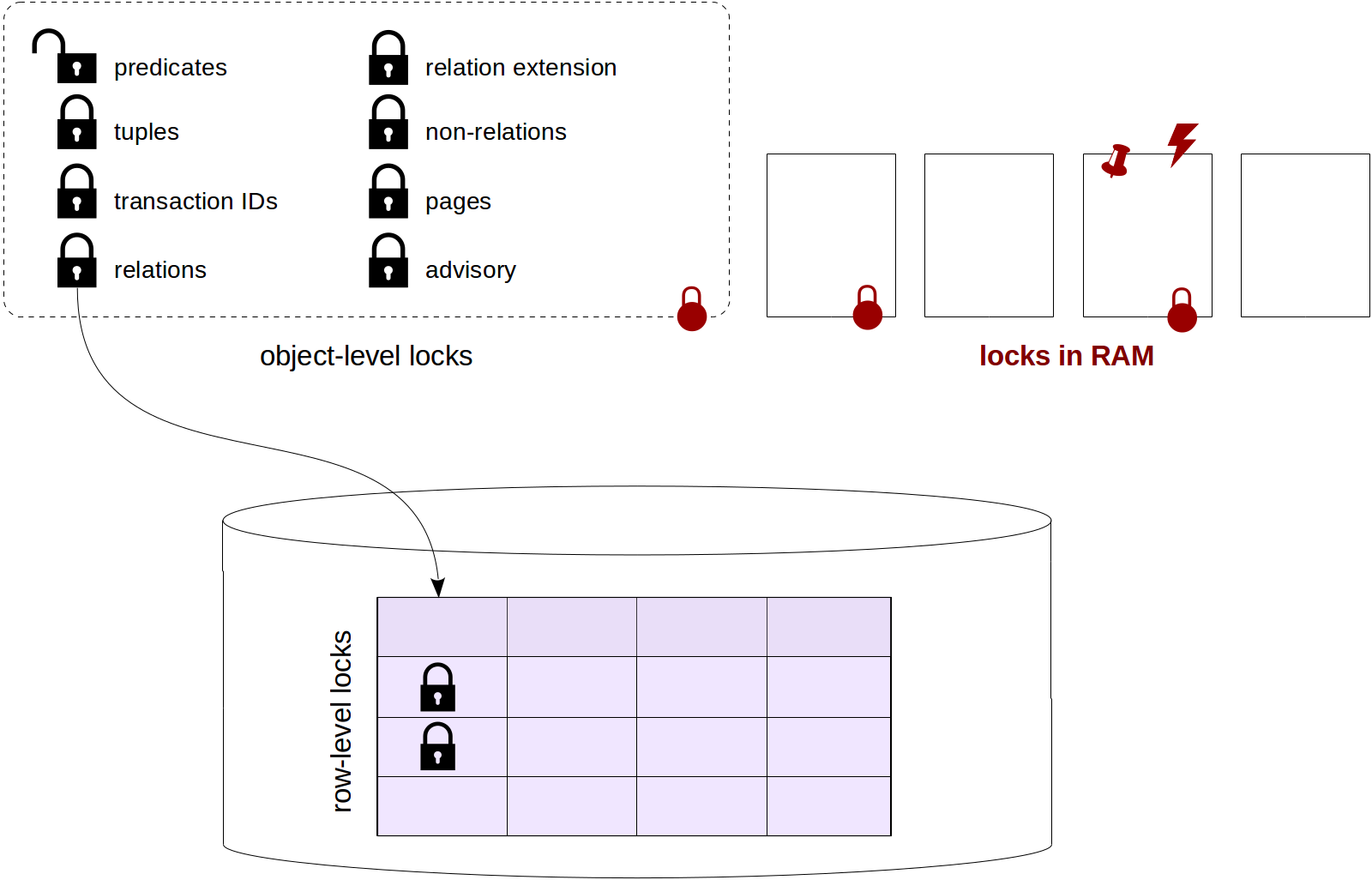
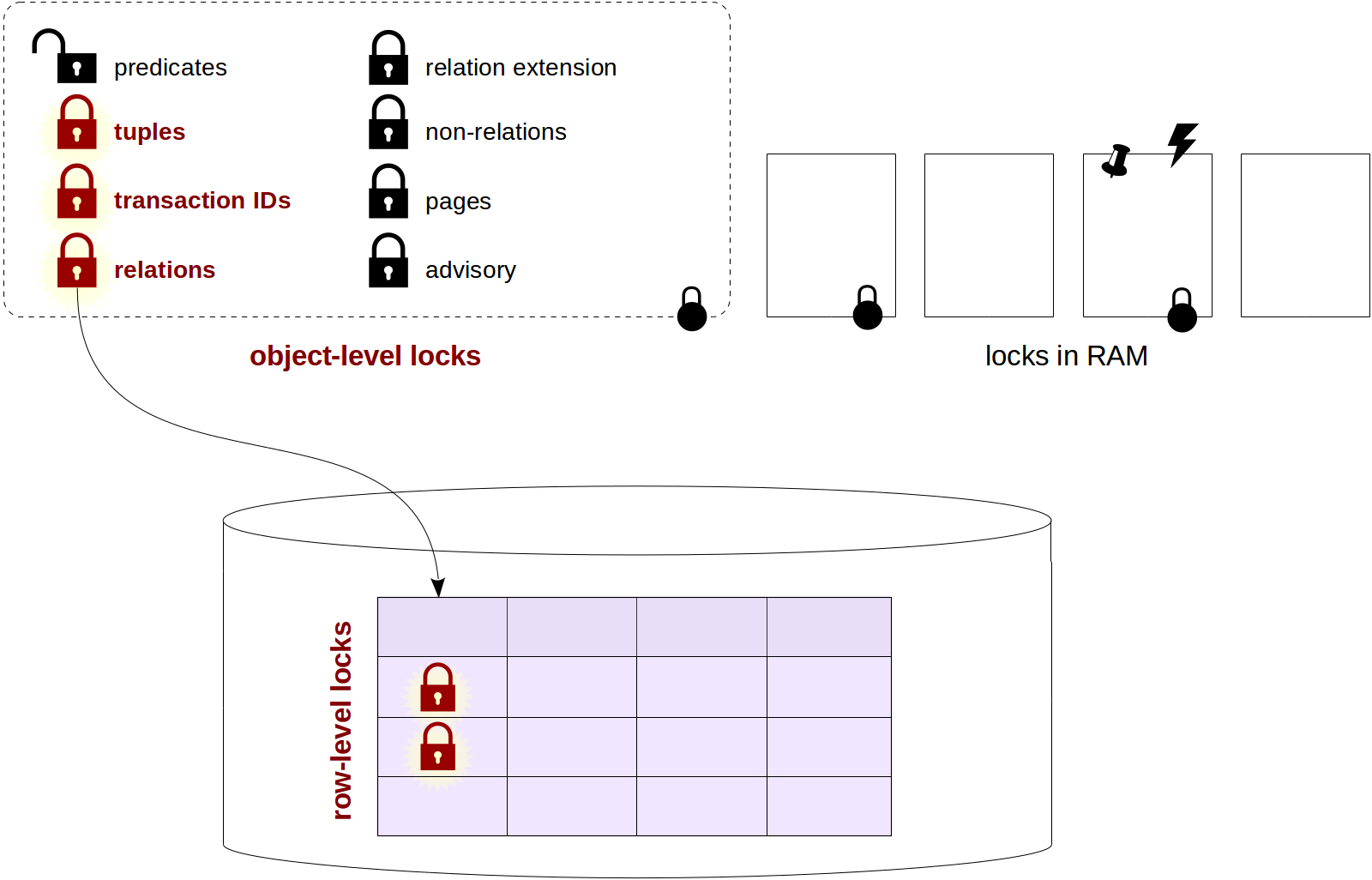
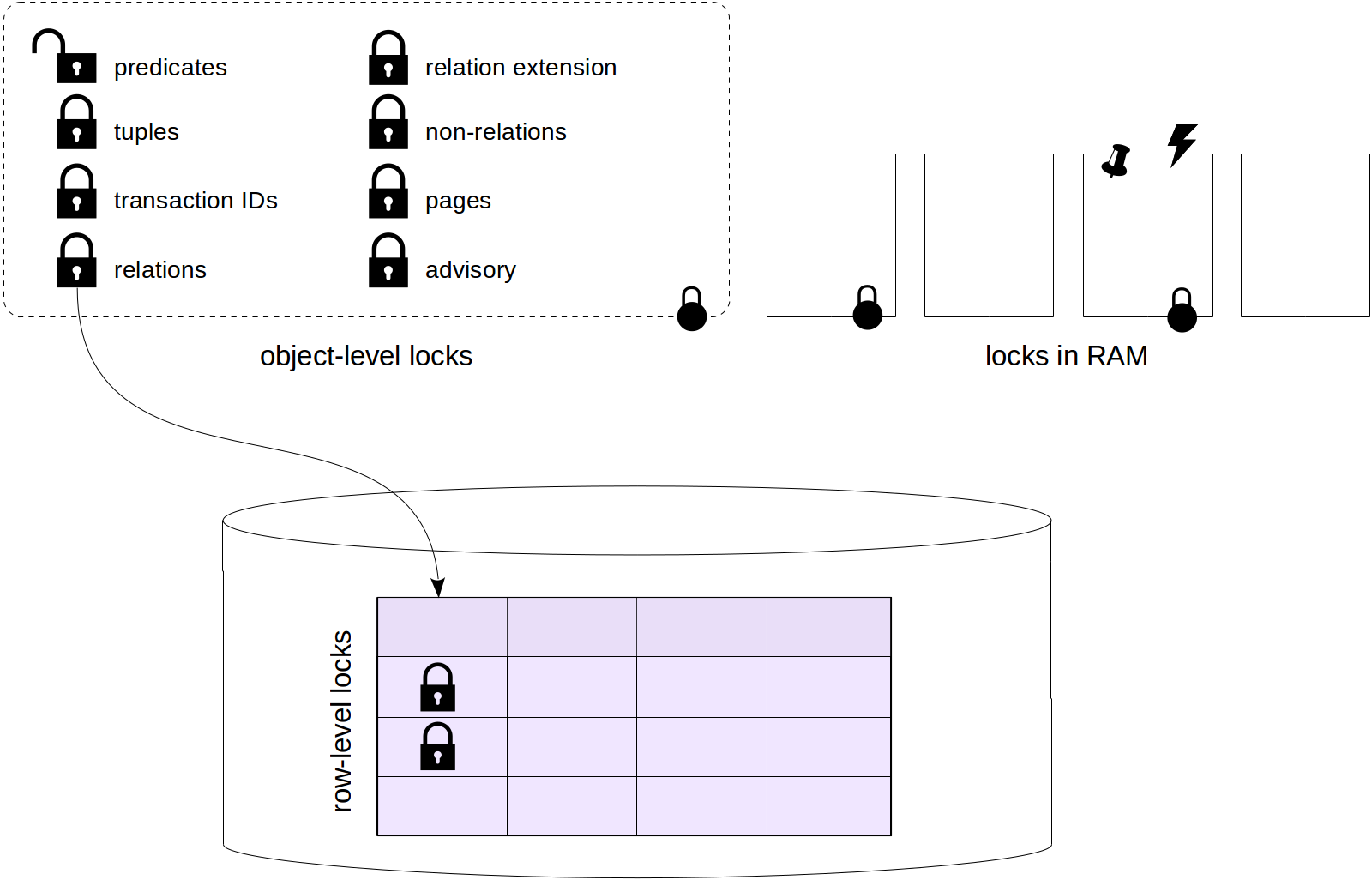
We've already discussed some
object-level locks (specifically, relation-level locks), as well as
row-level locks with their connection to object-level locks and also explored wait queues, which are not always fair.
We have a hodgepodge this time. We'll start with
deadlocks (actually, I planned to discuss them last time, but that article was excessively long in itself), then briefly review
object-level locks left and finally discuss
predicate locks.
