Comments 629


Сделайте возможным пробел в качестве первого символа значения, иначе у вас ничего не получится.
Имеете ввиду сделать префикс значения не "=" а "= "?
Изначально так и было. И отступы пробелами можно было делать. И переводы строк хоть юниксовые, хоть виндовые. Но что даёт нам этот разброд и шатание? Только усложнение всех систем, которые должны это всё поддерживать. Вот в XML вообще пишут слитно имя атрибута и значение, и никто не возмущается.
У предлагаемого вами разделителя я вижу следующие проблемы:
1. Не очевидно, что пробел не входит в значение и вообще не очень понятно с первого взгляда в какой момент оно начинается.
2. Легко не заметить, что поставил 2 пробела вместо 1
3. Нужно решать, что делать с ситуацией, когда после символа равенства идёт не пробел.
4. +1 бесполезный (не несущий дополнительной семантики, только оформительский) байт на каждое значение.
Изначально так и было. И отступы пробелами можно было делать. И переводы строк хоть юниксовые, хоть виндовые. Но что даёт нам этот разброд и шатание? Только усложнение всех систем, которые должны это всё поддерживать. Вот в XML вообще пишут слитно имя атрибута и значение, и никто не возмущается.
У предлагаемого вами разделителя я вижу следующие проблемы:
1. Не очевидно, что пробел не входит в значение и вообще не очень понятно с первого взгляда в какой момент оно начинается.
2. Легко не заметить, что поставил 2 пробела вместо 1
3. Нужно решать, что делать с ситуацией, когда после символа равенства идёт не пробел.
4. +1 бесполезный (не несущий дополнительной семантики, только оформительский) байт на каждое значение.
> Вот в XML вообще пишут слитно имя атрибута и значение, и никто не возмущается.
Там атрибуты — самый мелкий уровень, важнее отличить их друг от друга, чем имя от значения. Тут ситуация другая.
Большинство проблем надуманные.
1. Можно так же сказать, что неочевидно, входит ли знак равно в значение, или пробел до знака равно в название ключа.
2. С моноширинным шрифтом сложно. А вот легко, например, не заметить проблемы вместо табуляции, однако вас это не смущает.
3. Ничего страшного в отсутствии пробела нет.
4. Без него «человекопонятность» никак не тянет на пятерочку.
Там атрибуты — самый мелкий уровень, важнее отличить их друг от друга, чем имя от значения. Тут ситуация другая.
Большинство проблем надуманные.
1. Можно так же сказать, что неочевидно, входит ли знак равно в значение, или пробел до знака равно в название ключа.
2. С моноширинным шрифтом сложно. А вот легко, например, не заметить проблемы вместо табуляции, однако вас это не смущает.
3. Ничего страшного в отсутствии пробела нет.
4. Без него «человекопонятность» никак не тянет на пятерочку.
Не вижу никакой разницы. Имена и значения в Tree — это практически и есть атрибуты XML.
1. Можно, но куда сложнее.
2. Не сложно, некоторые даже могут начать пытаться выравнивать значения пробелами после символа равенства, как они привыкли делать, например, в JSON. Про пробелы ругнётся либо редактор, когда попытается подсветить синтаксис, либо парсер, когда попытается распарсить.
3. Страшно — когда что-то может быть, а может не быть. Чем чётче синтаксис, тем проще с ним работать.
4. YAML как раз и получился в погоне за «человекопонятностью», а точнее за гламурным отображением. Понятность должна быть не только для человека, но и для машины. При этом машина должна чётко понимать, что имел ввиду человек, а человек должен чётко понимать, как это поймёт машина. Лишний пробел, который кажется вам критически важным, в лучшем случае никак не повлияет на точность понимания ни человеком, ни машиной. А в худшем — внесёт дополнительную неопределённость.
1. Можно, но куда сложнее.
2. Не сложно, некоторые даже могут начать пытаться выравнивать значения пробелами после символа равенства, как они привыкли делать, например, в JSON. Про пробелы ругнётся либо редактор, когда попытается подсветить синтаксис, либо парсер, когда попытается распарсить.
3. Страшно — когда что-то может быть, а может не быть. Чем чётче синтаксис, тем проще с ним работать.
4. YAML как раз и получился в погоне за «человекопонятностью», а точнее за гламурным отображением. Понятность должна быть не только для человека, но и для машины. При этом машина должна чётко понимать, что имел ввиду человек, а человек должен чётко понимать, как это поймёт машина. Лишний пробел, который кажется вам критически важным, в лучшем случае никак не повлияет на точность понимания ни человеком, ни машиной. А в худшем — внесёт дополнительную неопределённость.
Для меня, как для программиста, ратующего за аккуратность кода, конструкция типа
value =2
просто недопустима. Это выглядит ужасно и неаккуратно. Лучше уж «value=2», чем ЭТО.
value =2
просто недопустима. Это выглядит ужасно и неаккуратно. Лучше уж «value=2», чем ЭТО.
А для максимальной аккуратности стоит писать так:
, забросить инженерное дело и заняться дизайном.
Value is equal 2.
, забросить инженерное дело и заняться дизайном.
Не стоит так бросаться на всех, своё же детище так закопаете. В лучшем случае появятся более успешные форки.
Мне лично тоже правильнее смотрятся:
и
Просто потому что приятная симметрия. Второй вариант ещё читается лучше.
Если формат весь из себя такой гибкий, то можно было бы менять поведение парсера через первую строку в файле, а поведение по умолчанию выбрать голосованием.
Мне лично тоже правильнее смотрятся:
user
name=vintage
age=30
и
user
name = vintage
age = 30
Просто потому что приятная симметрия. Второй вариант ещё читается лучше.
Если формат весь из себя такой гибкий, то можно было бы менять поведение парсера через первую строку в файле, а поведение по умолчанию выбрать голосованием.
Чтобы понять, почему именно так, попробуйте представить, что вместо символа "=" используется символ, например, "|". Единственная его функция — не разделять ключ и значение (это хоть и частый, но всего-лишь частный случай), а именно показывать начало потока бинарных данных.
Формат прежде всего простой, потом уже гибкий, а потом уже читабельный и в последнюю очередь компактный. Ни в одной из этих ипостасей он не идеален и при желании (а его я смотрю у хабраюзеров хоть отбавляй) всегда можно найти к чему придраться. Но всё же, на мой взгляд, он представляет из себя неплохой компромис в отличие от остальных упомянутых тут форматов, которые в чём-то хороши, а в чём-то просто отвратительны.
Формат прежде всего простой, потом уже гибкий, а потом уже читабельный и в последнюю очередь компактный. Ни в одной из этих ипостасей он не идеален и при желании (а его я смотрю у хабраюзеров хоть отбавляй) всегда можно найти к чему придраться. Но всё же, на мой взгляд, он представляет из себя неплохой компромис в отличие от остальных упомянутых тут форматов, которые в чём-то хороши, а в чём-то просто отвратительны.
Формат прежде всего простой, потом уже гибкий, а потом уже читабельный и в последнюю очередь компактныйНикого не волнует насколько формат прост в реализации, его пишут 1 раз, обычно вообще есть несколько либ которые все используют, и всем до лампочки насколько формат прост. Формат должен быть в первую очередь читабельным/удобным для редактирования и потом — гибким.
У каждого, работающего с форматом, человека, в голове есть свой маленький криво написанный интерпретатор.
Совершенно верно, но кривизна этого интерпретатора сильно зависит от количества неочевидных моментов в формате. Так вот, в вашем формате такой неочевидный момент в каждом знаке равенства.
От количества правил. Степень очевидности — дело привычки.
Очевидность надо измерять для человека, впервые этот формат увидевшего. А то некоторые и Qr-коды читают, так что, они от этого стали человекопонятными и очевидными?
А чем пробел и знак равенства проще чем просто знак равенства перед значением?
И как реализовать многострочное значение без \n? Только начиная каждую строку со знака пробела и равенства? Не выход.
И как реализовать многострочное значение без \n? Только начиная каждую строку со знака пробела и равенства? Не выход.
Пробел хорошо визуально разделяет узлы и подчёркивает, что знак равенства — это не разделитель ключа и значения, а просто префикс. Другого такого удобного префикса нет (заметьте, что все специальные символы вводятся в любой раскладке нажатием одной клавиши).
Да, именно так. Благодаря префиксам снимаются неоднозначности вида «Обрезать ли ведущий и завершающий переводы строк?», «Обрезать ли отступы?» и «Если обрезать, то на сколько?».
Да, именно так. Благодаря префиксам снимаются неоднозначности вида «Обрезать ли ведущий и завершающий переводы строк?», «Обрезать ли отступы?» и «Если обрезать, то на сколько?».
Тогда получается, что XML выигрывает в возможностях многострочного значения.
А как быть с тем, что поддерживаются только UNIX'овые переводы строк?
А вообще язык меня зацепил, жаль что поддержки нет почти.
А как быть с тем, что поддерживаются только UNIX'овые переводы строк?
А вообще язык меня зацепил, жаль что поддержки нет почти.
<article>
<comment>
<code>Чем же выигрывает?
В нём, например, приходится писать без отступов, чтобы в строки не попало лишнего мусора.</code>
</comment>
</article>
А зачем в современной разработке использовать переводы строк отличные от LF? Не в виндовом блокноте же редактируем код :-)
Речь о библиотеках? Либа на любом языке пилится за несколько часов.
А как по мне — нормально. Разделение до знака равенства есть? Есть. С точки зрения логики так даже лучше, знак = здесь и правда — маркер начала данных. А ещё так получаются визуально две лексемы вместо трёх, что воспринимается чётче. Я согласен с автором)
Полагаю, вы хотели бы обрезать пробелы по краям строки (trim)? Хм, а если значение — это символ пробела? Неоднозначность получается.
Нет, не хотел. Я хотел разрешить пробел перед значением. Если пробел один — это пробел. Если их два — второй уже значение. Никакой неоднозначности.
Неоднозначность заключается в том, что первый символ после символа равенства иногда включается в значение, а иногда не включается. И вы предлагаете усложнить реализацию исключительно из эстетических, но не практических соображений. Но я всё же, я сторонник принципа KISS.
А где пример с не экранированными переносами строк?
Удобство редактирования все так же под вопросом — все эти невидимые символы придется делать видимыми в редакторах.
И еще вопрос, что вы думаете о Tree в сравнении с Lisp-деревьями?
Удобство редактирования все так же под вопросом — все эти невидимые символы придется делать видимыми в редакторах.
И еще вопрос, что вы думаете о Tree в сравнении с Lisp-деревьями?
Примерно так:

О каких невидимых символах идёт речь?
Пример с JSON-AST из статьи — это фактически и есть Lisp-дерево:
Они не так наглядны, как Tree.
О каких невидимых символах идёт речь?
Пример с JSON-AST из статьи — это фактически и есть Lisp-дерево:
[ [ "function",
"getEl",
[ "id" ],
[ "return",
[ [ "get",
"document" ],
[ "call",
"getElementById",
[ "get", "id" ]
]
]
]
]
]Они не так наглядны, как Tree.
Ну т.е. скопировать текст все так же не получится из-за "=" (даже хуже, так как экранирование реализовано везде).
Про невидимые символы: вы не слышали о пробелах и табуляции?) А это значит:
1. Сложности с редактированием документа. Т.е. удобство не 5, а 3 примерно.
2. Значения, не ограниченные ничем могут появляться сами собой (о поверьте, это огромная проблема).
Т.е. одно дело мы используем табуляцию/пробелы в языках программирования — там четкое AST и лишние просто игнорируются, но для данных это беда.
Про невидимые символы: вы не слышали о пробелах и табуляции?) А это значит:
1. Сложности с редактированием документа. Т.е. удобство не 5, а 3 примерно.
2. Значения, не ограниченные ничем могут появляться сами собой (о поверьте, это огромная проблема).
Т.е. одно дело мы используем табуляцию/пробелы в языках программирования — там четкое AST и лишние просто игнорируются, но для данных это беда.
Вырезать по одному символу вначале строки куда проще, чем убрать всё многообразие escape-последовательностей.
1. Вы всегда можете настроить свой редактор, чтобы рисовал табуляцию хоть в 10 символов длиной :-)
2. О чём тут идёт речь?
В Tree тоже чёткое AST. Tree — это и есть самый что ни на есть AST.
1. Вы всегда можете настроить свой редактор, чтобы рисовал табуляцию хоть в 10 символов длиной :-)
2. О чём тут идёт речь?
В Tree тоже чёткое AST. Tree — это и есть самый что ни на есть AST.
Вырезать по одному символу вначале строки куда проще, чем убрать всё многообразие escape-последовательностей.
Допустим я копирую текст из PHP в JavaScript и т.д. \n везде будет переводом строки.
Чтобы убрать \n — мне достаточно простой регулярки заменяющей это на перевод строки (любой редактор). Да, у вас придется заменять перевод_строки= на перевод строки, но в чем достоинство?
По поводу пробелов вы уже ответили ниже habrahabr.ru/post/248147/#comment_8229867 и признаете это проблемой.
Т.е. в итоге лучше б все таки иметь гарантированные \s \t, чем незамеченные пробелы в начале/конце значения данных.
Про AST разница в хранении данных и структуре кода в том, что в коде можно проигнорировать кучу символов (пробелы, переносы строк, табуляцию).
var a = 5; Без разницы сколько тут пробелов до var и после точки с запятой. С данными такое не прокатит.
Допустим я копирую текст из PHP в JavaScript и т.д. \n везде будет переводом строки.
А я, допустим, копирую текст из PHP в HTML и \n больше не будет переводом строки.
Чтобы убрать \n — мне достаточно простой регулярки заменяющей это на перевод строки (любой редактор). Да, у вас придется заменять перевод_строки= на перевод строки, но в чем достоинство?
В данном случае нет никакой разницы, да.
Т.е. в итоге лучше б все таки иметь гарантированные \s \t, чем незамеченные пробелы в начале/конце значения данных.
Только в конце. Проблема куда менее значительная, чем проблема редактирования, когда весь текст в одну строку. И проблема эта вполне решаемая. В любом решении можно найти кучу недостатков, вопрос лишь в том, перевешивают ли достоинства эти недостатки.
var a = 5; Без разницы сколько тут пробелов до var и после точки с запятой.
Ну да, а style guid-ы зачем пишут тогда, раз нет никакой разницы? :-)
И еще, далеко не всегда визуально удобно видеть перенос строки как перенос строки.
Здесь удобнее глазом разделять логические составляющие (переменные), чем собственно само значение.
<locale>
<var name="t1">Прекрасный день\Мы гуляем\nЖизнь боль</var>
<var name="t2">Прекрасный день\Мы гуляем\nЖизнь боль</var>
<var name="t3">Прекрасный день\Мы гуляем\nЖизнь боль</var>
</locale>Здесь удобнее глазом разделять логические составляющие (переменные), чем собственно само значение.
А здесь ключи не надо выискивать в середине строки:

И, кстати, вы не заметили, как опечатались в экранировании :-)
И, кстати, вы не заметили, как опечатались в экранировании :-)
Это не я, честно, это хабр)
Ну все же есть разница в ошибке и в лишнем пробеле в стиле кода?
Не только, опять же habrahabr.ru/post/248147/#comment_8229867
Но при этом на странице видно лишь очень малое количество значений. Для программирования все же важнее работать со структурами, чем с данными — для значений данных другие редакторы.
Ну да, а style guid-ы зачем пишут тогда, раз нет никакой разницы? :-)
Ну все же есть разница в ошибке и в лишнем пробеле в стиле кода?
Только в конце. Проблема куда менее значительная, чем проблема редактирования, когда весь текст в одну строку. И проблема эта вполне решаемая. В любом решении можно найти кучу недостатков, вопрос лишь в том, перевешивают ли достоинства эти недостатки.
Не только, опять же habrahabr.ru/post/248147/#comment_8229867
А здесь ключи не надо выискивать в середине строки:
Но при этом на странице видно лишь очень малое количество значений. Для программирования все же важнее работать со структурами, чем с данными — для значений данных другие редакторы.
Подлый хабр портит первое экранирование в строке :-)
Есть, но всё же несоответствие принятому стилю многими программистами воспринимается не менее рьяно, чем синтаксическая ошибка.
Когда как на самом деле. В конце концов, можно прикрутить автофолдинг к редактору.
Есть, но всё же несоответствие принятому стилю многими программистами воспринимается не менее рьяно, чем синтаксическая ошибка.
Когда как на самом деле. В конце концов, можно прикрутить автофолдинг к редактору.
Есть, но всё же несоответствие принятому стилю многими программистами воспринимается не менее рьяно, чем синтаксическая ошибка.
Соответствие стилю приводится почти любым редактором нажатием одной кнопки. Поэтому разницы нет сколько пробелов там удалится автоматически. Но с данными… Т.е. разница все же есть и большая.
В случае Tree необходимости в нажатии этой кнопки нет, потому как формат практически не допускает вольностей. И это хорошо — не надо всяких бьютификаторов, минификаторов, валидаторов оформления и прочей ерунды.
Ну все правильно, формат допускает только ручное выискивание лишних пробелов и табов — и это вы называете «человекоудобством». Зачем нам стремная автоматизация процесса — даешь перфоленты. Одна ошибка приравнивается к смерти.
Вы слишком гиперболизируете эту проблему. Инструмент, ненавязчиво подсвечивающий концы строк — не такой уж rocket science.
А вы гиперболизируете оценки Tree). Там, где по вашему мнению кавычки, скобки и экранирование мешают восприятию, по моему мнению, способствуют автоматизации и скорости работы. Мы все таки не художественные тексты пишем.
Верно, только тогда все преимущества отсутствия скобок вообще исчезают, так как мы по прежнему видим разделители и должны их мысленно парсить. Так то и кавычки можно сделать ненавязчимыми в JSON.
Инструмент, ненавязчиво подсвечивающий концы строк — не такой уж rocket science.
Верно, только тогда все преимущества отсутствия скобок вообще исчезают, так как мы по прежнему видим разделители и должны их мысленно парсить. Так то и кавычки можно сделать ненавязчимыми в JSON.
JSON плох не только и не столько обилием пунктуации, которую приходится куда-то распихивать (запятую в конце не ставь, открывающую скобку ставим в конце строки, закрывающая висит одиноко в начале и тд).
Ну может и стоит решать эти вопросы? habrahabr.ru/post/248147/#comment_8231413
habrahabr.ru/post/248147/#comment_8230645
Ну и я спрашивала про Lisp в начале обсуждения, вы сказали
Теперь, я надеюсь, я донесла свою точку зрения про наглядность)
У вас не менее жесткий набор правил, только основан на табах, = и пробелах. Или у вас можно 2 переноса строк, 2 "=" писать? Или = написать потом перенос строки и т.д.
habrahabr.ru/post/248147/#comment_8230645
Ну и я спрашивала про Lisp в начале обсуждения, вы сказали
Они не так наглядны, как Tree.
Теперь, я надеюсь, я донесла свою точку зрения про наглядность)
(запятую в конце не ставь, открывающую скобку ставим в конце строки, закрывающая висит одиноко в начале и тд).
У вас не менее жесткий набор правил, только основан на табах, = и пробелах. Или у вас можно 2 переноса строк, 2 "=" писать? Или = написать потом перенос строки и т.д.
