerated by Gen Z and Millennials, who prefer quick storytelling formats that are both interactive and engaging.
In 2025, the OTT and short video industry is projected to see over 1.5 billion monthly active users worldwide, with an average revenue per user (ARPU) of nearly $12. The reasons are clear: affordability, accessibility, and convenience. The success of apps like DramaBox shows that people are willing to spend money on shorter dramas as long as they deliver strong storytelling.
For entrepreneurs, this presents a golden opportunity to build OTT platforms like DramaBox and tap into this global demand.

Complex systems often appear chaotic or incomprehensible, yet closer examination reveals that such complexity can frequently be reduced to a simple underlying mechanism. By systematically removing layers of emergent behavior, one can uncover a fundamental rule or equation from which the entire system originates.

Armenia is a lucky country. Back in the 1990s somebody lobbied Synopsys, the #1 leader in the Electronic Design Automation market, to create a division there. It was joined by Mentor Graphics / Siemens EDA, another EDA leader, then NVidia. Synopsys Armenia became the largest Synopsys division outside the US Silicon Valley and Boston, although the Taiwanese may tell you otherwise. Since Synopsys and Mentor make software used by chip designers in Apple, Samsung, AMD and all other electronic companies, Armenia has an unfair advantage over all their neighbors in Caucasus and Central Asia.
In addition, Armenia has friendly relations with Russia, and most Armenians speak Russian as well. This has facilitated the move of many Russian companies to Armenia, for example, a RISC-V semiconductor IP provider Syntacore. Finally, as we can see from the recent conference EDA Connect, Armenia is attracting the attention of electronic and EDA companies from China.
EDA Connect featured not only academic and industrial papers but also a hackathon on FPGA design, attended by local students from Yerevan State University, the American University of Armenia, the Russian-Armenian University, the French University in Armenia and others.

The most common types of software bugs are memory management bugs. And very often they lead to the most tragic consequences. There are many types of memory bugs, but the only ones that matter now are memory leaks due to circular references, when two or more objects directly or indirectly refer to each other, causing the RAM available to the application to gradually decrease because it cannot be freed.
Memory leaks due to circular references are the most difficult to analyze, while all other types have been successfully solved for a long time. All other memory bugs can be solved at the programming language level (for example, with garbage collectors, borrow checking or library templates), but the problem of memory leaks due to circular references remains unsolved to this day.
But it seems to me that there is a very simple way to solve the problem of memory leaks due to circular references in a program, which can be implemented in almost any typed programming language, of course, if you do not use the all-permissive keyword unsafe for Rust or std::reinterpret_cast in the case of C++.
A lot of people around me spend time trading on the stock market. Some trade crypto, some trade stocks, others trade currencies. Some call themselves investors, others call themselves traders. I often see random passersby in various cities and countries checking their trading terminals on their phones or laptops. And at night I sometimes write analytical or backtesting software—well, I did up until recently. All these people share a common faith and a set of misconceptions about the market.

In today's interconnected development world, secure authentication is not just a luxury—it's a necessity. Whether you're a seasoned DevOps engineer or a junior developer just starting your journey, understanding SSH key pairs is crucial for your daily workflow. They're the unsung heroes that keep our git pushes secure, our server access protected, and our deployments safe from prying eyes.
But let's be honest: SSH keys canbe confusing. With terms like “public key infrastructure,” “cryptographic algorithms,” and “key fingerprints” floating around, it's easy to feel overwhelmed. This guide aims to demystify SSH key pairs, breaking down complex concepts into digestible pieces that will help you make informed decisions about your security setup.

OpenStreetMap (OSM) is a global project formed around a geographic information database which is being filled by all comers — both enthusiasts and interested companies. Anybody can contribute, but the openness has its downside: incorrect edits often get into the database. Hence plenty of validators of OSM data have been written which allow to maintain the data quality at an acceptable level.
Since 2016 there exists an open source subway preprocessor that validates (generates error reports) rapid transit routes in OSM for completeness and logical/topological errors, and converts them into formats that are suitable for routing and rendering, e.g. GTFS. Besides OSM data it takes a list of public transport (PT) networks which contains the checking information about the number of lines, stations etc. per a PT network. The preprocessor has successfully proven itself in the preparation of PT data for applications such as Maps.me and Organic Maps.
In this article, I would like to share an approach to detecting one of the types of errors that occur quite often in OSM data and automatic detection of which is somewhat challenging. It's an accidental loss of a station from a route. The source code of the validator and the described algorithm are open source. But first, let's define the concepts used to represent PT data in OpenStreetMap.

