In any history textbooks, the modern time has already been called the time of the next change of the industrial structure or the fourth industrial revolution (Industry 4.0). The main role, in this case, is given to information and IT systems. In an attempt to reduce the cost of IT infrastructure, unify and accelerate the process of developing IT solutions, humanity first invented "clouds" in order to replace traditional data centers, and then containers to replace virtual machines.
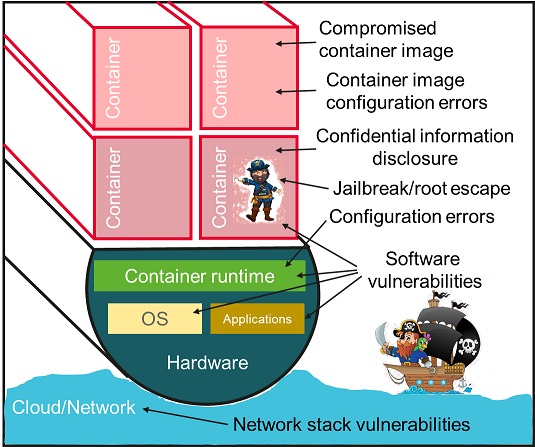
Clearly, containers appear more vulnerable from a security point of view. What are the advantages of containerization over virtualization? In fact, there are quite a lot of them:
• the possibility of more flexible use of available resources (no need to backup them as in the case of virtual machines);
• the ability to save resources (no need to spend them on many copies of the OS for each virtual machine);
• no delays at startup (just start of the process is almost instantaneous compared to the time needed to load the virtual machine);
• the interaction between processes, even if isolated, is much easier to implement when needed than between virtual machines. That is how, by the way, came the concept of microservices, which has recently become very popular.
All of the above led to the very rapid development of container technologies, despite the recurring problems with the security of already deployed container cloud systems, their hacks, and data leaks. Accordingly, the work on strengthening container security is also continuing. This is what will be discussed further in this article.