Теперь, я надеюсь, я донесла свою точку зрения про наглядность)Когда кругозор сужается до точки, человек называет эту точку «точкой зрения».
Или у вас можно 2 переноса строкМожно
2 "=" писать?Тоже можно.
Или = написать потом перенос строки и т.д.И даже так можно.
Скобки, по-моему, помогают читать сильно структурированный текст — при помощи редакторов с подсветкой скобок типа Notepad++ — и несколько затрудняют-замедляют его написание. Так что неплохо бы ещё и, в виде, например, макроса, иметь «конвертер туда-сюда»…
Мне в принципе понравилась идея. Поддержу дискуссию, тем, что у товарища наверно консоль на 50 строк вот ему все в одну и надо.
В Поддержку Tree могу сказать только одно, мне кажется или вот на таком конфиге json, tree будет выглядеть лучше?
В Поддержку Tree могу сказать только одно, мне кажется или вот на таком конфиге json, tree будет выглядеть лучше?
Много текста
[
{
"title":"Карточка торгов",
"width":6,
"class":"",
"form":[
{
"type":"textbox",
"label":"Наименование",
"required":true,
"validate":{
},
"model":"name",
"width":12
},
{
"type":"datebox",
"label":"Дата публикации в печатном издании",
"required":true,
"validate":{
},
"model":"publish",
"width":12
},
{
"type":"datebox",
"label":"Дата публикации",
"required":true,
"validate":{
},
"model":"publish2",
"width":12
},
{
"type":"datebox",
"label":"Дата публикации №2",
"required":true,
"validate":{
},
"model":"publish3",
"width":12
}
]
},
{
"title":"Карточка должника",
"width":6,
"class":"",
"form":[
{
"type":"selectbox",
"label":"Тип должника",
"required":true,
"validate":{
},
"model":"typepay",
"width":12,
"collection":{
"type":"list",
"mappings":{
"id":"model.id",
"value":"model.value"
},
"data":{
"1":"Физическое лицо",
"2":"Юридическое лицо",
"3":"Индивидуальный предпрениматель"
}
}
},
{
"type":"textbox",
"label":"Фамилия",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"additional":{
"visible":{
"typepay":{
"eq":[1]
}
}
},
"model":"last_name",
"width":6
},
{
"type":"textbox",
"label":"Имя",
"required":true,
"validate":{
},
"padding":"0px 0px 0px 5px",
"additional":{
"visible":{
"typepay":{
"eq":[1]
}
}
},
"model":"first_name",
"width":6
},
{
"type":"textbox",
"label":"Отчество",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"additional":{
"visible":{
"typepay":{
"eq":[1]
}
}
},
"model":"father_name",
"width":6
},
{
"type":"textbox",
"label":"Полное Наименование организации",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"additional":{
"visible":{
"typepay":{
"eq":[2,3]
}
}
},
"model":"full_name",
"width":6
},
{
"type":"textbox",
"label":"Краткое Наименование организации",
"required":true,
"validate":{
},
"padding":"0px 0px 0px 5px",
"additional":{
"visible":{
"typepay":{
"eq":[2,3]
}
}
},
"model":"part_name",
"width":6
},
{
"type":"textbox",
"label":"ОГРН",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"additional":{
"visible":{
"typepay":{
"eq":[2]
}
}
},
"model":"ogrn",
"width":6
},
{
"type":"textbox",
"label":"ОГРНИП",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"additional":{
"visible":{
"typepay":{
"eq":[3]
}
}
},
"model":"ogrn",
"width":6
},
{
"type":"textbox",
"label":"ИНН",
"required":true,
"validate":{
},
"padding":"0px 0px 0px 5px",
"additional":{
"visible":{
"typepay":{
"eq":[1,2,3]
}
}
},
"model":"inn",
"width":6
}
]
},
{
"seperator":"clear"
},
{
"title":"Карточка Орагизнатора",
"width":6,
"class":"",
"form":[],
"file":"app/forms/company_cart.json",
"position":0,
"modelprefix":"company."
},
{
"title":"Сведения об имуществе",
"width":6,
"class":"",
"form":[
{
"type":"textarea",
"label":"Сведения об имуществе на торгах",
"required":true,
"validate":{
},
"model":"info_stuff",
"width":12
},
{
"type":"textarea",
"label":"Порядок ознакомления с имуществом",
"required":true,
"validate":{
},
"model":"oznak",
"width":12
},
{
"type":"textbox",
"label":"Начальная цена продажи",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"model":"start_cash",
"width":6
},
{
"type":"textbox",
"label":"Шаг торгов",
"required":true,
"validate":{
},
"padding":"0px 0px 0px 5px",
"model":"step_cash",
"width":6
}
]
},
{
"seperator":"clear"
},
{
"title":"Порядок оформления участия в торгах",
"width":6,
"class":"",
"form":[
{
"type":"textbox",
"label":"Порядок предоставления заявок",
"required":true,
"validate":{
},
"model":"step_add",
"width":12
},
{
"type":"textbox",
"label":"Место предоставления заявок",
"required":true,
"validate":{
},
"model":"place_add",
"width":12
},
{
"type":"datebox",
"label":"Начало приема заявок",
"required":true,
"validate":{
},
"padding":"0px 5px 0px 0px",
"model":"start_date_add",
"width":6
},
{
"type":"datebox",
"label":"Окончание приема заявок",
"required":true,
"validate":{
},
"padding":"0px 0px 0px 5px",
"model":"end_date_add",
"width":6
},
{
"type":"textarea",
"label":"Порядок оформления участия в торгах",
"required":true,
"validate":{
},
"model":"poradok_oform",
"width":12
},
{
"type":"textbox",
"label":"Размер задатка",
"required":true,
"validate":{
},
"model":"size_precash",
"width":12
},
{
"type":"textbox",
"label":"Информация счета задатка",
"required":true,
"validate":{
},
"model":"info_schet",
"width":12
},
{
"type":"filebox",
"label":"Договор о задатке",
"required":true,
"validate":{
},
"filebox":{
"type_id":"hdogovorzadatok",
"multiple":false,
"nofile":"Договор не выбран",
"type":"type"
},
"model":"dogovor_zadatok",
"width":12
},
{
"type":"datebox",
"label":"Дата начала аукциона",
"required":true,
"validate":{
},
"model":"start_date",
"width":12
}
]
},
{
"title":"Порядки купли-продажи",
"width":6,
"class":"",
"form":[
{
"type":"textarea",
"label":"Порядок и срок заключения договора купли-продажи",
"required":true,
"validate":{
},
"model":"poradok_i_srok",
"width":12
},
{
"type":"textarea",
"label":"Срок платежей, реквезиты",
"required":true,
"validate":{
},
"model":"srok_pay_req",
"width":12
},
{
"type":"filebox",
"label":"Проект договора купли-продажи",
"required":true,
"validate":{
},
"filebox":{
"type_id":"saleresaledogovor",
"multiple":false,
"nofile":"Договор не выбран",
"type":"type"
},
"model":"project_dog",
"width":12
}
]
},
{
"seperator":"clear"
}
]
Чуток промахнетесь и вырежите на строку ниже/выше, а то и из середины — и привет, то, что было на одном уровне внезапно стало дочерним элементом. А JSON/XML вам сразу ошибку нарисует и правильно — нефиг резать не глядя.
Лучше уж ошибочный документ, чем синтаксически правильный, но с некорректными данными. Ошибка — это не разборщик такой-сякой-плохой-нехорошый, а вам знак — что-то не в порядке!
Лучше уж ошибочный документ, чем синтаксически правильный, но с некорректными данными. Ошибка — это не разборщик такой-сякой-плохой-нехорошый, а вам знак — что-то не в порядке!
Может останется, а может и не останется. Смотря какой кусок вырезать. Из любого формата можно вырезать кусок так, чтобы он остался wellformed. Контроль целостности передаваемых данных — это задача транспортного слоя, а не формата описания данных.
Ну да, как-то так:

И так далее.
И так далее.
Такой конфиг и в XML будет выглядеть лучше
Кстати, я тут допилил плагин к IDEA — теперь он и пробелы в конце строк делает видимыми, и на пробелы в начале оных ругается:

По поводу s-expressions (Lisp) скажу — они, на мой взгляд,
бывают (не всегда!) удобнее HTML, XML, JSON и прочего, когда в документе
сравнительно мало текста. Т.е. для, скажем, представления
AST какого-либо языка или для задания layout'а (вёрстки, на которую
ложится CSS, без наполнения) HTML-страницы — очень хорошо.
Скобки — проблема надуманная, при активном
использовании обычно становятся незаметными
недели через две, если, конечно, редактор имеет правильный
autoindent и умеет подсвечивать парные скобки, а при использовании
средств типа paredit скобки неплохо помогают в редактировании.
Проблемы с s-expressions для представления данных / документов
следующие:
JSON по сравнению с s-exprs поддерживает унифицированное представление
dicts (objects), вместо которых в символьных выражениях используются
property lists, association lists либо какой-то кастомный синтаксис, специфичный
для языка (например, Clojure) или приложения (reader macros в CL).
По-моему, это не очень большая проблема, т.к. выразить ассоциативный
массив в виде s-exprs таки не сложно.
С другой стороны, JSON нет стандартных широко поддерживаемых
комментариев и это [очень плохо]. _comment-поля, на мой взгляд — извращение.
бывают (не всегда!) удобнее HTML, XML, JSON и прочего, когда в документе
сравнительно мало текста. Т.е. для, скажем, представления
AST какого-либо языка или для задания layout'а (вёрстки, на которую
ложится CSS, без наполнения) HTML-страницы — очень хорошо.
Скобки — проблема надуманная, при активном
использовании обычно становятся незаметными
недели через две, если, конечно, редактор имеет правильный
autoindent и умеет подсвечивать парные скобки, а при использовании
средств типа paredit скобки неплохо помогают в редактировании.
Проблемы с s-expressions для представления данных / документов
следующие:
- если документ преимущественно текстовый — получается некрасиво;
- по сравнению с XML, не хватает namespaces. В случае CL есть
packages, но их трудно назвать достаточнго гибкой заменой
пространств имён для файлов данных; - tooling — XPath/XQuery/Relax NG/etc. В случае использования s-exprs
для данных обходимся без этих полезняшек или строим велосипеды.
JSON по сравнению с s-exprs поддерживает унифицированное представление
dicts (objects), вместо которых в символьных выражениях используются
property lists, association lists либо какой-то кастомный синтаксис, специфичный
для языка (например, Clojure) или приложения (reader macros в CL).
По-моему, это не очень большая проблема, т.к. выразить ассоциативный
массив в виде s-exprs таки не сложно.
С другой стороны, JSON нет стандартных широко поддерживаемых
комментариев и это [очень плохо]. _comment-поля, на мой взгляд — извращение.
>> выразить ассоциативный массив в виде s-exprs таки не сложно.
Есть же alists:
Есть же alists:
(users
(name . "Alice")
(age . 20))
Ну а как же
(users
(:name "Alice")
(:age 20))
Так я же и написал про association lists выше по тексту. Можно ещё
plists (property lists):
plists (property lists):
(users (:name "Alice" :age 20))
<занудство>
А разве не так:
или
?
Там же ещё может быть
</занудство>
А разве не так:
(users
(user
(name . "Alice")
(age . 20)))
или
(users
((name . "Alice")
(age . 20)))
?
Там же ещё может быть
(users
((name . "Jane")
(age . 21))
((name . "Alice")
(age . 20)))
</занудство>
Нужно сначала показывать продукт, а уже потом сравнивать его с чем-то.
Пришлось промотать в самый низ, чтобы увидеть как выглядит это чудо.
>JSON и YAML для создания иерархий предлагают «списки» и «мапки». Не все структуры данных хорошо представимы с их помощью.
>В Tree есть только один тип узлов
Одним типом узлов, конечно проще описать чем двумя /sarcasm.
А если серьезно, то «списки» это вложенные JSON документы. Какая тут может быть проблема с представлением не понятно.
>Как минимум необходима разноцветная подсветка лексем. Очень помогает — автоформатирование, автодополнение и подсветка ошибок
Использовать Tree без всего этого будет не мене неудобно
>Отсутствие необходимости в экранировании и разэкранировании спецсимволов
Только для \n, видимо?
>Почти все текстовые форматы не совместимы с бинарными данными.
Простите? Что вам мешает хранить «бинарные данные» в JSON?
>В Tree нет комментариев
Мило
>Табуляция
Мило
>Универсальноть
Так и не объяснили что это значит.
Кроме того, как я понимаю, в качестве ключа нельзя использовать blob или даже произвольные «строки», например, включающие символ '='?
В остальном, если без всяких «языков на его основе», то выглядит неплохо. По сути просто json без лишних скобок и кавычек, что радует.
Пришлось промотать в самый низ, чтобы увидеть как выглядит это чудо.
>JSON и YAML для создания иерархий предлагают «списки» и «мапки». Не все структуры данных хорошо представимы с их помощью.
>В Tree есть только один тип узлов
Одним типом узлов, конечно проще описать чем двумя /sarcasm.
А если серьезно, то «списки» это вложенные JSON документы. Какая тут может быть проблема с представлением не понятно.
>Как минимум необходима разноцветная подсветка лексем. Очень помогает — автоформатирование, автодополнение и подсветка ошибок
Использовать Tree без всего этого будет не мене неудобно
>Отсутствие необходимости в экранировании и разэкранировании спецсимволов
Только для \n, видимо?
>Почти все текстовые форматы не совместимы с бинарными данными.
Простите? Что вам мешает хранить «бинарные данные» в JSON?
>В Tree нет комментариев
Мило
>Табуляция
Мило
>Универсальноть
Так и не объяснили что это значит.
Кроме того, как я понимаю, в качестве ключа нельзя использовать blob или даже произвольные «строки», например, включающие символ '='?
В остальном, если без всяких «языков на его основе», то выглядит неплохо. По сути просто json без лишних скобок и кавычек, что радует.
Нужно сначала показывать продукт, а уже потом сравнивать его с чем-то.
Если сразу показать, то типичная реакция: «ой, фу, я так не привык, не хочу дальше читать, пойду напишу в коментах, что люблю json» Тут же я хотел сначала обрисовать недостатки известных форматов, подчеркнув, что в предлагаемом решении их нет. Вы же испортили себе всё впечатление :-)
Одним типом узлов, конечно проще описать чем двумя /sarcasm.
Одним универсальным проще, чем двумя ограниченными. Пример с AST весьма показателен.
Использовать Tree без всего этого будет не мене неудобно
На самом деле менее. В нём сложно написать что-то нечитаемое или допустить синтаксическую ошибку.
Только для \n, видимо?
Экранированием это можно назвать только с натяжкой, но таки да, в остальных форматах экранировать приходится гораздо большее число символов.
Простите? Что вам мешает хранить «бинарные данные» в JSON?
Я так понимаю вы намекаете на base64, base62 и другие способы конвертации бинарных данных в текстовые? Вот собственно эта фаза перекодировки и мешает. Она не позволяет просто потоком вгрузить файл в память и далее просто ссылаться на его участки — обязательно надо выделять отдельные куски памяти для отдельных декодированных значений.
Так и не объяснили что это значит.
Оно складывается из суммы остальных параметров, так что решил его убрать, а вот табличку не поправил, спасибо.
Кроме того, как я понимаю, в качестве ключа нельзя использовать blob или даже произвольные «строки», например, включающие символ '='?
В качестве имени — нельзя. В качестве ключа — можно. Например, аналогом такого JSON:
{
"a+b=c" : [ 0 , true ],
"\"foo\"" : [ 1.1 , false ]
}
Будет такой json.tree:

Не смотря на заявления о простате синтаксиса, он все равно мне кажется непонятным. Возьмем ваш последний пример. Почему значения в списках представлены в виде имен, а не значений? Зачем явно указывать слово list, разве несколько значений не будут на это прямо указывать?
Можно и в виде значений, только тогда придётся как-то различать типы примитивов. Указание чисел и констант в виде имён позволяет не указывать дополнительно эти типы.
Если не указывать list то в случае одного единственного элемента списка будет невозможно понять список там должен быть из одного элемента или же просто этот самый элемент.
Если не указывать list то в случае одного единственного элемента списка будет невозможно понять список там должен быть из одного элемента или же просто этот самый элемент.
> тогда придётся как-то различать типы примитивов
Но здесь же они тоже не различаются. В синтаксисе нет ничего про типы. А где дополнительно нужно описывать тип? Как-то это не вяжется с парсером в 10 паттернов.
Но здесь же они тоже не различаются. В синтаксисе нет ничего про типы. А где дополнительно нужно описывать тип? Как-то это не вяжется с парсером в 10 паттернов.
Типы — это сущности другого уровня — языкового. Для разных языков нужны разные типы, так что не место им на уровне формата.
Типы можно указывать по разному. Например, для языка программирования, где набор типов может расширяться, они могут указываться так:

Но для JSON с фиксированным набором типов и простым способом их различения — это излишне.
Транслятор json.tree в json вполне может проанализировать узел-имя и понять, что там число или булево значение, или null, а вот узлы-значения воспринимать как строки.
Типы можно указывать по разному. Например, для языка программирования, где набор типов может расширяться, они могут указываться так:
Но для JSON с фиксированным набором типов и простым способом их различения — это излишне.
Транслятор json.tree в json вполне может проанализировать узел-имя и понять, что там число или булево значение, или null, а вот узлы-значения воспринимать как строки.
Вам не кажется, что наличие таких уровней ухудшает многие параметры, которые вы оценили на 5. Например, размер в сериализованном виде увеличивается от этих list и map, а человекопонятность и удобство редактирования уменьшается.
Разумеется, JSON модель данных выраженная в Tree формате будет занимать больше места. Точно также Tree модель данных в формате JSON будет будет ещё больше. Это неизбежная цена отображения одного формата на другой.
Только это не JSON модель данных, javascript. И такая модель данных (со строками, числами, логическими константами, массивами и объектами) существует во многих языках. А вот модели данных как в Tree я не встречал.
JS модель данных пошире будет. И вы преувеличиваете универсальность этой модели. Во многих языках в массиве могут быть значения только одного типа. Во многих языках числа и строки представляются множеством разных типов. Во многих языках есть такие структуры как множества, ссылки, матрицы (которые ни разу не массивы массивов). И это я не говорю про многообразие кастомных типов.
Типы можно различать, используя BSON. А он еще и бинарный формат, да, и конвертируется из обычного JSON.
BSON — это всё же чисто бинарный формат. Его и руками в редакторе не поредактируешь и в логах не посмотришь. И вообще с ним работать можно лишь через специальные инструменты.
Ну как это не поредактируешь? Hex-редактор и погнал. Ну а специальные инструменты — это слишком натянуто. Он очень строго типизирован, есть куча готовых реализаций, а своя реализация «на коленке», пишется за пару часов, а то и меньше. С tree тоже придется использовать «специальные инструменты».
UPD: А просматривать можно соответствующий JSON документ.
UPD: А просматривать можно соответствующий JSON документ.
>Если сразу показать
А если не показать, то человеку придется проматывать вниз, чтобы понять о чем вообще речь.
Либо уйти, не читая.