The traditional definition for the operation of exponentiation to a natural power (or a positive integer) had introduced approximately as follows:
Exponentiation is an arithmetic operation originally defined as the result of multiple multiplications a number by itself.
But the more precise formulation is still different:
Raising a number X to an integer power N is an arithmetic operation defined as the result of multiple [N by mod times] multiplications or divisions one by number X.
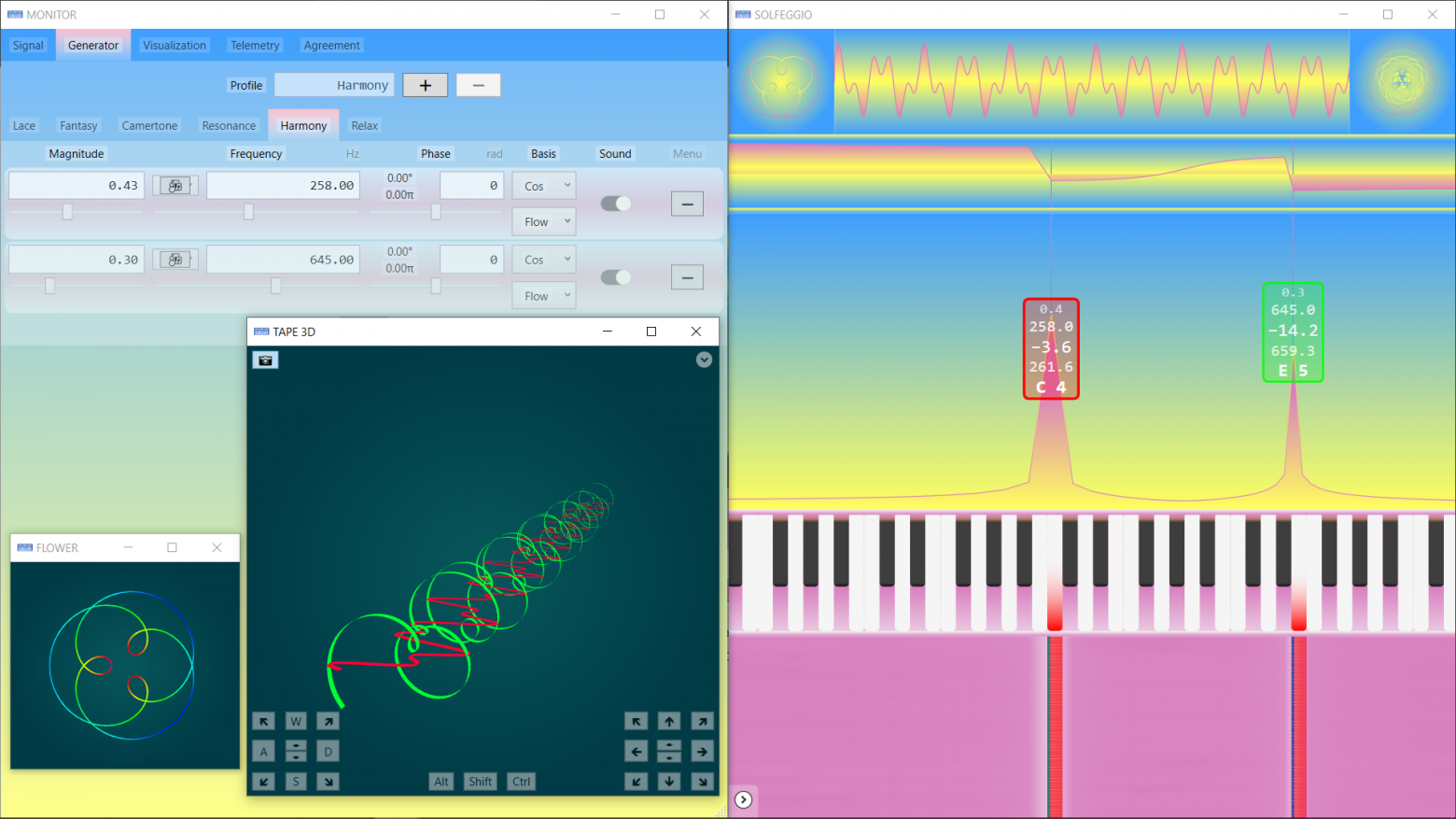
Surprisingly, there are strict mathematical methods that literally allow to hear visual geometric forms and, conversely, to see the beauty of musical harmonies...
The intuition is to employ a depth-first search (DFS) approach through the tree.
During each step in the traversal, we perform the following key calculations:
1. Determine the path that ends at the current node.
2. Compute two different subtree paths that traverse the current node.
3. Maintain an array that keeps track of the cases where paths contain either 0 or 1 prime number.
This method allows us to efficiently count the valid paths in the tree while considering the presence of prime numbers.
Time complexity: O(max(nums) * log(max(nums)) + n * log(n)). Accounting for computing prime scores, using the stack to compute next greater elements, and sorting the tuples.
Space complexity: O(max(nums) + n). Considering the space required for arrays and the stack used for computation.
2809. Min Time to Make Array Sum: Efficient Swift solution, using dynamic programming, for minimizing time to reach a sum in arrays A and B. Time: O(n²), Space: O(n).
2813. Max Elegance of K-Length Subseq: Swift code for elegantly selecting unique k-length subsequences with profit and categories. Solution uses sorting and iteration. Time: O(nlogn), Space: O(n).