Deadlocks
When using locks, we can confront a
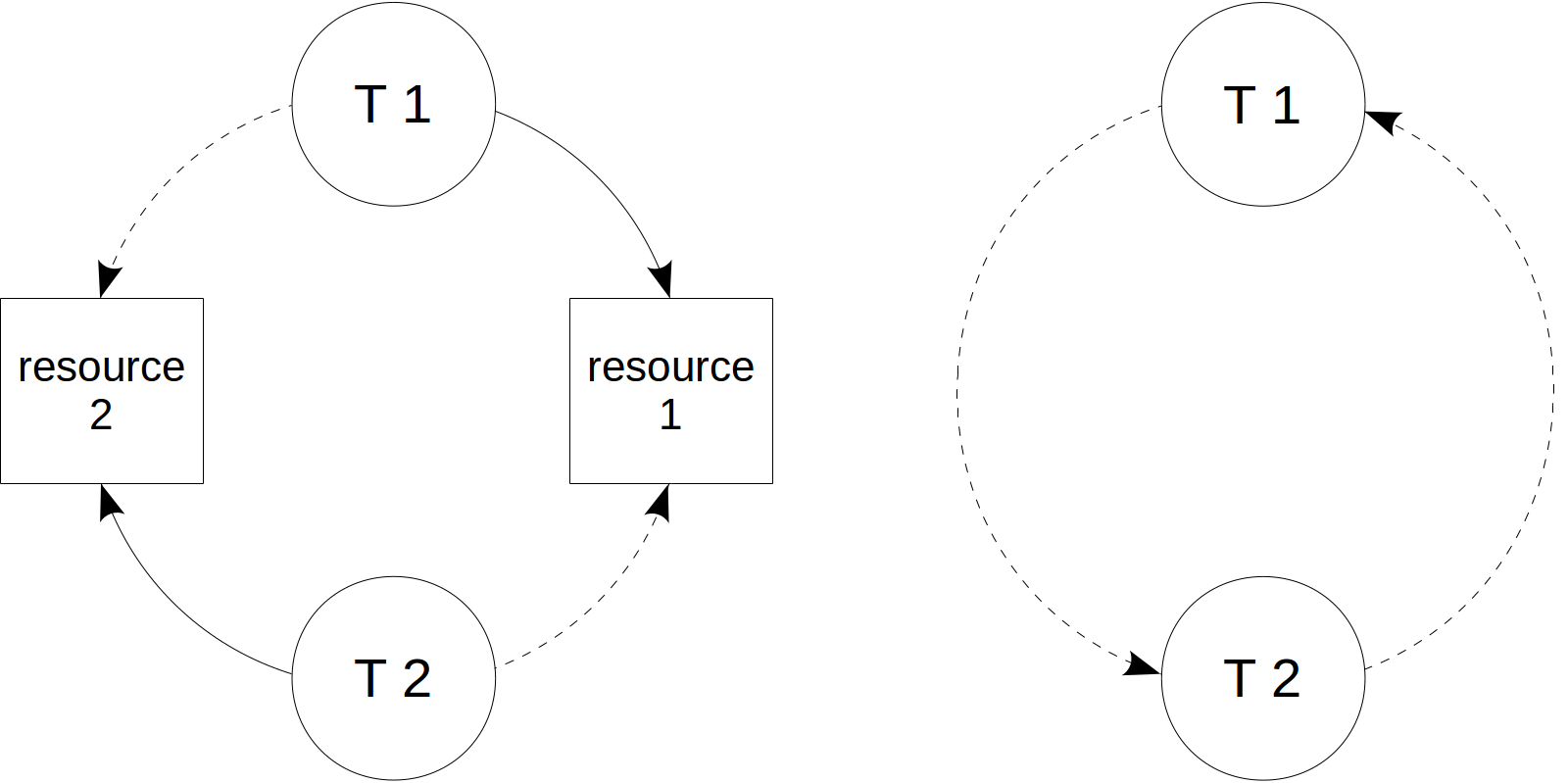
deadlock. It occurs when one transaction tries to acquire a resource that is already in use by another transaction, while the second transaction tries to acquire a resource that is in use by the first. The figure on the left below illustrates this: solid-line arrows indicate acquired resources, while dashed-line arrows show attempts to acquire a resource that is already in use.
To visualize a deadlock, it is convenient to build the wait-for graph. To do this, we remove specific resources, leave only transactions and indicate which transaction waits for which other. If a graph contains a cycle (from a vertex, we can get to itself in a walk along arrows), this is a deadlock.