>Тут же я хотел сначала обрисовать недостатки известных форматов, подчеркнув, что в предлагаемом решении их нет. Вы же испортили себе всё впечатление :-)
Нет, не испортил. Таблицу я прочитал до того, как промотал вниз.
Почти в самый конец, потому как в пределах 4 (!!!) экранов не увидел ниодного примера этго чуда,
которое получило оценку 5 почти по всем пунктам
>Одним универсальным проще, чем двумя ограниченными
Чем ограничены эти два формата?
Как уже говорил, «списки», по сути, это вложенные JSON документы.
Массивы это просто синтаксис для таких документов, без необходимости ввода ключей, чтобы не писать в столбик ключи без значений, как вы это делаете в Tree (из примера ниже)
>На самом деле менее.
Вовсе нет. Что там пелена, что здесь.
>В нём сложно написать что-то нечитаемое или допустить синтаксическую ошибку.
Видимо из-за проблем с выразительным средствами.
Как же проблема с = перед значением, которую описала sferrka?
А хранение ключей, которую описал я выше?
А пробелы в ключе, про которые говорил PHmaster ниже?
> форматах экранировать приходится гораздо большее число символов.
У вас перенос строки, если верить примеру выше, просто заменяется на '=', что не сильно лучше \n
Поэтому количество символов, которые нужно экранировать у вас вовсе не меньше, если не больше из-за '='
>Я так понимаю вы намекаете на base64, base62
Нет, не намекаю. Строка в JSON является строкой условно, ничто не мешает вам хранить в ней blob
А если не показать, то человеку придется проматывать вниз, чтобы понять о чем вообще речь.
Либо уйти, не читая.
>Тут же я хотел сначала обрисовать недостатки известных форматов, подчеркнув, что в предлагаемом решении их нет. Вы же испортили себе всё впечатление :-)
Нет, не испортил. Таблицу я прочитал до того, как промотал вниз.
Почти в самый конец, потому как в пределах 4 (!!!) экранов не увидел ниодного примера этго чуда,
которое получило оценку 5 почти по всем пунктам
>Одним универсальным проще, чем двумя ограниченными
Чем ограничены эти два формата?
Как уже говорил, «списки», по сути, это вложенные JSON документы.
Массивы это просто синтаксис для таких документов, без необходимости ввода ключей, чтобы не писать в столбик ключи без значений, как вы это делаете в Tree (из примера ниже)
>На самом деле менее.
Вовсе нет. Что там пелена, что здесь.
>В нём сложно написать что-то нечитаемое или допустить синтаксическую ошибку.
Видимо из-за проблем с выразительным средствами.
Как же проблема с = перед значением, которую описала sferrka?
А хранение ключей, которую описал я выше?
А пробелы в ключе, про которые говорил PHmaster ниже?
> форматах экранировать приходится гораздо большее число символов.
У вас перенос строки, если верить примеру выше, просто заменяется на '=', что не сильно лучше \n
Поэтому количество символов, которые нужно экранировать у вас вовсе не меньше, если не больше из-за '='
>Я так понимаю вы намекаете на base64, base62
Нет, не намекаю. Строка в JSON является строкой условно, ничто не мешает вам хранить в ней blob
Строка в JSON является строкой условно, ничто не мешает вам хранить в ней blobНичего условного в ней нет, в спеке вполне однозначно сказано, что это строка из символов Unicode, причём слеши и кавычки нужно ещё и обязательно экранировать. Так что блоб там хранить можно только предварительно конвертировав его в base64 или что-то подобное.
map — неупорядоченный (ограничение по упорядоченности) ассоциативный (ограничение по уникальности ключей) массив.
list — упорядоченный индексированный (ограничение на индексы — строго последовательно, начиная с 0) массив.
Напомню, что в JSON нужно экранировать:
* перевод строки
* кавычки
* обратный слеш
* пачку управляющих символов
В Tree спецсимвол не допустимый в значениях только один — перевод строки.
list — упорядоченный индексированный (ограничение на индексы — строго последовательно, начиная с 0) массив.
Напомню, что в JSON нужно экранировать:
* перевод строки
* кавычки
* обратный слеш
* пачку управляющих символов
В Tree спецсимвол не допустимый в значениях только один — перевод строки.
Извините, но эти «ограничения» служат для удобства использования и никак не виляют на выразительность.
В то же время в Tree этого всего нет, а значит придется как-то это где-то специфицировать (как отличить сортированный от несортированного?). Введете TSD и Tree Schema?
Это не простота, это бедность.
> пачку управляющих символов
Эти подлежат «экранированию» по причине того, что просто так с клавиатуры их не ввести.
Остальные, действительно, ограничения, накладываемые форматом, здесь вы правы.
Идея использовать практически голые AST как формат хранения данных мне нравится.
Но то, что вы показываете — сильно недоработанная концепция.
И, пожалуй, его главная проблема — амбициозность разработчика, которая формирует соответствующее отношение к самому проекту.
В то же время в Tree этого всего нет, а значит придется как-то это где-то специфицировать (как отличить сортированный от несортированного?). Введете TSD и Tree Schema?
Это не простота, это бедность.
> пачку управляющих символов
Эти подлежат «экранированию» по причине того, что просто так с клавиатуры их не ввести.
Остальные, действительно, ограничения, накладываемые форматом, здесь вы правы.
Идея использовать практически голые AST как формат хранения данных мне нравится.
Но то, что вы показываете — сильно недоработанная концепция.
И, пожалуй, его главная проблема — амбициозность разработчика, которая формирует соответствующее отношение к самому проекту.
Вы зря недооцениваете стек XML технологий. Их разрабатывали куда более умные люди, чем вы или я. И идея разделения языка и формата — очень здравая, потому как позволяет иметь в рамках одного формата тысячи языков, для которых не надо писать отдельные парсеры.
Почему вы решили, что я его недооцениваю? XML хорошо показал себя в свое время, но сейчас ему находят более эффективные альтернативы. В IT все стремится к упрощению. Почему JSON стал так популярен? Потому, что он прост: не нужна никакая схема, не нужно ничего декларировать — просто используй.
>И идея разделения языка и формата — очень здравая
Разве я это отрицал? Я говорил лишь о том, что Tree не решает тех проблем, которые вы нашли в JSON. Во всяком случае, без использования схемы. А если использовать схему, то ваш формат усложняется. Причем это усложнение сразу нивелирует все его плюсы:
1. Он становится слишком неудобным для использования человеком
2. Он начинает конкурировать с BSON (так же «удобно» редактировать руками) и Protobuffers, где «сливает» вообще по всем параметрам.
>И идея разделения языка и формата — очень здравая
Разве я это отрицал? Я говорил лишь о том, что Tree не решает тех проблем, которые вы нашли в JSON. Во всяком случае, без использования схемы. А если использовать схему, то ваш формат усложняется. Причем это усложнение сразу нивелирует все его плюсы:
1. Он становится слишком неудобным для использования человеком
2. Он начинает конкурировать с BSON (так же «удобно» редактировать руками) и Protobuffers, где «сливает» вообще по всем параметрам.
а) А при чём тут схема?
б) В чём проблема запилить схему? Я вам удочку даю, а вы от меня рыбы требуете.
1. Вы попробуйте сначала, а потом уже говорите о неудобности.
2. Вполне себе разумный компромис между компактностью и читаемостью. Всякие BSON и прочие бинарники имеют сильно ограниченное применение. В то время как адекватных применений Tree — гораздо больше.
б) В чём проблема запилить схему? Я вам удочку даю, а вы от меня рыбы требуете.
1. Вы попробуйте сначала, а потом уже говорите о неудобности.
2. Вполне себе разумный компромис между компактностью и читаемостью. Всякие BSON и прочие бинарники имеют сильно ограниченное применение. В то время как адекватных применений Tree — гораздо больше.
>А при чём тут схема?
При том, что ей вы описываете что есть что. Если в языке нет необходимого минимума, то приходится описывать вообще все.
>В чём проблема запилить схему?
Только в том, что это нужно сделать. И чем раньше это «нужно» появится, тем хуже.
>Вы попробуйте сначала, а потом уже говорите о неудобности.
Пробовал уже. Как только вы для этого предложили нечто похожее на формы Бэкуса-Наура.
В связи с чем, кстати, появился вопрос: как вам идея использовать вместо вашего решения bison? Он несравнимо более гибок, да и реализация уже есть. Получаем сразу и описание формата и парсеры под все популярные языки.
>Всякие BSON и прочие бинарники имеют сильно ограниченное применение
Тем не менее в бинарной области они работать будут лучше чем та спецификация Tree, что вы показываете. А в «небинарной» есть JSON (который, кстати, без проблем конвертируется в BSON).
> В то время как адекватных применений Tree — гораздо больше.
Попытка создать инструмент, который делает все, приводит к тому, что он делает все в равной степени плохо. В том смысле, что специализированный инструмент, справился бы с конкретной задачей значительно лучше.
При том, что ей вы описываете что есть что. Если в языке нет необходимого минимума, то приходится описывать вообще все.
>В чём проблема запилить схему?
Только в том, что это нужно сделать. И чем раньше это «нужно» появится, тем хуже.
>Вы попробуйте сначала, а потом уже говорите о неудобности.
Пробовал уже. Как только вы для этого предложили нечто похожее на формы Бэкуса-Наура.
В связи с чем, кстати, появился вопрос: как вам идея использовать вместо вашего решения bison? Он несравнимо более гибок, да и реализация уже есть. Получаем сразу и описание формата и парсеры под все популярные языки.
>Всякие BSON и прочие бинарники имеют сильно ограниченное применение
Тем не менее в бинарной области они работать будут лучше чем та спецификация Tree, что вы показываете. А в «небинарной» есть JSON (который, кстати, без проблем конвертируется в BSON).
> В то время как адекватных применений Tree — гораздо больше.
Попытка создать инструмент, который делает все, приводит к тому, что он делает все в равной степени плохо. В том смысле, что специализированный инструмент, справился бы с конкретной задачей значительно лучше.
Я уже устал повторять, что Tree — это формат, а не язык. Примеры языков в статье есть и для ник вполне чётко определено что есть что.
Идея-то хорошая, но боюсь не найду в ближайшее время времени ковыряться с bison.
Специализированный инструмент справится лучше, только на изучение каждого инструмента нужно время и таскать их все с собой не очень удобно. Плюс ещё и стыкуются они друг с другом плохо.
Идея-то хорошая, но боюсь не найду в ближайшее время времени ковыряться с bison.
Специализированный инструмент справится лучше, только на изучение каждого инструмента нужно время и таскать их все с собой не очень удобно. Плюс ещё и стыкуются они друг с другом плохо.
>Я уже устал повторять, что Tree — это формат, а не язык
Извините, что утомил вас. Не волнуйтесь, я помню, и это очевидно из его сравнение с JSON, XML, YAML.
Перефразирую: если формат не предоставляет достаточно конструкций сам по себе, то их придется где-то описывать. Пример с массивами: да, в JSON они нумеруются от 0 и только так. Но в Tree такого нет вообще. Нигде не написано, являются ли дочерние узлы упорядоченными или нет и какие им даются индексы. А это значит, что придется вводить новую спецификацию (схему), для того, чтобы это описать.
Если вы подразумеваете, что в чистом виде он никогда не будет использоваться, то презентуйте его как мета-формат.
>только на изучение каждого инструмента нужно время
Даже если описать все эти языки в рамках одного формата, это не делает изучение более простым
>таскать их все с собой не очень удобно
Как это отличается от все-в-одном?
>Плюс ещё и стыкуются они друг с другом плохо
Весьма спорное утверждение. Все зависит от конкретного случая.
Напомню, что сама идея, мне нравится. Мне не нравится её текущая реализация и тот факт, что эту реализацию пытаются выдать за «убийцу» вышеперечисленных форматов.
Извините, что утомил вас. Не волнуйтесь, я помню, и это очевидно из его сравнение с JSON, XML, YAML.
Перефразирую: если формат не предоставляет достаточно конструкций сам по себе, то их придется где-то описывать. Пример с массивами: да, в JSON они нумеруются от 0 и только так. Но в Tree такого нет вообще. Нигде не написано, являются ли дочерние узлы упорядоченными или нет и какие им даются индексы. А это значит, что придется вводить новую спецификацию (схему), для того, чтобы это описать.
Если вы подразумеваете, что в чистом виде он никогда не будет использоваться, то презентуйте его как мета-формат.
>только на изучение каждого инструмента нужно время
Даже если описать все эти языки в рамках одного формата, это не делает изучение более простым
>таскать их все с собой не очень удобно
Как это отличается от все-в-одном?
>Плюс ещё и стыкуются они друг с другом плохо
Весьма спорное утверждение. Все зависит от конкретного случая.
Напомню, что сама идея, мне нравится. Мне не нравится её текущая реализация и тот факт, что эту реализацию пытаются выдать за «убийцу» вышеперечисленных форматов.
Вместо того, чтобы хардкодить некоторые типы (например, строки, числа, булевы), а с остальными (например, даты, телефонные номера, гео-координаты) ковыряйтесь как хотите, на мой взгляд лучше дать инструмент объявления своих типов и не навязывать какой-либо набор, «которого хватит всем». Посмотрите на описание языка xml.tree — оно же предельно простое, хоть и не формализованное с помощью каких-либо схем.
Изучить новый словарь для знакомого синтаксиса куда проще, чем изучить новый синтаксис.
А вы зря недооцениваете универсальные инструменты. Возьмём вот например нож. Есть нож для рыбы, для мяса, для сыра, для хлеба, для разделки, для удаления костей, для раскрытия раковин устриц, тысячи их. Каждый из них предельно хорош в своей области. А тут прихожу я и говорю, что вот этими двумя типами ножей можно делать всё что угодно. Пусть и не будет того повышенного комфорта, как при использовании устричного ножа. Зато ножи будут взаимозаменяемы, требовать мало места, их не придётся менять каждые 5 минут, подбирая нужный для своего типа нарезаемого продукта.
Изучить новый словарь для знакомого синтаксиса куда проще, чем изучить новый синтаксис.
А вы зря недооцениваете универсальные инструменты. Возьмём вот например нож. Есть нож для рыбы, для мяса, для сыра, для хлеба, для разделки, для удаления костей, для раскрытия раковин устриц, тысячи их. Каждый из них предельно хорош в своей области. А тут прихожу я и говорю, что вот этими двумя типами ножей можно делать всё что угодно. Пусть и не будет того повышенного комфорта, как при использовании устричного ножа. Зато ножи будут взаимозаменяемы, требовать мало места, их не придётся менять каждые 5 минут, подбирая нужный для своего типа нарезаемого продукта.
>Возьмём вот например нож
приятно видеть человека, видящего перспективность метафорического компьютера :)
данные: дождевая, вода из-под крана, столовая питьевая, минеральная, газированная сладкая, дистиллированная, вода из лужи, морская, речная, фильтрованная…
дистиллированная вода — бинарные данные
вода из-под крана — данные, вводимые пользователем
формат: мыло, шампунь, ополаскиватель, гель для душа стиральный порошок, средство для мыться посуды, зубная паста, крем для бритья средство для мытья ковров, средство для пола, средство для унитаза, средство для мытья стекол…
при смешении воды и средства получаем данные в формате
инструмент: щетка для обуви, зубная щетка, половая тряпка, веник, губка для мытья посуды, скребок для мытья посуды, расческа, щетка для пылесоса, пемза, полотенце…
То есть, вы утверждаете, что ваш формат — это мыло.
А ваши оппоненты, что не хотят употреблять молоко в формате сыворотка, когда есть еще масло, сметана, творог, сливки.
почему бы не провести опрос.
приятно видеть человека, видящего перспективность метафорического компьютера :)
данные: дождевая, вода из-под крана, столовая питьевая, минеральная, газированная сладкая, дистиллированная, вода из лужи, морская, речная, фильтрованная…
дистиллированная вода — бинарные данные
вода из-под крана — данные, вводимые пользователем
формат: мыло, шампунь, ополаскиватель, гель для душа стиральный порошок, средство для мыться посуды, зубная паста, крем для бритья средство для мытья ковров, средство для пола, средство для унитаза, средство для мытья стекол…
при смешении воды и средства получаем данные в формате
инструмент: щетка для обуви, зубная щетка, половая тряпка, веник, губка для мытья посуды, скребок для мытья посуды, расческа, щетка для пылесоса, пемза, полотенце…
То есть, вы утверждаете, что ваш формат — это мыло.
А ваши оппоненты, что не хотят употреблять молоко в формате сыворотка, когда есть еще масло, сметана, творог, сливки.
почему бы не провести опрос.
Почему JSON стал так популярен? Потому, что он прост: не нужна никакая схема, не нужно ничего декларировать — просто используй.
На самом деле, не поэтому, а потому, что на веб-клиенте (в браузере) его парсинг был существенно проще и дешевле, чем парсинг xml.
(xml тоже можно использовать без схемы и деклараций, если что)
или всё же потому, что это серилизатор для ЯваСкрипта? )))
Это не «сериализатор для яваскрипта», это сериализатор, который в некий момент решили использовать в JavaScript как самый простой (потому что чтобы разобрать этот формат, если без учета безопасности, достаточно сделать
eval)ок, делали не столько для ЯваСкрипта.
Но получил популярность потому, что очень прост для ЯваСкрипта.
Тот же XML надо вначале распарсить в ДОМ, а уж потом из него вытаскивать данные для скриптов, а с использованием жсона — всё уже распакованно.
Но получил популярность потому, что очень прост для ЯваСкрипта.
Тот же XML надо вначале распарсить в ДОМ, а уж потом из него вытаскивать данные для скриптов, а с использованием жсона — всё уже распакованно.
А теперь перечитайте, что написано в комменте, на который вы отвечаете:
потому, что на веб-клиенте (в браузере) его парсинг был существенно проще и дешевле, чем парсинг xml.
>вначале распарсить в ДОМ
SAX
SAX
SAX на javascript?
Но получил популярность потому, что очень прост для ЯваСкрипта.
То есть DOM на js вас не смущает?
>Но получил популярность потому, что очень прост для ЯваСкрипта.
К чему вы это?
>Но получил популярность потому, что очень прост для ЯваСкрипта.
К чему вы это?
Разумеется, DOM на js меня не смущает.
По распакованному JSON всё-равно придётся пройтись и преобразовать во внутреннее представление (объектики там всякие, перекрёстные ссылки и тд). Так что особой разницы нет по какому дереву бегать — json, tree или xml.
ko.mapping.fromJS(responceJson, viewModel);
А в чём проблема?
Проблема в том, что распакованный JSON — это объект, который можно напрямую отображать на модель. На выходе же парсера tree — дерево узлов, которые требуется обрабатывать дополнительно.
Беспредметный спор. Покажите как вы отобразите JSON модель данных на модель предметной области «на прямую». А я сделаю аналогичное отображение из Tree. А потом сравним у кого сколько «дополнительного» кода получилось.
Я же написал выше. Между прочим, реально используемый код.
koko.mapping.fromTree(responceTree, viewModel);
Приведите библиотеку. А то по запросу «koko.mapping.fromTree» гуглится какая-то фигня, а без библиотеки сравнить количество «дополнительного» кода не получается.
А что толку? Реализация будет точно такая же — через паттерн Visitor.
Какой Visitor в гомогенном дереве, о чем вы?
Где вы увидели гомогенное дерево?
Ваш Tree — это гомогенное дерево (это то его достоинство, которым вы так гордитесь)
>xml тоже можно использовать без схемы и деклараций
Не спорю, можно. Но несколько сложнее, взять хотя бы проблему выбора между атрибутом и дочерним элементом.
Хотя, пожалуй, вы правы.
Не спорю, можно. Но несколько сложнее, взять хотя бы проблему выбора между атрибутом и дочерним элементом.
Хотя, пожалуй, вы правы.
А можно пример того как ваш формат дружит с бинарными данными.
Пример программного кода или пример файла?
Пример файла конечно, зачем мне код.

Отлично, а что будет если в бинарных данных один из символов будет \n?
Очевидно, вместо одного узла-значения будет несколько.
Это если за \n последует такое же количество табов (что мало вероятно), а если попутно ещё и = встретится так это сделает всё ещё хуже. Что то не вижу я бинарной безопасности в вашем формате.

То есть мне придётся самому в коде разбивать данные на блоки? А чем это лучше экранирования " и \ в json?
Зачем самому, если это можно делать автоматически?
json тоже это сам делает
Разумеется. Вопрос в стоимости этой операции и человекочитаемости.
Стоимость этой операции в обоих случаях O(n). В чем вопрос?
Вопрос в размере константы.
Во-первых, не в размере константы, а в отношении размеров констант. И вы не сможете адекватно посчитать k для JSON-кодировщика, потому что его реализация очень сильно зависит от возможностей платформы и изворотливости программиста.
Во-вторых, в то время как стоимость кодирования в JSON зависит только от самой строки, в Tree она зависит от строки и ее места в иерархии, что тоже не добавляет счастья.
Нотацию O(f(n)) для того и придумали, чтобы не размениваться на такие мелочи. Для разумной реализации на разумном языке стоимость кодирования и декодирования строкового примитива что в Tree, что в JSON будет сопоставима, и отличия будут вноситься больше на уровне «читаем из буфера vs читаем из потока».
Во-вторых, в то время как стоимость кодирования в JSON зависит только от самой строки, в Tree она зависит от строки и ее места в иерархии, что тоже не добавляет счастья.
Нотацию O(f(n)) для того и придумали, чтобы не размениваться на такие мелочи. Для разумной реализации на разумном языке стоимость кодирования и декодирования строкового примитива что в Tree, что в JSON будет сопоставима, и отличия будут вноситься больше на уровне «читаем из буфера vs читаем из потока».
В JSON многие символы требуют экранирования, что вынуждает работать с байтами индивидуально. Tree же позволяет копировать данные пачками, что гораздо быстрее.
Каким образом вы гарантируете, что в «пачке» нет переводов строки, если не пройдетесь по каждому байту индивидуально?
Если пачка прочитана из Tree файла, или через readln(), то переводов строк там точно нет. Если же у нас дикие данные, то при импорте в дерево необходимо пробежаться по ним в поисках переводов строк. Поиск символа в строке — это куда более быстрая операция.
При импорте в дерево вам нужно не просто «пробежаться… в поисках переводов строк», а точно так же, как и с экранированием, при каждом встреченном символе перевода строки добавить дополнительные символы экранизации: в вашем случае это табы и символ "=", и добавляются они не перед экранируемым символом, а после него. Причем, заметьте, вы не можете экранировать данные и затем вставить их в любое произвольное место в ваше дерево, как это возможно с тем же JSON, так как количество вставляемых в Tree табов после символа перевода строки зависит от контекста, т.е. конкретного места, для которого вы экранируете, а именно — от уровня вложенности объектов в этом месте. А это, в свою очередь, означает, что вы не можете взять некий объект, сериализировать его в Tree-представление и потом использовать сериализованный кусок текста в произвольном месте Tree-файла (или любого другого потока вывода), как это возможно с тем же json и XML. То есть, для сериализации объектов нужно заранее знать всю структуру сериализуемого дерева этих объектов целиком, и при сериализации обходить эту структуру в строгом порядке: от корня к листьям.
При импорте в дерево не происходит экранирования — только составление списка диапазонов.
Функция split не копирует данные, если что, а возвращает так называемые срезы исходного массива.
При сериализации они просто сливаются в выходной поток как есть, без какой-либо обработки.
static Values
( T = string )
( T value , Tree[] childs = [] , string uri = "" )
{
auto chunks = ( cast(string) value ).split( '\n' );
auto nodes = chunks.map!( chunk =>
new Tree( "" , chunk , [] , uri )
);
return nodes.array;
}
Функция split не копирует данные, если что, а возвращает так называемые срезы исходного массива.
При сериализации они просто сливаются в выходной поток как есть, без какой-либо обработки.
} else if( this._value.length || prefix.length ) {
output.write( "=" ~ this._value ~ "\n" );
}
В таком слчае так можно сказать про любое другое экранирование, вот например простейшие экранирование " и \
и потом
Имеются ли тут кардинальные различия? Не думаю.
static Values
( T = string )
( T value , Tree[] childs = [] , string uri = "" )
{
auto chunks = ( cast(string) value ).split( "\"\\" );
auto nodes = chunks.map!( chunk =>
new Tree( "" , chunk , [] , uri )
);
return nodes.array;
}
и потом
} else if( this._value.length || prefix.length ) {
output.write( "\\" ~ this._value);
}
Имеются ли тут кардинальные различия? Не думаю.
У вас при сплите данные теряются. Если разрезать по более чем одному символу, то потом не понятно по какому символу собирать.
ну так всегда можно свой split написать который не будет обрезать символы, я просто хотел показать, что по сути экранирование ничем не отличается от вашего разделения.
Экранирование в JSON отличается. Да, можно придумать экранирование, где перед кавычкой и бэкслешем ставится бэкслеш и всё, но чем это:
Лучше этого:
?
{ "lalala" :
"foo\"
bar\\"
}
Лучше этого:
lalala
=foo"
=bar\
?
Не позволяет. Вам нужно знать, где в данных
Так что утверждение про сопоставимые сложности алгоритмов остается неопровергнутым.
\n, поэтому у вас не выйдет «просто прочитать» или «просто записать». Это все те же самые O(n) (а когда вы говорите про «прочитано через readln» — то для вас эта сложность просто спрятана внутрь вызываемой функции; но это не значит, что ее нет).Так что утверждение про сопоставимые сложности алгоритмов остается неопровергнутым.
Я с ним и не спорил. Речь о константах. Вы по ссылке ходили? Разница на порядок.
Ходил, а толку? Эта ссылка не применима в вашем случае, потому что она относится к копированию целых массивов в памяти.
А у вас что? У вас
(а) копировать надо не весь массив, а до определенной позиции
(б) вы, на самом деле, вообще ничего не копируете, а либо читаете, либо пишете с/на I/O-устройство (сеть, диск и так далее), и стоимость самого I/O выше, чем стоимость всех операций сравнения, которые надо сделать (а больше отличий-то и нет)
А у вас что? У вас
(а) копировать надо не весь массив, а до определенной позиции
(б) вы, на самом деле, вообще ничего не копируете, а либо читаете, либо пишете с/на I/O-устройство (сеть, диск и так далее), и стоимость самого I/O выше, чем стоимость всех операций сравнения, которые надо сделать (а больше отличий-то и нет)
Вы не на палец смотрите, а туда, куда я показываю :-)
Это иллюстрация, что обработка сразу пачки данных куда эффективней побайтовой обработки.
Это иллюстрация, что обработка сразу пачки данных куда эффективней побайтовой обработки.
Эффективнее, конечно. Но для бинарно-небезопасных форматов это в чистом виде невозможно в любом случае. Поэтому все равно в том или ином виде будет обработка экранирующих последовательностей — которая, как уже говорилось, сводится к O(n) (с чем вы, впрочем, уже согласились). Дальше вопрос k. Вы утверждаете, что для JSON, в котором экранируемых символов больше, k существенно больше, чем для tree. А я утверждаю, что в типовых применениях эта разница не будет заметна на фоне стоимости основной операции (i/o).
Внимание, вопрос: будем на уровне логики обсуждать, или уже пора тесты писать?
Внимание, вопрос: будем на уровне логики обсуждать, или уже пора тесты писать?
i/o между процессами заключается именно что в копировании памяти.
Внезапно, tree предлагается для межпроцессной комуникации? А зачем? Там чистый бинарный формат намного эффективнее.
Я всегда считал, что основные применения таких форматов — это прочитай/запиши на диск, в БД или в сеть.
Я всегда считал, что основные применения таких форматов — это прочитай/запиши на диск, в БД или в сеть.
Для интероперабельности.
Например, unix pipes.
Например, unix pipes.
Вы правда думаете, что unix pipes работает через копирование памяти? Странно, а я думал, что оно сделано через потоки (точнее, через форвард-онли файл-дескрипторы).
Я правда думаю, что дерево сериализуется в память и парсится из неё же, без обращения к диску.
Во-первых, далеко не факт, что это быстрее. Во-вторых, когда вы сериализуете и парсите дерево в памяти, у вас парсинг отдельно, копирование — отдельно, и поэтому оно в обоих алгоритмах является константой (благодаря чему радостно игнорируется O-нотацией). Ну и в-третьих, при чем тут диск, мы вроде как о unix pipes говорим?
Ладно, чтобы не заниматься дурацкими вопросами, напишите, пожалуйста, в псевдокоде, как, по-вашему, будет происходить процесс сериализации — передачи через unix pipe — десериализации данных, с указанием того, где именно копируется память.
Ладно, чтобы не заниматься дурацкими вопросами, напишите, пожалуйста, в псевдокоде, как, по-вашему, будет происходить процесс сериализации — передачи через unix pipe — десериализации данных, с указанием того, где именно копируется память.
В случае tree:
При парсинге копировать ничего не нужно.
При сериализации просто копируются участки памяти в выходной буфер.
В случае json:
При парсинге происходит декодирование, для чего выделяется отдельная память.
При сериализации происходит кодирование и запись в буфер.
При парсинге копировать ничего не нужно.
При сериализации просто копируются участки памяти в выходной буфер.
В случае json:
При парсинге происходит декодирование, для чего выделяется отдельная память.
При сериализации происходит кодирование и запись в буфер.
Не так быстро.
Во-первых, почему ничего не надо копировать при парсинге tree?
Во-вторых, где пайп-то?
В-третьих, откуда вы берете участки памяти для копирования в выходной буфер? Вот у вас на входе строка, потенциально содержащая \n — откуда вы знаете, какие ее куски надо копировать?
Во-первых, почему ничего не надо копировать при парсинге tree?
Во-вторых, где пайп-то?
В-третьих, откуда вы берете участки памяти для копирования в выходной буфер? Вот у вас на входе строка, потенциально содержащая \n — откуда вы знаете, какие ее куски надо копировать?
1. А зачем?
2. За кулисами. Пайплайном управляет операционка.
3. Из входного буфера и беру. Как бы tree-парсер строит дерево по входящему потоку — отсюда и знаю, где что.
2. За кулисами. Пайплайном управляет операционка.
3. Из входного буфера и беру. Как бы tree-парсер строит дерево по входящему потоку — отсюда и знаю, где что.
А зачем?
Ну то есть данные из входного потока попадают в структуру в памяти чудом?
За кулисами. Пайплайном управляет операционка.
Ага, то есть фраза «i/o между процессами заключается именно что в копировании памяти.» уже ни на чем не основана?
Из входного буфера и беру
Какого входного буфера?
Как бы tree-парсер строит дерево по входящему потоку — отсюда и знаю, где что.
Какой парсер, если речь идет о сериализации? Это, на минуточку, обратная операция. Речь идет о том, что у вас в приложении была прикладная информация, строка, которую кто-то хочет как данные записать в ваш формат. Вот это надо сериализовать. В какой момент (и с какой стоимостью) будут убраны \n?
А что они там забыли? Пусть лежат себе в своём потоке.
Если у вас есть что возразить — дерзайте. Давайте не будем с умным видом загадывать друг другу загадки.
В который пришли данные. Что не понятно?
В момент создания соответствующей ветки дерева будет пробежка по данным в поисках переводов строк. Убирать их нет никакого смысла.
Если у вас есть что возразить — дерзайте. Давайте не будем с умным видом загадывать друг другу загадки.
В который пришли данные. Что не понятно?
В момент создания соответствующей ветки дерева будет пробежка по данным в поисках переводов строк. Убирать их нет никакого смысла.
Да я уже возразил (указав, что unix pipe — это не копирование памяти), только вы это игнорируете.
Что ж, вернемся к этому примеру еще раз. Вот у вас есть входной поток (именно поток, то есть либо cin, либо сетевое соединение, то есть читать вы его можете только один раз и только вперед; это как раз ситуация чтения из unix pipe), и вы в нем стоите на позиции «начало значения». Это значение нужно прочитать в память. Пожалуйста, покажите, как именно вы на этой операции получите разницу в скорости парсинга на порядок по сравнению с аналогичной операцией для JSON.
(С записью будем разбираться следующим этапом)
Что ж, вернемся к этому примеру еще раз. Вот у вас есть входной поток (именно поток, то есть либо cin, либо сетевое соединение, то есть читать вы его можете только один раз и только вперед; это как раз ситуация чтения из unix pipe), и вы в нем стоите на позиции «начало значения». Это значение нужно прочитать в память. Пожалуйста, покажите, как именно вы на этой операции получите разницу в скорости парсинга на порядок по сравнению с аналогичной операцией для JSON.
(С записью будем разбираться следующим этапом)
А что же это? Прямая запись в адресное пространство другого процесса?
Для программы это файловый дескриптор, с соответствующим набором операций. Что у него там внутри происходит, вы уже не знаете.
Может поделитесь этим сакральным знанием как данные передаются между процессами без копирования?
(Ну понятно, показывать, где у вас там разница на порядок, вы не хотите — или не можете, поэтому цепляетесь за удобную фразу.)
Так вот, где-то внутри unix pipe память, конечно, копируется. В том же значении, в котором запись элемента в массив — копирование значения этого элемента. Но важно то, что там внутри есть не только копирование, но еще и управление состоянием потока, buffer rotation и другие смешные вещи, поэтому давать ссылку на memcpy, а потом распространять описанную там производительность на unix pipe не надо.
Так вот, где-то внутри unix pipe память, конечно, копируется. В том же значении, в котором запись элемента в массив — копирование значения этого элемента. Но важно то, что там внутри есть не только копирование, но еще и управление состоянием потока, buffer rotation и другие смешные вещи, поэтому давать ссылку на memcpy, а потом распространять описанную там производительность на unix pipe не надо.
Работа пайплайна не зависит от того что за данные мы передаём. Но чтобы передать данные в пайплайн нужно подготовить их в том виде, в котором они должны в него идти.
В случае JSON мы должны выделить некоторый буфер, сериализовать в него дерево и сказать системе «отправь ка этот буфер в выходной поток».
В случае Tree данные не надо как либо экранировать, так что достаточно сказать «отправь этот кусок памяти в буфер, потом этот, а затем тот».
В случае JSON мы должны выделить некоторый буфер, сериализовать в него дерево и сказать системе «отправь ка этот буфер в выходной поток».
В случае Tree данные не надо как либо экранировать, так что достаточно сказать «отправь этот кусок памяти в буфер, потом этот, а затем тот».
В случае JSON мы должны выделить некоторый буфер, сериализовать в него дерево и сказать системе «отправь ка этот буфер в выходной поток».
Это еще зачем? Что мешает взять JSON и сразу сериализовать его в выходной поток?
так что достаточно сказать «отправь этот кусок памяти в буфер, потом этот, а затем тот».
А управляющие последовательности сами собой возьмутся? Ну и да, в случае Tree бремя экранирования лежит на пользовательском коде (потому что Tree не поддерживает значения, содержащие \n).
Вот именно чтобы это все не трогать, я и предлагал обсуждать чтение из входящего потока конкретного значения, причем строкового (поскольку это единственный общий тип между tree и json). Что характерно, в этом треде именно это и обсуждается, поскольку он весь посвящен экранированию.
Потокобезопасность мешает.
Вы не фантазируйте, а попробуйте разобраться в формате. А лучше сделайте свою реализацию и сразу всё поймёте.
Вы не фантазируйте, а попробуйте разобраться в формате. А лучше сделайте свою реализацию и сразу всё поймёте.
Потокобезопасность мешает.
Ээээ, это каким образом? (Почему-то реализациям в .net не мешает)
Вы не фантазируйте, а попробуйте разобраться в формате. А лучше сделайте свою реализацию и сразу всё поймёте.
Я не фантазирую, я уже набросал псевдокод реализации, и именно поэтому и говорю, что разница в скорости чтения в обоих случаях пренебрежима (и ни в одном случае нет необходимости в копировании буфера памяти целиком). Так что теперь мне интересен ваш псевдокод, на основании которого вы делаете вывод о разнице в скорости на порядок.
Так покажите же свой псевдокод.
(Srsly?)
Мы исходим из положения, что входной поток стоит ровно на начале читаемой строки.
Tree:
Стоимость строго 4n (полагая операции перехода, чтения, выбора и присвоения идентичными по стоимости).
JSON:
Стоимость в пограничном случае m (ни одной эскейп-последовательности): 4n.
Стоимость в пограничном случае w (все символы — двухсимвольный эскейп): 3n
Стоимость в пограничном случае u (все символы — юникод-эскейп): 2.5n
Обобщенная формула стоимости: 4m + 6w + 15u, при n = m + 2w + 6u
BTW, решив простенькую систему неравенств, можно внезапно выяснить, что чтение JSON по такому алгоритму никогда не медленнее чтения tree.
PS Кстати, у меня тут из грамматики создалось ощущение, что tree не ждет \n в конце каждого значения, а это значит, что можно очень легко сломать файл, просто разорвав передачу, и способов это провалидировать не существует. Это нехорошо.
Мы исходим из положения, что входной поток стоит ровно на начале читаемой строки.
Tree:
buf = "";
while(true)
{
c = ReadNextChar();
switch(c)
{
case EOF:
case '\n':
return buf;
default:
buf += c;
}
}
Стоимость строго 4n (полагая операции перехода, чтения, выбора и присвоения идентичными по стоимости).
JSON:
buf = "";
while(true)
{
c = ReadNextChar();
switch(c)
{
case EOF:
throw;
case '"':
return buf;
case '\\':
switch(ReadNextChar())
{
case 'u'
buf += MakeChar(ReadNextChar(), ReadNextChar(), ReadNextChar(), ReadNextChar())
case 'n':
buf += '\n';
//raise, rinse, repeat
default:
throw;
}
default:
buf += c;
}
}
Стоимость в пограничном случае m (ни одной эскейп-последовательности): 4n.
Стоимость в пограничном случае w (все символы — двухсимвольный эскейп): 3n
Стоимость в пограничном случае u (все символы — юникод-эскейп): 2.5n
Обобщенная формула стоимости: 4m + 6w + 15u, при n = m + 2w + 6u
BTW, решив простенькую систему неравенств, можно внезапно выяснить, что чтение JSON по такому алгоритму никогда не медленнее чтения tree.
PS Кстати, у меня тут из грамматики создалось ощущение, что tree не ждет \n в конце каждого значения, а это значит, что можно очень легко сломать файл, просто разорвав передачу, и способов это провалидировать не существует. Это нехорошо.
Да, кривая грамматика. Там и символ перевода строки не тем кодом был задан.
Какой-то псевдокод у вас совсем оторванный от реальности.
Tree:
1. запоминаем начальное и конечное смещение = 0
2. читаем байты в цикле
2.1. если байт равен 0A, то создаём узел дерева, который хранит начальное и конечное смещение
2.2. иначе увеличиваем конечное смещение
3. формируем префикс
4. пробегаемся по списку узлов
4.1. говорим системе скопировать префикс в системный буфер
4.2. говорим системе скопировать данные по смещениям из узла в системный буфер
JSON:
1. выделить памяти с запасом под временный буфер
2. в цикле читаем байты
2.1. если спецсимвол, то смотрим какой и пишем в буфер соответствующий набор байт
2.2. иначе копируем байт как есть
2.3. если буфер вдруг закончился, то говорим системе скопировать его в системный буфер
2.3.1 начинаем заполнять его заново
Итого, отличие в следующем:
JSON: побайтово фактически копируем все данные во временный буфер, чем больше буфер, тем меньше системных вызовов
Tree: побайтово читаем, но создаём сравнительно небольшую структуру пропорциональную числу переводов строк, число системных вызовов в 2 раза больше числа переводов строк
Какой-то псевдокод у вас совсем оторванный от реальности.
Tree:
1. запоминаем начальное и конечное смещение = 0
2. читаем байты в цикле
2.1. если байт равен 0A, то создаём узел дерева, который хранит начальное и конечное смещение
2.2. иначе увеличиваем конечное смещение
3. формируем префикс
4. пробегаемся по списку узлов
4.1. говорим системе скопировать префикс в системный буфер
4.2. говорим системе скопировать данные по смещениям из узла в системный буфер
JSON:
1. выделить памяти с запасом под временный буфер
2. в цикле читаем байты
2.1. если спецсимвол, то смотрим какой и пишем в буфер соответствующий набор байт
2.2. иначе копируем байт как есть
2.3. если буфер вдруг закончился, то говорим системе скопировать его в системный буфер
2.3.1 начинаем заполнять его заново
Итого, отличие в следующем:
JSON: побайтово фактически копируем все данные во временный буфер, чем больше буфер, тем меньше системных вызовов
Tree: побайтово читаем, но создаём сравнительно небольшую структуру пропорциональную числу переводов строк, число системных вызовов в 2 раза больше числа переводов строк
Какой-то псевдокод у вас совсем оторванный от реальности.
Он (а) гарантировано работающий и (б) выполняющий поставленную задачу
(Вы, все-таки, пишете, пожалуйста, псевдокод, а не текст, а то слишком вопросов много.)
Tree:
1. запоминаем начальное и конечное смещение = 0
2. читаем байты в цикле
Читаем откуда и куда? Что является верхней границей цикла?
2.1. если байт равен 0A, то создаём узел дерева, который хранит начальное и конечное смещение
2.2. иначе увеличиваем конечное смещение
3. формируем префикс
4. пробегаемся по списку узлов
4.1. говорим системе скопировать префикс в системный буфер
4.2. говорим системе скопировать данные по смещениям из узла в системный буфер
Что такое «системный буфер»? Скопировать данные откуда?
Tree: побайтово читаем, но создаём сравнительно небольшую структуру пропорциональную числу переводов строк, число системных вызовов в 2 раза больше числа переводов строк
У вас с переводом строки значение заканчивается, задача выполнена. Откуда вдруг следующие действия?
Я еще раз повторяю задачу: надо прочитать из входящего потока (т.е., forward-only источника данных) строковое значения, исходя из того, что сейчас положение потока — начало этого значения (в tree — после =, в JSON — после "). Если угодно, рассматривайте эту задачу как функцию, у которой на входе правильно спозиционированный поток, а на выходе — прочитанное значение (положение в потоке, понятное дело, меняется).
Если по каким-то причинам вы считаете эту задачу некорректной и никогда не возникающей, то объясните мне, что делает вот этот код (честное слово, я лучше даже не буду пытаться посчитать его стоимость по памяти, с учетом того, что строки в D неизменны):
if( input[0] == '=' ) {
auto value = input.takeUntil( "\n" )[ 1 .. $ ];
auto next = new Tree( "" , value , [] , baseUri , row , col );
...
}
...
string takeUntil( ref string input , string symbols ) {
auto res = "";
while( input.length ) {
auto symbol = input[0];
if( symbols.indexOf( symbol ) == -1 ) {
res ~= symbol;
input = input[ 1 .. $ ];
} else {
break;
}
}
return res;
}
In most Unix-like systems, all processes of a pipeline are started at the same time, with their streams appropriately connected, and managed by the scheduler together with all other processes running on the machine. An important aspect of this, setting Unix pipes apart from other pipe implementations, is the concept of buffering: for example a sending program may produce 5000 bytes per second, and a receiving program may only be able to accept 100 bytes per second, but no data is lost. Instead, the output of the sending program is held in a queue. When the receiving program is ready to read data, the operating system sends its data from the queue, then removes that data from the queue. If the queue buffer fills up, the sending program is suspended (blocked) until the receiving program has had a chance to read some data and make room in the buffer. In Linux, the size of the buffer is 65536 bytes.en.wikipedia.org/wiki/Pipeline_(Unix)#Implementation
У вас условия меняются как перчатки. Входящий поток в каком формате?
Именно благодаря тому, что строки в D неизменны и есть GC, срезы этих строк занимают считанные байты.
У вас условия меняются как перчатки. Входящий поток в каком формате?
Входящий поток в виде последовательности символов (чтобы не размениваться на детали реализации utf-8). И нет, эти условия как не менялись, так и не меняются.
Именно благодаря тому, что строки в D неизменны и есть GC, срезы этих строк занимают считанные байты.
Срезы-то да. А суммы?
Тогда при чём тут пассаж про = и "?
Не знаю, умеет ли D объединять последовательно идущие срезы. Но даже если нет, то не проблема конкатенацию срезов заменить на пересоздание среза.
Не знаю, умеет ли D объединять последовательно идущие срезы. Но даже если нет, то не проблема конкатенацию срезов заменить на пересоздание среза.
Тогда при чём тут пассаж про = и "?
К положению в потоке.
Я так понимаю, что вы будете придираться к чему угодно, лишь бы не показывать свой псевдокод?
Ага, я так и знал, что вашего псевдокода в итоге не будет. Ок, тезис про более высокую производительность tree на чтении значений считаем опровергнутым.
import std.stdio;
import std.file;
import jin.tree;
import std.json;
import std.datetime;
void testJSON() {
auto JSONString = cast(string) read( "./source/jin/tree/formats/sample.min.json" );
std.file.write( "res.json" , parseJSON( JSONString ).toString() );
}
void testTree() {
auto TreeString = cast(string) read( "./source/jin/tree/formats/sample.tree" );
std.file.write( "res.tree" , Tree.parse( TreeString ).toString() );
}
int main(string[] argv)
{
auto result = comparingBenchmark!( testJSON, testTree, 200 );
writeln( result.point );
writeln( result );
result = comparingBenchmark!( testTree, testJSON, 200 );
writeln( result.point );
writeln( result );
return 0;
}
Результат:
1.42267
ComparingBenchmarkResult(TickDuration(5512316), TickDuration(3874621))
0.750915
ComparingBenchmarkResult(TickDuration(3867075), TickDuration(5149818))
Tree примерно в полтора раза быстрее JSON. При этом:
* в тесте есть чтение с диска и запись на него (впрочем, ОС всё-равно это дело кэширует)
* данные не содержат символов, которые необходимо в JSON экранировать
* JSON читается и сериализется в минифицированном виде
Кстати, безотносительно того, как работают unix pipes — вы правда думаете, что это самый частый сценарий использования вашего формата? А если нет, то что делать с типовыми применениями, где все-таки есть ощутимые потери на I/O?
Я так понимаю вы намекаете на base64, base62 и другие способы конвертации бинарных данных в текстовые? Вот собственно эта фаза перекодировки и мешает. Она не позволяет просто потоком вгрузить файл в память и далее просто ссылаться на его участки — обязательно надо выделять отдельные куски памяти для отдельных декодированных значений.
Как в случае Tree будет выглядить «просто ссылка» на бинарную переменную int-10?
return numbers.select('int-10')[0].value!int
И да, в этот момент будет копирование. Более другие структуры типа StringBuffer могут обойтись без него.
Вы привели код, после обработки парсером.
Ни о какой «ссылке на участок файла» речи здесь не идет.
С таким же успехом я и в xml запихаю бинарные данные в виде base64, распакую и верну результат.
Внимательно прочитайте цитату. Там вы говорите, что недостатком такого подхода является необходимость выделения отдельного буффера под данные перед их использованием.
Покажите код, который будет отдавать ссылку на int-10 без выделения дополнительной памяти под сборку этого самого инта.
Ни о какой «ссылке на участок файла» речи здесь не идет.
С таким же успехом я и в xml запихаю бинарные данные в виде base64, распакую и верну результат.
Внимательно прочитайте цитату. Там вы говорите, что недостатком такого подхода является необходимость выделения отдельного буффера под данные перед их использованием.
Покажите код, который будет отдавать ссылку на int-10 без выделения дополнительной памяти под сборку этого самого инта.
Вот именно, что вам придётся распаковывать, а я просто скопирую. Копирование участков памяти — это гораздо более быстрая операция, чем битовые операции или трансляция через таблицу символов.
А зачем вам ссылка, если он может быть сразу загружен в регистр процессора? ;-) Код не приведу, ибо программирую на более высоком уровне абстракции, но компилятору сгенерировать его не проблема.
А зачем вам ссылка, если он может быть сразу загружен в регистр процессора? ;-) Код не приведу, ибо программирую на более высоком уровне абстракции, но компилятору сгенерировать его не проблема.
Я вообще не обсуждал скорость.
Я обсуждал ваш конкретный довод — «выделять отдельную память».
Вывод тут ясен — довод не актуален и, судя по всему, вброшен без серьезного обдумывания.
Я обсуждал ваш конкретный довод — «выделять отдельную память».
Вывод тут ясен — довод не актуален и, судя по всему, вброшен без серьезного обдумывания.
Если уж мы говорим о «декодировании», то тут тоже особых проблем нет.
Ничего не мешает сунуть бинарные данные в тот же json. Единственное что придется сделать — экранировать кавычки и бэкслэш.
С точки зрения скорости исполнения и сложности кода нет разницы, экранировать один символ(перенос строки) или два(кавычки и бэк слэш).
Реальным плюсом вашего формата стало бы хранение цельного блока бинарных данных, т.к. это позволило бы делать то, о чем вы говорили — ссылаться на документ не работая с бинарными данными отдельно. Но у вас этого плюса нет. как уже было выяснено.
Ничего не мешает сунуть бинарные данные в тот же json. Единственное что придется сделать — экранировать кавычки и бэкслэш.
С точки зрения скорости исполнения и сложности кода нет разницы, экранировать один символ(перенос строки) или два(кавычки и бэк слэш).
Реальным плюсом вашего формата стало бы хранение цельного блока бинарных данных, т.к. это позволило бы делать то, о чем вы говорили — ссылаться на документ не работая с бинарными данными отдельно. Но у вас этого плюса нет. как уже было выяснено.
Давайте так, я дам вам JSON с экранированными кавычками и бэкслешами, а вы попробуете его распарсить.
Я не смогу это распарсить. Ваш JSON не валидный.
А вообще, в чем вы видите сложность? В том, что стандартные парсеры это не поймут? Ну так это естественно. Речь же как раз о том, что нужно изменить, чтобы тот же json смог хранить бинари не хуже чем у вас.
Или вы видите проблему в том, чтобы написать парсер, который будет считать значения валидными, если они содержат любые символы, а не только unicode(как это по стандарту должно быть).
А вообще, в чем вы видите сложность? В том, что стандартные парсеры это не поймут? Ну так это естественно. Речь же как раз о том, что нужно изменить, чтобы тот же json смог хранить бинари не хуже чем у вас.
Или вы видите проблему в том, чтобы написать парсер, который будет считать значения валидными, если они содержат любые символы, а не только unicode(как это по стандарту должно быть).
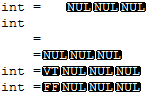
А как можно представить строковое значение, состоящее из одного/N пробелов? Пустое строковое значение? Если так, как я думаю — то без отображения в редакторе непечатаемых символов можно получить не то, что ожидаешь.
Да, есть такой нюанс. К сожалению, большинство редакторов непечатаемые символы показывают слишком навязчиво и вырвиглазно. Думаю через плагин подсветки синтаксиса можно решить эту проблему.
Думаю можно кроме "=" добавить «хередок» формат:
имя #= считается_всё
включая пробелы и переводы строк
до пустой
\n\s*#=\n
или в первой строчке до #=
#=
А чем подсветка концов строк не угодила-то?
Не знаю, как heredoc поможет увидеть, есть пробелы в значении, или там пустая строка. Но зато он может помочь при минимизации: глубоко вложенные данные, имеющие много символов перевода строки, будут минимизироваться за счет избавления от стартовых символов табуляции.
Я же имел в виду, что можно было бы сделать что-то вроде «присваивания с кавычками», как-то так:
Это повысило бы читаемость, особенно для тех, кто привык к тому же json и вообще «классическому» подходу объявления строковых литералов. Вместо "= можно использовать что-то вроде q= или |= или что угодно еще, чтобы избежать визуальной путаницы с кавычками. Ну и поддержку вложенных кавычек можно не реализовывать для таких значений: для этого есть обычное «безкавычечное» присваивание.
Однако, такое нововведение добавит в формат «еще один способ делать то же самое», что не всегда есть хорошо и не всем нравится. Ну и плюс парсинг и валидация документа усложнится.
Я же имел в виду, что можно было бы сделать что-то вроде «присваивания с кавычками», как-то так:
something "="simple quoted string goes here"
emptyString "=""
singleSpace "=" "
doubleSpace "=" "
tooManySpaces "=" "
Это повысило бы читаемость, особенно для тех, кто привык к тому же json и вообще «классическому» подходу объявления строковых литералов. Вместо "= можно использовать что-то вроде q= или |= или что угодно еще, чтобы избежать визуальной путаницы с кавычками. Ну и поддержку вложенных кавычек можно не реализовывать для таких значений: для этого есть обычное «безкавычечное» присваивание.
Однако, такое нововведение добавит в формат «еще один способ делать то же самое», что не всегда есть хорошо и не всем нравится. Ну и плюс парсинг и валидация документа усложнится.
.
Модель Tree крайне проста — есть только один тип узлов, и каждый узел имеет: имя, значение, список дочерних узлов. Имя и значение являются взаимоисключающими.Здесь точно нет ошибки? Вот же простой пример узла с именем и значением:
ip =8.8.8.8
Это два узла, между ними стоит пробел :-)
Тогда что такое узел? Я понимал что это узел дерева, но вы видимо называете узлом токены. Это надо было подробнее расписать и с примерами.
Еще больше запутывает ваше описание «есть только один тип узлов, и каждый имеет имя, значение, список дочерних». Получается не один и не каждый.
Видимо, имеется в виду, как у узлов традиционного дерева, скажем, бинарного: поля есть все у каждого узла, но некоторые могут быть пустыми (null). Если арибут(поле) узла «имя» заполнен, то это lvalue элемент, тот, что слева от присваивания. Иначе(имя=null) могут быть заполнены либо «значение» (окраинный лист), либо «дочерние» (ссылка на другой узел/список узлов, может быть реализовано как вырожденное дерево).
Почти. Любой узел может иметь либо не пустое имя, либо не пустое значение, либо пустое и имя и значение. Любые узлы могут иметь дочерние.
Тогда чем отличаются
и
ip =8.8.8.8
и
ip
=8.8.8.8
1) Почему узел с не пустым именем не может иметь значение? Почему запрещено
2) Каким образом узел с не пустым значением может иметь дочерние? Так?
А к какому узлу будут привязаны дочерние в этом случае?
3) Тот же вопрос, когда в родительской строке два или больше узлов только с названием.
4) С учетом всего вышесказанного вы по прежнему считаете, что ваш формат очень простой?
ip=8.8.8.8?2) Каким образом узел с не пустым значением может иметь дочерние? Так?
=8.8.8.8
дочернийузел1
дочернийузел2
А к какому узлу будут привязаны дочерние в этом случае?
ip =8.8.8.8
дочернийузел1
дочернийузел2
3) Тот же вопрос, когда в родительской строке два или больше узлов только с названием.
4) С учетом всего вышесказанного вы по прежнему считаете, что ваш формат очень простой?
1. Потому что значение может состоять из нескольких узлов, ввиду того, что символа перевода строки в них быть не может.
2. Яркий пример — указание для всех узлов, откуда они были взяты:

3. Почитайте внимательнее описание формата. «Наличие табуляции в строке означает, что первый узел в этой строке должен быть вложен в последний узел последней строки имеющей табуляцию на один меньше.»
4. Да, очень.
2. Яркий пример — указание для всех узлов, откуда они были взяты:
3. Почитайте внимательнее описание формата. «Наличие табуляции в строке означает, что первый узел в этой строке должен быть вложен в последний узел последней строки имеющей табуляцию на один меньше.»
4. Да, очень.
Вы даете переводчикам переводить файлы в «сыром» виде, не давая воспринимающих эти форматы инструментов?.. Кажется, я начинаю понимать, почему качественных переводов днем с огнем не найти…
Просто работаю с этими читающими человеками (переводчиками в моём случае) и каждый раз всё, что приходит на локализацию (а схемы у разных заказчиков ой какие разные, да даже в одном проекте может быть несколько разных форматов или разное использование одного формата), приходится перегонять во что-то более удобное и потом засовывать обратно, иначе будут переведённые ключи, убиение экранирования в значениях и прочая трудноуловимая содомия
В контексте вашей задачи tree ситуации не исправит — там тоже будет проблема с недопустимыми символами.
В первую очередь — странные отношения со строками, которые вынесут мозг любому не-специалисту.
Для внутреннего представления, возможно, подойдет, но, я сильно подозреваю, что избыточно.
Для внутреннего представления, возможно, подойдет, но, я сильно подозреваю, что избыточно.
Очень сложно объяснить, что если в конце текста нужен перевод строки, то нужно вбить перевод, отбивку табуляцией и еще один перевод; но если он не в конце текста, то начинать писать сразу после отбивки.
Довольно странный кейс, но всё вполне логично — строк получится столько же сколько и символов равно.
О нет.
=abc\n -> одна строка (с точки зрения человека)
=abс\n
=\n -> все еще одна строка с точки зрения человека
=abc\n
=def\n -> две строки с точки зрения человека.
=abc\n -> одна строка (с точки зрения человека)
=abс\n
=\n -> все еще одна строка с точки зрения человека
=abc\n
=def\n -> две строки с точки зрения человека.
"abc\n" // одна строка с точки зрения человека
"abс\n\n" // всё ещё одна строка с точки зрения человека
"abc\ndef\n" // и опять же одна строка с точки зрения человека
Вы что доказать-то этой софистикой хотите?
Что у tree есть свои странности, которые неподготовленному человеку вынесут мозг. Конкретный кейс конкретного massimus.
Важно, что у всех узлов один апи, а так, да, можно ввести 3 отдельных субкласса, но я ограничился одним классом и 3 хелперами для их создания.
Тул для транскодинга, конечно будет. Я хочу использовать Tree как AST в которое перегонять остальные форматы (хоть xml, хоть css), трансформировать с помощью lisp/xslt-подобного языка в модель целевого языка и сериализовывать в него.
Может присоединишься к разработке? :-)
Тул для транскодинга, конечно будет. Я хочу использовать Tree как AST в которое перегонять остальные форматы (хоть xml, хоть css), трансформировать с помощью lisp/xslt-подобного языка в модель целевого языка и сериализовывать в него.
Может присоединишься к разработке? :-)
vintage, вы зря игнорируете мой вопрос. Ваше описание формата основано на концепции узлов. При этом вы не говорите, что это такое. По прошествии суток я так и не могу понять синтаксиса вашего супер-простого формата.
До этого момента, я думал, что все понятно…
Мне кажется, что основная проблема – с названием. Если нужно найти что-то на тему XML или JSON, то в Гугле можно набрать это слово, и оно сработает как тег, выдача будет существенно предметной. Если же завтра, допустим, Tree распространится, то придется каждый раз хитрить, чтобы отвязаться от биологов, теорий баз данных, описаний структур и онтологий. Если вводите новый термин, его нужно делать по возможности уникальным.
Действительно. У вас нет идей, как его назвать так, чтобы название отражало его иерархическую суть?
TreeS
Чем множественная форма поможет в этом вопросе?
На самом деле для меня это сокращение от TreeSpace. А множественная форма сильно поможет — www.google.ru/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#newwindow=1&safe=off&q=Trees
, потому что нет такого названия сущности. И гугл сумеет различить tree и Trees если появится.
, потому что нет такого названия сущности. И гугл сумеет различить tree и Trees если появится.
Тогда уж TreeSp ;)
S-Tree, по аналогии с B-Tree.
.tree
tabbed tree
XTreeML :)
Искать если и будут, то скорее не сам формат, а какой-то язык на его основе. Например, json.tree.
Скорость парсинга/сериализации
Очень интересно как вы это оценили, по моему мнению ваш формат тяжелее того же json, грамматика у вас не проще, она сложнее т.к. она контекстно зависимая.
Удобство редактирования
Вот уж нет, ваш формат неудобно редактировать. Почему после = не должно быть пробела? Это ведь неудобно. Да и реализуется это не сложно.
Просто я тоже не давно писал свой формат, от нечего делать, и как по мне так он удобнее. Интересно сравнить как будет выглядеть в вашем формате подобная структура. Может что полезного для своего формата найду в вашем.
{
// Узел может одновременно иметь атрибуты, значения, подузлы
scene (type = Open; lods = on;) = "Start location"
{
object = "Tree"
{
position = 56.42, 23.0, 234.325;
rotation = 0, 45.34, 0;
mesh (layout = pos, UV, norm, tang, wei, ind; animated = true)
= "./assets/meshes/tree.ms";
animations = "idle_1", "idle_2", "idle_3";
collider (static = true) = cylinder
{
offset = 0, 5, 0;
radius = 45.351;
height = 180.45;
}
material = cook torrance
{
albedo = "./assets/textures/tree_a.png";
normal(normal = rgb; spec = a) = "./textures/tree_n.png";
}
object = "leaves"
{
mesh (tangents = on; animated = true) = "./assets/meshes/leaves.ms";
animations = "idle_1", "idle_2", "idle_3";
material(translucent = true; alpha = alpha test) = cook torrance
{
albedo = "./assets/textures/leaves_a.png";
normal(normal = rgb; spec = a) = "./textures/leaves_n.png";
translucent = "./textures/leaves_t.png";
}
}
}
}
}
А что сложного в тривиальной контекстно зависимой грамматике? Там нужно всего-лишь иметь стек узлов и по числу табов его обрезать.
Люди вон, к нагромождению скобочек в лиспе привыкли так, что удобным это считают, а вы тут на один пробел жалуетесь :-)
Насколько я понял код, в Tree он будет выглядеть примерно так:

Люди вон, к нагромождению скобочек в лиспе привыкли так, что удобным это считают, а вы тут на один пробел жалуетесь :-)
Насколько я понял код, в Tree он будет выглядеть примерно так:
Тем что у вас она куда менее тривиальна чем у того же JSON. А на пробел жалуемся т.к. не понятен смысл данного ограничения, который разгуливается на раз.
Ок тогда поговорим о проблемах которые в данном случае несёт ваш формат.
1) Он получился длиннее и намного (вы не описали материал и под узел leaves). И он неправильно передал структуру выше, а конкретно: почему у rotation в конце просто 0 а не =0 это опечатка? layout в моём случае это массив констант layout = pos, UV, norm, tang, wei, ind; у вас же это под узлы месша.
2) Такая же проблема как и у JSON, это отсутствие атрибутов (собственно потому мне и пришлось писать свой формат). Есть ли хоть какая нибудь гарантия что узлы name, type, lods в вашем случае не окажутся где то в середине узла между другими большими под узлами? Напомню что в ваш формат пишет не только человек, но и машина, а ей не укажешь какой узел должен идти раньше, а какой позже (по крайней мере подобного требования в вашем стандарте я не увидел).
3) Также имеется проблема которая сразу ставит крест на формате (по крайней мере для меня), отсутствие поддержки массивов. Серьёзно кому может понравится писать
В результате получаем что ваш формат проигрывает XML в случае когда активно используются атрибуты и массивы, и также проигрывает JSON в случае с использованием массивов и если он будет использоваться для протокола передачи (из-за табов).
Если так нравятся табы, то можно было бы сделать тот же JSON только без ", {
Выглядело бы лучше.
Насколько я понял код, в Tree он будет выглядеть примерно так:
Ок тогда поговорим о проблемах которые в данном случае несёт ваш формат.
1) Он получился длиннее и намного (вы не описали материал и под узел leaves). И он неправильно передал структуру выше, а конкретно: почему у rotation в конце просто 0 а не =0 это опечатка? layout в моём случае это массив констант layout = pos, UV, norm, tang, wei, ind; у вас же это под узлы месша.
2) Такая же проблема как и у JSON, это отсутствие атрибутов (собственно потому мне и пришлось писать свой формат). Есть ли хоть какая нибудь гарантия что узлы name, type, lods в вашем случае не окажутся где то в середине узла между другими большими под узлами? Напомню что в ваш формат пишет не только человек, но и машина, а ей не укажешь какой узел должен идти раньше, а какой позже (по крайней мере подобного требования в вашем стандарте я не увидел).
3) Также имеется проблема которая сразу ставит крест на формате (по крайней мере для меня), отсутствие поддержки массивов. Серьёзно кому может понравится писать
offset
=0
=5
=0
// вместо
offset = 0, 5, 0;
//или
"offset" : [0, 5, 0],
В результате получаем что ваш формат проигрывает XML в случае когда активно используются атрибуты и массивы, и также проигрывает JSON в случае с использованием массивов и если он будет использоваться для протокола передачи (из-за табов).
Если так нравятся табы, то можно было бы сделать тот же JSON только без ", {
Выглядело бы лучше.
При парсинге JSON вам точно также нужен будет стек, только ещё нужно будет разэкранировать строки.
1. Разумеется, специализированный DSL будет наглядней и короче, чем универсальный формат. 0 — это конечно же опечатка.
2. А это принципиальный момент, чтобы атрибуты шли первым? Если да, то и вставляйте их первыми :-) Формат лишь гарантирует, что в каком порядке их туда положил, в таком же и получишь.
3. Это только в тривиальных случаях «и в одну строку норм».
JSON плохо своей моделью данных прежде всего. Любое дерево (ast, html и прочее) в JSON выглядит как нагромождение костылей.
1. Разумеется, специализированный DSL будет наглядней и короче, чем универсальный формат. 0 — это конечно же опечатка.
2. А это принципиальный момент, чтобы атрибуты шли первым? Если да, то и вставляйте их первыми :-) Формат лишь гарантирует, что в каком порядке их туда положил, в таком же и получишь.
3. Это только в тривиальных случаях «и в одну строку норм».
"offset" : [ 123454.234345, 1234893434.3425342, 324589565.1342352461 ],
JSON плохо своей моделью данных прежде всего. Любое дерево (ast, html и прочее) в JSON выглядит как нагромождение костылей.
1. Разумеется, специализированный DSL будет наглядней и короче, чем универсальный формат.
Дело в том, что то что я показал не является специализированным форматом, он подходит для любых потребностей.
Формат лишь гарантирует, что в каком порядке их туда положил, в таком же и получишь.
Честно говоря не нашёл этого требования в исходном тексте, разве это зависит не от реализации? Если для хранение нодов я буду использовать мапу или хеш, как можно гарантировать порядок записи?
3. Это только в тривиальных случаях «и в одну строку норм».
Это в любых случаях норм, и я не говорил что запись должна быть исключительно в 1 строку, вот пример записи матрицы из того же формата.
transform =
1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0,
0, 0, 0, 0,
И да хотел бы я посмотреть в какой ад превратился бы формат коллады, используй они твой формат. По большому счёту именно твой формат является специализированным.
JSON плохо своей моделью данных прежде всего. Любое дерево (ast, html и прочее) в JSON выглядит как нагромождение костылей.
Он практически полностью идентичен твоему формату, все различия заключаются лишь в том что для блоков у тебя используются табы, а там {} ну и в требованиях использовать " во всём остальном он лучше твоего формата, опять же если использовать hjson то и от " можно будет избавится. Не вижу ничего в чём твой формат превосходит JSON и из-за чего на него хотелось бы перейти. Где те фичи ради которых хотелось бы на него перейти?
А ещё я никак не могу понять чем твоя «Произвольная иерархия» отличается от того же json или XML? И если уж говорить о возможностях то YAML на голову выше.
Вообще с таблицей которую ты предоставил я в корне несогласен. Она крайне субъективна.
Честно говоря не нашёл этого требования в исходном тексте, разве это зависит не от реализации? Если для хранение нодов я буду использовать мапу или хеш, как можно гарантировать порядок записи?Это не требование, это определение списка.
Матрицы могут быть представлены на уровне языка так:
Хоть это и потребует немного больше телодвижений, чем с простым вертикальным списком. С другой стороны, модель Tree позволяет делать такие выкрутасы:

Это не требование, это определение списка.
Не вижу в вашем тексте требования что дочерние узлы должны хранится в списке.
Матрицы могут быть представлены на уровне языка так:
То есть на уровне приложения мне придётся парсить 1..0..0..0?
С другой стороны, модель Tree позволяет делать такие выкрутасы:
В каком смысле? y.determinant нам придётся разбивать в коде?
Присмотритесь внимательнее.
Точки — это подсветка пробелов в IDEA
Тут речь о том, что в ячейке может быть формула от другой матрицы.
Точки — это подсветка пробелов в IDEA
Тут речь о том, что в ячейке может быть формула от другой матрицы.
Точки — это подсветка пробелов в IDEA
А в ы можете не делать скриншот ide а просто вставить текст с тегом кода? Ато это сбивает с толку, я например в IDEA не работал, откуда мне занть что точки это пробелы.
Тут речь о том, что в ячейке может быть формула от другой матрицы.
В каком смысле формула? Мне придётся писать код чтобы из 1 0 0 0 получить нужную мне последовательность?
Каким тегом? Хабр как бы не поддерживает подсветку Tree синтаксиса.
Тому, кто будет разрабатывать реализацию языка, придётся написать этот код.
Тому, кто будет разрабатывать реализацию языка, придётся написать этот код.
А в ы можете не делать скриншот ide а просто вставить текст с тегом кода? Ато это сбивает с толку, я например в IDEA не работал, откуда мне занть что точки это пробелы.В Visual Studio работаете? Ctrl+R, Ctrl+W
Хабравчане, и за что минусы? Я лишь сделал предположение по профилю Chaos_Optima, что он работает с .NET и соответственно…
Хотя… нужно было на весь список подписок посмотреть.
Хотя… нужно было на весь список подписок посмотреть.
А что собственно мешает так записать? массив только будет рассматриваться как строка, и вся работа с ним ложится на приложение которое ожидает там массив. Или приложение знать не знает что там должен быть массив?
Если так рассуждать так вообще ничего ненужно, сразу брать и перекладывать всё на приложение. Зачем нам вообще форматы какие-то.
В данном случае всё упирается в удобстве, приложение может не знать что там или менять логику работы в зависимости от того что там, массив или просто значение. В любом случае это одна из фундаментальных структур которую не плохо было бы иметь. В конце концов это нетрудно сделать. Достаточно добавить [ ] и сделать так чтобы внутри этих скобок табуляция и переносы не учитывались, на уровне элементов.
В данном случае всё упирается в удобстве, приложение может не знать что там или менять логику работы в зависимости от того что там, массив или просто значение. В любом случае это одна из фундаментальных структур которую не плохо было бы иметь. В конце концов это нетрудно сделать. Достаточно добавить [ ] и сделать так чтобы внутри этих скобок табуляция и переносы не учитывались, на уровне элементов.
Сделать вроде бы нетрудно, но сразу же поиметь неопределенность в другом и свести на нет остальные достоинства формата.
Собственно «сделать так чтобы внутри этих скобок табуляция и переносы не учитывались» это и есть перенос обработки массива на приложение.
Собственно «сделать так чтобы внутри этих скобок табуляция и переносы не учитывались» это и есть перенос обработки массива на приложение.
А в чём заключается неопределённость, и каким образом это сводит на нет остальные достоинства формата?
эм… вообще то нет. Если мы напишем
то это сломает парсер.
Собственно «сделать так чтобы внутри этих скобок табуляция и переносы не учитывались» это и есть перенос обработки массива на приложение.
эм… вообще то нет. Если мы напишем
object
transform =[ 1, 0, 0,
0, 1, 0,
0, 0, 1]
то это сломает парсер.
Похоже на формат конфига nginx'а.
Есть в открытом доступе парсеры?
Есть в открытом доступе парсеры?
Выложил github.com/ChaosOptima/Game-Dev-Format но он не совсем закончен.
Долго искал этот комментарий, но не нашёл.
Это невалидный xml. Должно быть как минимум так:
С другой стороны, XML позволяет внедрять свои тэги внутрь текста…
<greeting> Hello, <b>Alice</b>!<br/> How do you do? </greeting>
Это невалидный xml. Должно быть как минимум так:
<greeting>
<![CDATA[
Hello, <b>Alice</b>!<br/>
How do you do?
]]>
</greeting>
Почему это невалидный? Вполне себе даже валидный. Но если вы намекаете на то, что контент надо хранить как единую сущность: то да — надо бы обернуть в CDATA.
Почему же он невалиден? Совершенно нормальный mixed content, широко используется в том же XHTML. А вот CDATA как раз будет ошибкой, если требуется, чтобы <b> был именно тэгом, а не экранированным значением.
>Узлы-значения – значением, предварёнными символом равенства.
зачем знак равенства?
>А теперь сравните с реализацией в Tree формате:
больше похоже на первый вариант
зачем знак равенства?
>А теперь сравните с реализацией в Tree формате:
больше похоже на первый вариант
>Редактирование других форматов, через Tree представление
хорошая идея
хорошая идея
Автору. Рекомендую продвигать эти идеи среди другой аудитории. На праздниках я тоже сделал вклад в развитие поддержки стандартов, ввёл новый «стандарт» jsonComm, который описывается очень просто, 2 строчками:
1) формат данных — как у JSON;
2) формат комментариев — как у JS и Yaml.
Вначале описал его на Хабре. Не только «стандарт», но и отлаженные процедуры, работающие в JS, для перевода в JSON и для работы с самим jsonComm, с тестами. Понятно, что праздники, но «плюсов» — всего 19, а минусов — 16. При этом никто не писал, что новый «стандарт» вреден. Посетителей на Гитхабе — под 4.5 сотни, но «star» — всего один. Что говорит об интересе.
Затем написал на EchoJS.com, просто ссылку на страницу Гитхаба. Посетителей всего 37, из них 10 могли быть остатком с Хабра, но «star» добавилось 4.
Скрин:
12-го — это всплеск с EchoJS.
По Вашему формату: какой-то странный у вас sample.tree на Гитхабе, не показывает элементы формата, только
> Надеюсь мне удалось заразить вас идеей…
Заражают не так. Например:
1) формат данных — как у JSON;
2) формат комментариев — как у JS и Yaml.
Вначале описал его на Хабре. Не только «стандарт», но и отлаженные процедуры, работающие в JS, для перевода в JSON и для работы с самим jsonComm, с тестами. Понятно, что праздники, но «плюсов» — всего 19, а минусов — 16. При этом никто не писал, что новый «стандарт» вреден. Посетителей на Гитхабе — под 4.5 сотни, но «star» — всего один. Что говорит об интересе.
Затем написал на EchoJS.com, просто ссылку на страницу Гитхаба. Посетителей всего 37, из них 10 могли быть остатком с Хабра, но «star» добавилось 4.
Скрин:
12-го — это всплеск с EchoJS.
По Вашему формату: какой-то странный у вас sample.tree на Гитхабе, не показывает элементы формата, только
user
name =John
age =30
> Надеюсь мне удалось заразить вас идеей…
Заражают не так. Например:
Если вы новичок и еще не совсем уверены, что Backbone вам подходит, начните с просмотра списка проектов, использующих Backbone.
ваш «стандарт» еще хуже, имхо
да и стиль написания статей так себе. отсюда и малый интерес
да и стиль написания статей так себе. отсюда и малый интерес
Хуже чего? Tree? Или JSON? Как он может быть хуже JSON, если JSON поначалу имел комментарии? Или слово «стандарт» имеет магическое действие, становясь лучше всего остального? Так я jsonComm не называю стандартом, это формат данных на основе имеющихся стандартов. Про стиль вполне верю, не всем понравилось. Поэтому я как основной аргумент привёл число посетителей на Гитхабе и результат.
Нет, тут дело в несколько ином. Здесь очень не любят, когда кто-то говорит «я сделал». Вот если бы сделал кто-то, а я перевёл… А так — кто-то равный меня, мол, обходит, как так? Не все, конечно, такие, но любая статья про самоделку (в конкурентной области читателей) набирает изрядное число минусов (порядка 1/3). Но далеко не везде такое отношение. Поэтому рассказывать о новом и своём советую в других местах. Здесь — хорошо идут переводы авторитетов и новости о крупных продуктах и событиях.
Нет, тут дело в несколько ином. Здесь очень не любят, когда кто-то говорит «я сделал». Вот если бы сделал кто-то, а я перевёл… А так — кто-то равный меня, мол, обходит, как так? Не все, конечно, такие, но любая статья про самоделку (в конкурентной области читателей) набирает изрядное число минусов (порядка 1/3). Но далеко не везде такое отношение. Поэтому рассказывать о новом и своём советую в других местах. Здесь — хорошо идут переводы авторитетов и новости о крупных продуктах и событиях.
Мне кажется, вы решили узкую и специфичную/скучную задачу, почему вы хотите всплеска ажиотажа по поводу неё?
Ну вот сейчас сольют мне карму за этот топик окончательно и у меня просто не останется другого выбора, как искать единомышленников где-нибудь в других местах :-) Кстати, примечательно, что 300 активных пользователей фактически решают что можно читать остальным 50000, а что нет.
А я просто режу строки в JSON которые начинаются с // (пробелы в начале строки тоже можно).
И стандарта не нужно, и статьи не нужно, и объяснить ещё проще.
Сам ни минуса ни плюса не ставил, не вижу просто смысла в нём.
Такие комментарии использую в некоторых конфигурационных файлах и файлах переводов.
И стандарта не нужно, и статьи не нужно, и объяснить ещё проще.
Сам ни минуса ни плюса не ставил, не вижу просто смысла в нём.
Такие комментарии использую в некоторых конфигурационных файлах и файлах переводов.
Это вам — json5.org/ :)
На самом деле я согласен с Дугласом: комментарии на уровне формата — это зло. Им самое место на уровне языка. Другое дело, что JSON — такой дубовый формат, что комментарии в его рамках не ввести. И поэтому приходится расширять формат привнося в него js-like комментирование. У Tree с расширяемостью проблем нет, так что комментарии на уровне языка вводятся так как удобно именно в этом языке.
Признаю, с примерами поленился. Добавил больше примеров сюда: github.com/nin-jin/tree.d/tree/master/examples
Все знают как надо делать, но хоть бы кто помог :-)
Признаю, с примерами поленился. Добавил больше примеров сюда: github.com/nin-jin/tree.d/tree/master/examples
Все знают как надо делать, но хоть бы кто помог :-)
Начинание полезное. Посмотрим, что из этого выйдет. Мы перебрались с XML и JSON на Yaml, но всё равно до полного счастья чего-то не хватает, так что в этой области есть, куда развиваться.
Ха… Сначала хотел написать что-то в духе «не люблю статьи, где пишут только о плюсах», а потом почитал комментарии =)
Добавьте, пожалуйста, в статью минусы, на которые вам указали товарищи в камментах — для тех, кто не любит читать камменты =)
Добавьте, пожалуйста, в статью минусы, на которые вам указали товарищи в камментах — для тех, кто не любит читать камменты =)
Абсолютно с вами согласен. Вот поэтому я, например, и не люблю питон.
Python и так умеет же, например:
python -c «import sys; print(sys.path)»
python -c «import sys; print(sys.path)»
А функции как там выделяются? Даже не функции, а просто функциональные блоки: функции, условия, циклы и прочее
Функции, видимо, никак, а циклы и условия весьма урезано:
Ветвление —
#> python3 -c 'print(1) if False else print(2)'
2
Цикл —
#> python3 -c 'for i in range(3): {print(i-2), print(3+i)}'
-2
3
-1
4
0
5
Другое дело, что так делать не надо, да. Отступы там играют такую же роль как фигурные скобки в C\С++\PHP.
Тут уж каждому своё, вы правы, да.
Ветвление —
#> python3 -c 'print(1) if False else print(2)'
2
Цикл —
#> python3 -c 'for i in range(3): {print(i-2), print(3+i)}'
-2
3
-1
4
0
5
Другое дело, что так делать не надо, да. Отступы там играют такую же роль как фигурные скобки в C\С++\PHP.
Тут уж каждому своё, вы правы, да.
Мне кажется, логика в этом следующая: 90% программистов пишут свой код с отступами, это делает его удобочитаемым. Почему бы нам не сделать такой язык, код которого так же будут писать с отступами, но это позволит исключить из него лишние компоненты языка, такие как end, {} и так далее. Это плюс, хотя и спорный.
Не совсем понял как это? На калькуляторе чтоли?
при работе из командной строки и в других местах, где просто нет нескольких строк
Не совсем понял как это? На калькуляторе чтоли?
Не понимаю, почему разделители вдруг становятся лишними элементами. Все равно, что писать без знаков препинания. Вот, например (статистики, конечно, нет, но думаю, не слишком погрешу против истины), наверняка большинство программистов предпочитают явные приведения типов взамен неявных. Особенно, если сталкивались с ситуациями, когда компилятор не согласен с тем, что думает программист. В некоторых языках (enum1 к enum2 или int в C#, например) вообще запрещено неявное приведение одних типов к другим (явное возможно).
Почему же с такими простыми истинами многие соглашаются, но могут утверждать, что явное выделение блока кода фигурными скобочками — зло?
Почему же с такими простыми истинами многие соглашаются, но могут утверждать, что явное выделение блока кода фигурными скобочками — зло?
Мне кажется, ваш пример некорректен, отступы — это тоже вполне себе явное выделение блоков. Более того, уверен, что наткнувшись посреди С++ кода на фрагмент типа:
...
if (x == 0)
y = 10;
z = 15;
...
Пробел и таб — это пустое место и воспринимается, как пустое, ничего не значащее место. Форматирование отступами — это представление содержания, View из MVC, если так понятнее. А скобочки — это Model. Зачем смешивать одно с другим, когда все вокруг твердят о том, что их надо разделять, я не понимаю.
Интерпретатор питона, насколько я знаю, приравнивает таб к 4 пробелам. Если в вашем примере перед y будет табуляция, а перед z — два пробела, а редактор показывает табы, как 2 пробела, то точно так же 90% прочитают код неправильно.
Интерпретатор питона, насколько я знаю, приравнивает таб к 4 пробелам. Если в вашем примере перед y будет табуляция, а перед z — два пробела, а редактор показывает табы, как 2 пробела, то точно так же 90% прочитают код неправильно.
Какие-то у вас странные аналогии, мы же о текстовом файле с кодом говорим, у него нету никаких слоев данных и представлений: какие символы вы нажмете на клавиатуре, те и будут записаны в файл, какие символы записаны в файле, те и будут выведены на экран.
Скобочки, на мой взгляд, полезны тем, что не навязывают вам жесткий code style на уровне языка, однако при чтении кода основное внимание мы обращаем именно на отступы.
Пробел и таб — это пустое место и воспринимается, как пустое, ничего не значащее место.Возьмите любой сложный код (скажем, 4 уровня вложенности) на языке со скобочками, удалите из него отступы и попробуйте прочитать. Вам будет очень некомфортно. А если удалить из кода скобочки, оставив отступы, то все останется читаемо. А вы говорите, ничего не значащее место.
Скобочки, на мой взгляд, полезны тем, что не навязывают вам жесткий code style на уровне языка, однако при чтении кода основное внимание мы обращаем именно на отступы.
Если вы отформатируете питон, он от этого не перестанет быть валидным.
> где отступы и прочие невидимые символы имеют значение.
Отступы — невидимые символы? Отступы вообще не символ, но они самые заметный в строке, это точно.
Отступы — невидимые символы? Отступы вообще не символ, но они самые заметный в строке, это точно.
Я могу вас разочаровать, но ваша гипотеза относительно JSON и TREE неверна абсолютно. С чего вы взяли, что при потере произвольной части данных все будет воспринято как норма? Всё будет воспринято как норма при удалении всего блока в потоке данных между символами 0D, включая один из символов, или внутри пары (=,0D). При таких-же ошибках в передача данных это сообветствует потере байт в JSON внутри значения, или потере списка. Это абсолютно одинаковая вероятность ввиду взаимно — однозначного маппинга структуры управления JSON — TREE, и, вследствие этого — равной вероятности ложноположительного срабатывания фильтра ошибок (ошибка при потере данных присутствует, но не будет обнаружена)
Как понять, =2 — строка или число?
А =2,55?
Ваш формат пока слишком сырой. Да и выглядит некрасиво.
А =2,55?
Ваш формат пока слишком сырой. Да и выглядит некрасиво.
Согласен. Мало типизированных форматов.
Сделали бы, например:
Сделали бы, например:
a : bool = 3
b = text
c : float = 4
Точно, сделали бы:
bool b = true;
int a = 2;
В Tree их на самом деле не ограниченное число
Не заставляйте меня перечислять все :-)
a : bool =true
b : int32 =-123456
c : uint32 =2123456
d : int64 =-1234567890
e : uint64 =12345678901
f : float =1234.2456
g : double =23456.6789085476
h : complex float
= 1234.3546
= 23456.467467
i : octet =0D
j : decimal =1234.3456
k : time =2015-01-01T00:00:00Z
Не заставляйте меня перечислять все :-)
Подождите. Мы так можем написать, но это будет не типы, а часть имён, условно говоря узел «k: time» со значением «2015-01-01T00:00:00Z».
Ваш формат — безтиповой (на самом деле он лишь строковой). Всё остальное бремя типов и пост-парсинга лежит на программисте.
Ваш формат — безтиповой (на самом деле он лишь строковой). Всё остальное бремя типов и пост-парсинга лежит на программисте.
Нет, это узел «k» с предикатом эквивалентности ":" по отношению к значению «time =2015-01-01T00:00:00Z», где «time» — имя типа, по которому определяется как интерпретировать данные и «2015-01-01T00:00:00Z» — собственно данные.
Простите, а значения, которые могут содержать первый знак '=' в середине строки — это тоже часть вашего замечательного формата?
Это многогранное слово «значение». Не цепляйтесь ко словам.
Когда речь идет о форматах и грамматиках, использование «многогранных слов» недопустимо. Вы же придираетесь к тому, что кто-то говорит «ключ» вместо «наименования»?
Поэтому нет, в терминах вашего формата
Поэтому нет, в терминах вашего формата
b : int32 =-123456 — это имя b : int32 (кстати, в вашем замечательном формате невозможны имена, содержащие знак '=', как же так, он же безопасный?) и значение -123456. И это именно та информация, которую отдаст парсер на следующий уровень. Несомненно, там можно понаписать что угодно, включая обработку пространств имен и типов, но это не будет частью формата, и, как следствие, будет иметь стандартные проблемы рассогласования.В терминах ассоциативных массивов есть понятия: ключ и значение
В терминах Tree модели данных есть узлы-имена и узлы-значения (видимо их стоит переименовать в узлы данных, чтобы не было путаницы).
Так вот, то как Tree-узлы отображаются на объекты зависит используемого от языка. В данном случае я привёл пример языка, где пара Tree узлов преобразуется в одно значение ассоциативного массива. И Tree-языки общего назначения тоже требуют стандартизации, разумеется. Точно также как XML (формат) и XHTML (язык).
А имена и пробелы содержать не могут и табы. Это не ключи из ассоциативных массивов JSON-а.
В терминах Tree модели данных есть узлы-имена и узлы-значения (видимо их стоит переименовать в узлы данных, чтобы не было путаницы).
Так вот, то как Tree-узлы отображаются на объекты зависит используемого от языка. В данном случае я привёл пример языка, где пара Tree узлов преобразуется в одно значение ассоциативного массива. И Tree-языки общего назначения тоже требуют стандартизации, разумеется. Точно также как XML (формат) и XHTML (язык).
А имена и пробелы содержать не могут и табы. Это не ключи из ассоциативных массивов JSON-а.
Никак, формат предназначен для описания структуры. Для описания семантики служат языки. Например, в языке lisp.tree узел с именем «int» будет означать, что его содержимое является целочисленным значением.
У меня один вопрос: кто-то смотрит минимизированный XML/JSON/etc в голом виде часто? По мне это просто формат представления данных для машины, который потом в массив/объект преобразуется в любом случае, а по пути каким нибудь gzip-ом пожметмя, чтобы стать еще экономичнее (если о вебе говорить).
Все эти отступы, как мне кажется, вещь в себе (представьте если там будет иерархия на 100500 элементов в глубину — гора никому не нужных отступов, которые займут места больше чем данные и всеравно не посмотреть без спец редактора). С таким же успехом можно было бы описывать данные markdown-ом, почти не изобретая новой человекчитаемой разметки.
Не хочу обидеть питонистов (сам писал несколько приблуд), но если нельзя явно структуру выделить чем то вроде {} (или, прости господи begin...end), то это величайший геморой.
Все эти отступы, как мне кажется, вещь в себе (представьте если там будет иерархия на 100500 элементов в глубину — гора никому не нужных отступов, которые займут места больше чем данные и всеравно не посмотреть без спец редактора). С таким же успехом можно было бы описывать данные markdown-ом, почти не изобретая новой человекчитаемой разметки.
Не хочу обидеть питонистов (сам писал несколько приблуд), но если нельзя явно структуру выделить чем то вроде {} (или, прости господи begin...end), то это величайший геморой.
* мало смысла минифицировать JSON/XML перед сжатием.
Как насчет аргументирования минусов?
Выигрыш в сжатом файле всего лишь ~7%
JSON отсюда, fathers|5-100
~/tmp » wc -m *.json
3182 1.json
1442 1.min.json
4624 total
~/tmp » cat 1.json | gzip > 1.json.gz
~/tmp » cat 1.min.json | gzip > 1.min.json.gz
~/tmp » wc -m *.json.gz
268 1.json.gz
224 1.min.json.gz
492 total
Выигрыш в сжатом файле всего лишь ~7%
JSON отсюда, fathers|5-100
Я бы не доверил создавать новый стандарт человеку, который по баллам ставит INI выше, чем JSON.
Бог дал миру данные. А дьявол методы их обработки. Человек, используя данные и методы их обработки, реализовал случайные интерпретации. Фсевшоке.
Чем-то мне это напоминает Haml/Slim/Jade.
Не хватает странички где можно было бы потестировать это формат, есть ощущение что после нескольких кодирований-декодирований может потеряется часть информации.
Например для массивов где-то указывается тип, где-то нет, где-то массивы превращаются в значение, где-то в дочерние ноды.
Комментарии должны быть, они полезны и очень часто используются в конфиг. файлах.
Например для массивов где-то указывается тип, где-то нет, где-то массивы превращаются в значение, где-то в дочерние ноды.
Комментарии должны быть, они полезны и очень часто используются в конфиг. файлах.
>где-то массивы превращаются в значение, где-то в дочерние ноды.
поэтому и возникает естественный вопрос: зачем вообще нужно различать эти варианты?
зачем писать лишний символ '='?
единственная ситуация, когда это может понадобится — смешение значений и дочерних нод:
стоит заметить, что подобное смешение встречается редко, и когда оно присутствует складывается впечатление, что что-то неправильно, похожее на от возвращаемых значений функций без return(так можно записать в powershell):
а вообще формат идеологически чем то похож на tcl, только с отступами вместо скобочек:
поэтому и возникает естественный вопрос: зачем вообще нужно различать эти варианты?
зачем писать лишний символ '='?
единственная ситуация, когда это может понадобится — смешение значений и дочерних нод:
obj =somevalue param =123но поскольку мы сами решаем как представлять и парсить obj, ничего не мешает записать:
obj = somevalue param 123или:
obj value somevalue param 123
стоит заметить, что подобное смешение встречается редко, и когда оно присутствует складывается впечатление, что что-то неправильно, похожее на от возвращаемых значений функций без return(так можно записать в powershell):
function f ($x){
$a=3
$x+=$a
$x
}
а вообще формат идеологически чем то похож на tcl, только с отступами вместо скобочек:
set numbers 5
puts [lsort [array names tcl_platform]]
поэтому и возникает естественный вопрос: зачем вообще нужно различать эти варианты?Потому что словари и массивы — это разные «типы», и программы могут просто сломаться если одно подменить другим.
Различать нужно, чтобы значения не конфликтовали с именами. Ведь в значении может быть любой набор байт, которой может быть воспринят как вложенный узел с некоторым именем и пошло поехало.
А мне вот не хватает 24 часов в сутках.
Никакая информация не потеряется, если вы её не удалите.
Комментируйте на здоровье, но в рамках формата, а не вне его.
Никакая информация не потеряется, если вы её не удалите.
Комментируйте на здоровье, но в рамках формата, а не вне его.
Все равно с протобафа не слезу.
Закрывающие теги помогают только в конце документа. В середине от них не больше пользы, чем от фигурных скобок JSON. Единственное решение этой проблемы — отображение редактором «хлебных крошек» к текущей отображаемой области.
Языков с семантическими отступами превеликое множество. А Jade — всего-лишь язык хтмл-шаблонов.
Языков с семантическими отступами превеликое множество. А Jade — всего-лишь язык хтмл-шаблонов.
Все эти «языки» с форматом, требующим табуляцию — фу. Что coffescript, про который наконец-то все забыли, что ваш «убийца». Есть вот определенный язык, на котором хорошо, удобно ведется разработка. Нет, надо внедрить новые «перспективные» технологии и потом сидишь и переделываешь всё, тьфу.
Простой язык структурированных данных — это очень хорошо. Вложенность индентацией — это тоже хорошо. Но есть и то, что плохо, причём очень:
1. Требование индентирования непременно табуляцией.
2. Требование завершения строк непременно 0D
Эти требования (любое из них) приводят к тому, что после открытия-правки-сохранения файла в произвольном текстовом редакторе мы с высокой вероятностью получим некорректный файл, при том что визуально он не будет отличаться от корректного. Это Очень Большой Недостаток, сразу ставящий на формате крест.
Я, кстати, не вижу никаких сложностей в разрешении и пробелов и табуляции (естественно, не в смеси) в п. 1. и 0A 0D в п. 2. Понятно, что это порушит светлую мечту о прямой записи произвольных бинарных данных, но, как уже сказали выше, с такой записью всё равно проблемы — величину, состоящую из пробельных символов никак нельзя контролировать и вообще увидеть. Я бы предложил автору сначала вообще оценить важность этой задачи — записи бинарных данных без кодирования. Мне кажется, она сильно преувеличиена, недаром ни в одном примере в статье не используется ничего сверх обычного UTF-8…
1. Требование индентирования непременно табуляцией.
2. Требование завершения строк непременно 0D
Эти требования (любое из них) приводят к тому, что после открытия-правки-сохранения файла в произвольном текстовом редакторе мы с высокой вероятностью получим некорректный файл, при том что визуально он не будет отличаться от корректного. Это Очень Большой Недостаток, сразу ставящий на формате крест.
Я, кстати, не вижу никаких сложностей в разрешении и пробелов и табуляции (естественно, не в смеси) в п. 1. и 0A 0D в п. 2. Понятно, что это порушит светлую мечту о прямой записи произвольных бинарных данных, но, как уже сказали выше, с такой записью всё равно проблемы — величину, состоящую из пробельных символов никак нельзя контролировать и вообще увидеть. Я бы предложил автору сначала вообще оценить важность этой задачи — записи бинарных данных без кодирования. Мне кажется, она сильно преувеличиена, недаром ни в одном примере в статье не используется ничего сверх обычного UTF-8…
И без использования 0A 0D (в миру более известны как \r \n) этот формат не является истинно бинарно-безопасным, так как множество входных символов алфавита этой грамматики входных данных не должно включать символы-разделители, используемые в этом формате, чтобы избежать неоднозначной интепретации данных.
Просто добавим поле с «проверочным» значением, «контрольная сумма», или, если хотите, избыточную информацию, равную самому форматированному TREE потоку данных, но без этой контрольной строки, чтобы избежать бесконечно длинного потока данных. Так как все последующие переносы строк нарушат структуру данных, то обратная процедура с декодированиеи этого потока обречена на провал, так как всегда будет существовать по крайней мере одна структура, которая будет неправильно интерпретирована при корректных входных данных, вне зависимости от сложности алгоритма обработки этих данных.
Просто добавим поле с «проверочным» значением, «контрольная сумма», или, если хотите, избыточную информацию, равную самому форматированному TREE потоку данных, но без этой контрольной строки, чтобы избежать бесконечно длинного потока данных. Так как все последующие переносы строк нарушат структуру данных, то обратная процедура с декодированиеи этого потока обречена на провал, так как всегда будет существовать по крайней мере одна структура, которая будет неправильно интерпретирована при корректных входных данных, вне зависимости от сложности алгоритма обработки этих данных.
Получим некорректный файл -> попытаемся распарсить -> получим ошибку -> пойдём и настроим, наконец, редактор. Если редактор не детектирует автоматически тип отступов и переводов строк, а фигачит что-от своё, то это косяк редактора, а не редактируемого формата. И крест надо ставить именно на редакторе. Вообще говоря, я не вижу смысла в 21 веке использовать виндовые переводы строк. У них вообще никаких преимуществ.
Ничего сверх UTF-8 как правило и не надо, но благодаря бинарной безопасности экранирование спецсимволов тоже не нужно.
Ничего сверх UTF-8 как правило и не надо, но благодаря бинарной безопасности экранирование спецсимволов тоже не нужно.
Всё больше соглашаюсь с комментарием ниже: habrahabr.ru/post/248147/#comment_8231775
Если хотите скорости — используйте msgpack (http://msgpack.org)
Формат TREE не является в подлинном смысле бинарно-безопасным форматом.
Лулз пакета в том, что если бы формат действительно был бинарно-безопасным, то разделители 0D могли бы входить в двоичную последовательность в паре ключ — значение, а иначе — это ложное утверждение. Данный формат не является бинарно-безопасным, так как нет механизма подсчёта длины двоичных данных в паре ключ-значение, а следовательно, формат является контекстно-зависимым
Лулз пакета в том, что если бы формат действительно был бинарно-безопасным, то разделители 0D могли бы входить в двоичную последовательность в паре ключ — значение, а иначе — это ложное утверждение. Данный формат не является бинарно-безопасным, так как нет механизма подсчёта длины двоичных данных в паре ключ-значение, а следовательно, формат является контекстно-зависимым
Вот для xml есть xsd (что характерно — de facto индустриальный стандарт). А что есть для tree?
Выношу обьяснение №2, почему формат TREE не является бинарно-безопасным.
Без использования магических констант-разделителей, этот формат не является бинарно-безопасным, так как множество входных символов алфавита этой грамматики входных данных не должно включать символы-разделители, используемые в этом формате, чтобы избежать неоднозначной интепретации данных.
Обьяснение
Просто добавим поле с «проверочным» значением, «контрольная сумма», или, если хотите, избыточную информацию, равную самому форматированному TREE потоку данных, но без этой контрольной строки, чтобы избежать бесконечно длинного потока данных. Так как все последующие переносы строк нарушат структуру данных, то обратная процедура с декодированиеи этого потока обречена на провал, так как всегда будет существовать по крайней мере одна структура, которая будет неправильно интерпретирована при корректных входных данных, вне зависимости от сложности алгоритма обработки этих данных.
Без использования магических констант-разделителей, этот формат не является бинарно-безопасным, так как множество входных символов алфавита этой грамматики входных данных не должно включать символы-разделители, используемые в этом формате, чтобы избежать неоднозначной интепретации данных.
Обьяснение
Просто добавим поле с «проверочным» значением, «контрольная сумма», или, если хотите, избыточную информацию, равную самому форматированному TREE потоку данных, но без этой контрольной строки, чтобы избежать бесконечно длинного потока данных. Так как все последующие переносы строк нарушат структуру данных, то обратная процедура с декодированиеи этого потока обречена на провал, так как всегда будет существовать по крайней мере одна структура, которая будет неправильно интерпретирована при корректных входных данных, вне зависимости от сложности алгоритма обработки этих данных.
«Потом его в дурку забрали, конечно».
Мда, с заголовком автор явно перегнул.
Дорогой автор, инновации и конкуренция это, как правило, хорошо. И я обычно поддерживаю начинания таких людей как вы. Но в случае с .tree вы рискуете создать программистам лишнюю головную боль, если формат пойдет в массы. Ведь и XML и JSON и YAML никуда не денутся
Но это конечно не повод не делать новый формат, некоторую надежду вселяет возможность двустороннего преобразования.
Но это конечно не повод не делать новый формат, некоторую надежду вселяет возможность двустороннего преобразования.
Чем конкретно создать лишнюю головную боль? Вон майкрософт постоянно новые форматы файлов клепает doc -> docx с многочисленными варияциями — это тоже головная боль? Нужно оставить только один стандарт замшелых годов (txt с поддержкой latin-1 и хватит вам!), а прогресс нужно запретить и всякие попытки карать?
Я несколько утрирую, просто я хочу, чтобы вы подробнее описали, чем именно создастся лишняя головная боль.
Не могу сказать, что я в восторге от задумки автора (как по мне — весьма и весьма сыро), но не могу приветствовать попытку создания своего велосипеда. Уже заставило разобраться в том, как устроены текущие стандарты, какие у них плюсы, минусы — это ли не похвально?
Я несколько утрирую, просто я хочу, чтобы вы подробнее описали, чем именно создастся лишняя головная боль.
Не могу сказать, что я в восторге от задумки автора (как по мне — весьма и весьма сыро), но не могу приветствовать попытку создания своего велосипеда. Уже заставило разобраться в том, как устроены текущие стандарты, какие у них плюсы, минусы — это ли не похвально?
Вон майкрософт постоянно новые форматы файлов клепает doc -> docx с многочисленными варияциями — это тоже головная боль?
И еще какая.
Чем конкретно создать лишнюю головную боль?Интеграцией. Допустим я — программист какой-то инфосистемы. Мне поставили задачу подключить какой-то источник данных, которые передаются в новом формате. Передо мной встает ряд проблем:
1. изучить новый формат
2. Найти библиотеку парсинга для моего языка
3. Или написать свой парсер, если её еще нет.
4. Отладить все баги парсинга
5. Следить за изменениями формата, обновлять парсер.
Этих проблем не было бы, если бы источник поставлял данные в том же XML или JSON, без разницы.
это ли не похвально?Это в любом случае похвально, это и есть прогресс, я об этом написал в первом комментарии.
Вон майкрософт постоянно новые форматы файлов клепает doc -> docx с многочисленными варияциями — это тоже головная боль?Еще какая головная боль.
Думал я о том, что не так с XML и почему его в последнее время променяли, на бестолковый JSON.
Потому что на всех языках есть веб-серверы или работа с сетью. PHP, ruby, python, go etc. Потому что там где работа с сетью — взаимодействие с веб-клиентами и браузерами. Где JS и JSON.parse().
XML — сложная структура, зачастую — обладающая избыточной сложностью, зачастую — сложная для программиста в своей формальности, зачастую — не совпадающая по типам.
Типы JSON — bool, number, string, map/hash/object и array — есть в практически всех языках нативно, и программисты на любом языке не испытывают проблем с осмыслением формата JSON, пусть он и нелеп.
Соответственно — на абсолютно всех языках уже есть рабочие и быстрые реализации парсера JSON и дампера в JSON, которые можно использовать.
А вообще нелепое решение. Непонятно, зачем.
Аргументы типа «он красивый, эффективный и быстрый» — дурацкие.
Аргументы типа «Он такой же простой для реализации парсера в любом языке, как ini-файл, вот доказательство, он парсится в JS быстрее чем встроенный парсер JSON — вот тесты во всех браузерах, он обладает такой же полнотой, как XML — не через трансляцию в XML, а нативно, он более эффективно работает с сетью и гзипается, чем любой из популярных стандартов» — не увидел.
Да и вообще, надо думать не от охренительности решения, а от задачи. Пока нет конкретной задачи или задач, которую продукт решает лучше чем существующие — смысла в нем нет. Поэтому минуснул.
А как на счет аргументов типа — «в нем есть xsd и xslt»?
Это ж будет тупо транскодинг в XML, который есть и в YAML и десятках других собирающихся в XML языков. И да, такого аргумента я не увидел.
Собственно, ситуация следующая:
YAML, насколько я помню, имеет абсолютно спокойный транскодинг в XML, равно как и Tree, разница исключительно в масштабах проектов и уровне поддержки со стороны сообщества (читай, гарантии поддержки и исправления ошибок).
При этом в YAML есть достаточно продуманная система типов, которая в отличии от Tree сделана с оглядкой на большинство языков.
Я, честно говоря, не понимаю как может сочетаться «Произвольная иерархия 5/5» и «Простота реализации 5/5» и «Удобство редактирования 5/5». Дело в том, что реализация — это не только парсер, это еще и перевод системы типов во внутренний формат языка приложения. И если типы YAML или JSON почти всегда имеют полное отражение внутри языка (то есть возможен беспроблемный перевод структуры данных приложение-форматированное представление и форматированное представление-приложение), а XML дает определенные возможности для сложных выборок в дальнейшем, то Tree, как я вижу, не обладает такими возможностями — он вызовет неиллюзорные проблемы на многих структурах во многих языках.
А если говорить про XML — стоит скорее уж спросить, какие есть в Tree возможности перемещения по дереву и выполнения Xpath-запросов. Думаю, это известный факт, что XML это в первую очередь структура данных в памяти, а не просто дамп, иначе можно было бы называть форматом данных и sqlite, например.
Единственный вариант поста, который бы звучал разумно — это
«Эй, чуваки, я запилил еще один формат, который умеет полноценно конвертироваться в XML и JSON, по сравнению с существующими у него такие-то плюшки:
-свободная грамматика, на которой можно реализовать то-то то-то и то-то
-по крайней мере такой же человекочитаемый как и YAML
-есть компактный формат для передачи по сети
-есть потоки
-уже есть плагин для IDEA
-легко сделать библиотеку под свой язык, под D энкодер/декодер размером всего в 100 строк, под JS — 120, вот примеры
и вот как он выглядит:…
»
А все это «да XML хуже, и JSON хуже, и YAML хуже, они все всасывают по всем статьям, вот вам табличка» — это сразу уже настораживает и выглядит как буллшит.
Собственно, ситуация следующая:
YAML, насколько я помню, имеет абсолютно спокойный транскодинг в XML, равно как и Tree, разница исключительно в масштабах проектов и уровне поддержки со стороны сообщества (читай, гарантии поддержки и исправления ошибок).
При этом в YAML есть достаточно продуманная система типов, которая в отличии от Tree сделана с оглядкой на большинство языков.
Я, честно говоря, не понимаю как может сочетаться «Произвольная иерархия 5/5» и «Простота реализации 5/5» и «Удобство редактирования 5/5». Дело в том, что реализация — это не только парсер, это еще и перевод системы типов во внутренний формат языка приложения. И если типы YAML или JSON почти всегда имеют полное отражение внутри языка (то есть возможен беспроблемный перевод структуры данных приложение-форматированное представление и форматированное представление-приложение), а XML дает определенные возможности для сложных выборок в дальнейшем, то Tree, как я вижу, не обладает такими возможностями — он вызовет неиллюзорные проблемы на многих структурах во многих языках.
А если говорить про XML — стоит скорее уж спросить, какие есть в Tree возможности перемещения по дереву и выполнения Xpath-запросов. Думаю, это известный факт, что XML это в первую очередь структура данных в памяти, а не просто дамп, иначе можно было бы называть форматом данных и sqlite, например.
Единственный вариант поста, который бы звучал разумно — это
«Эй, чуваки, я запилил еще один формат, который умеет полноценно конвертироваться в XML и JSON, по сравнению с существующими у него такие-то плюшки:
-свободная грамматика, на которой можно реализовать то-то то-то и то-то
-по крайней мере такой же человекочитаемый как и YAML
-есть компактный формат для передачи по сети
-есть потоки
-уже есть плагин для IDEA
-легко сделать библиотеку под свой язык, под D энкодер/декодер размером всего в 100 строк, под JS — 120, вот примеры
и вот как он выглядит:…
»
А все это «да XML хуже, и JSON хуже, и YAML хуже, они все всасывают по всем статьям, вот вам табличка» — это сразу уже настораживает и выглядит как буллшит.
XPath, XSLT и прочие X-технологии ориентированы на работу с DOM, так что им вообще говоря по барабану какой способ сериализации будет XML или Tree. Но модель Tree более мощная, так что нужно либо ограничиться совместимым с XML подмножеством, либо расширить возможности библиотек, работающих с DOM.
ииии — бинго! Только что вы признались в том, что полный список заявленного функционала будет невозможно использовать в существующих решениях. А значит — хрена с два оно выстрелит.
Допиливать тонны библиотек, чтобы воспользоваться новым решением, никто не станет.
Брать подмножество нового языка тупо чтобы заменить существующее решение без какой-либо выгоды тоже никто не будет (это затраты времени).
А раз в одном из основных языков (да, JS один из основных игроков на рынке) существующие решения не способны переваривать этот формат — никому оно нахрен не нужно. Потому что взаимодействие — штука адски важная.
Да и в других языках ситуация аналогичная.
Допиливать тонны библиотек, чтобы воспользоваться новым решением, никто не станет.
Брать подмножество нового языка тупо чтобы заменить существующее решение без какой-либо выгоды тоже никто не будет (это затраты времени).
А раз в одном из основных языков (да, JS один из основных игроков на рынке) существующие решения не способны переваривать этот формат — никому оно нахрен не нужно. Потому что взаимодействие — штука адски важная.
Да и в других языках ситуация аналогичная.
Не всё ли равно использовать JSON.parse() или XML.parse()? При этом в XML вы XPath-ом можете спокойно и безопасно выгребать данные. А разбирая «нативные структуры JSON» вам придётся вставлять бесконечные if-ы с проверками вида «а передан ли тут массив», «а действительно ли у нас тут объект пришёл» и тп.
JSON хорошо отражается на нативные структуры в одном только JS и то, например, даты не поддерживает, а они нужны почти всегда.
JSON хорошо отражается на нативные структуры в одном только JS и то, например, даты не поддерживает, а они нужны почти всегда.
Насчёт JSON, особенно в применении к языкам типа Java, где он не является нативным форматом и map не является встроенным типом данных, — он хотя бы меньше по размеру чем XML и не несёт в себе избыточной, как показала практика, информации вроде типа узла, которое передаётся через имя тега. Конечно, наличие имени тега очень полезно для валидации и совсем-совсем-тупо-строго-статической типизации, но 1) обычно валидация не требуется и 2) при использовании языка с «просто статической» типизацией (типа той же Java) тип («класс» в терминах ООП) узла обычно более-менее ясен из типа поля, которому его собираются присвоить.
Пока нет конкретной задачи или задач, которую продукт решает лучше чем существующие — смысла в нем нетЯ пока прямо сейчас вижу одну такую задачу — «быстро-быстро», «в режиме потока без регрессий» «набить» относительно большой и относительно сложный (с древовидностью) конфиг-файл. Потом эту «простыню», конечно, в том числе и для большей читаемости (с использованием подсветки скобок), лучше сконвертировать в какой-нибудь JSON (нормальные текстовые редакторы поддерживают pretty-форматирование JSON и XML).
Имеется ли реализация парсера на JS? Хотелось бы в браузере погонять данные между JSON/Yaml и Tree.
Прочитал про «один тип узлов». Возникло подозрение, что прозрачно конвертировать между Tree и JSON/Yaml — невозможно, по крайней мере, без нагромождения Tree дополнительными сущностями (например, добавление служебных узлов, указывающих, является ли родительский узел массивом или словарем).
Имеется, на выходных соберу библиотеку.
Вся суть статьи:

Поточная обработка
[...]
В случае XML [...] такой возможности нет — документ с обрезанным концом или дополнительными данными в конце, является невалидным.
Подождите, вы правда не знаете про SAX и производные от него инструменты для поточного чтения xml-документов?
(нет, я не спорю, что документ нельзя валидировать, пока он не дочитан до конца, а документ, в котором откусили конец — невалиден, но обрабатывать его это ровным счетом никак не мешает)
на этой возможности построен целый XMPP :)
Не могу не отметить, что для XMPP используются специальные парсеры. Причем тут проблема не столько в поточной обработке XML, сколько в необходимости перехода в режим TLS строго после символа >.
При чем здесь парсеры? XMPP использует т.н. XML stanza для общения между нодами.
Из rfc6120:
The Extensible Messaging and Presence Protocol (XMPP) is an application profile of the Extensible Markup Language [XML] that enables the near-real-time exchange of structured yet extensible data between any two or more network entities. This document defines XMPP's core protocol methods: setup and teardown of XML streams, channel encryption, authentication, error handling, and communication primitives for messaging, network availability («presence»), and request-response interactions.
Таким образом XML вполне себе подходит для потоковой обработки.
Из rfc6120:
The Extensible Messaging and Presence Protocol (XMPP) is an application profile of the Extensible Markup Language [XML] that enables the near-real-time exchange of structured yet extensible data between any two or more network entities. This document defines XMPP's core protocol methods: setup and teardown of XML streams, channel encryption, authentication, error handling, and communication primitives for messaging, network availability («presence»), and request-response interactions.
Таким образом XML вполне себе подходит для потоковой обработки.
При том, что обычный потоковый парсер XML не поможет c протоколом XMPP.
На самом деле я согласен с автором комментария выше, т.к. я тоже считаю что ноль в графе «Поддержка поточной обработки» для XML — это не корректно.
Вы так не считаете?
В случае с XMPP, XML выступает транспортом, и даже не смотря на семантику протокола XMPP, XML прекрасно может обрабатываться потоково (по сути поэлементно).
Вы так не считаете?
В случае с XMPP, XML выступает транспортом, и даже не смотря на семантику протокола XMPP, XML прекрасно может обрабатываться потоково (по сути поэлементно).
Разумеется я знаю, что всегда можно запилить инструмент, который не слишком строго следует спецификации, а потому позволяет работать с не совсем валидными данными :-) Но на уровне формата поддержки поточной обработки нет.
Значит, правда не знаете. Иначе бы не говорили, что поддержки нет, когда она вполне есть и прекрасно работает, причем не нарушая никаких спецификаций.
Ага, так и вижу файл логов:
<logs>
<access ip="8.8.8.8" url="/favicon.svg" time="2015-10-12T12:23:00" />
<access ip="8.8.8.8" url="/favicon.svg" time="2015-10-12T12:23:00" />
Зашёл в топик в ожидании коммента про TOML: github.com/toml-lang/toml
Но, к своему удивлению, не нашёл (а ведь rust'оманов на хабре должно быть достаточно).
Так вот, мне кажется, что TOML уже неплохо решает задачу «сделать удобный для ручного редактирования формат представления данных»: он богаче, чем INI, не требует загромождения фигурными скобками, как JSON, и уж тем более, до избыточности XML ему очень далеко :)
Но, к своему удивлению, не нашёл (а ведь rust'оманов на хабре должно быть достаточно).
Так вот, мне кажется, что TOML уже неплохо решает задачу «сделать удобный для ручного редактирования формат представления данных»: он богаче, чем INI, не требует загромождения фигурными скобками, как JSON, и уж тем более, до избыточности XML ему очень далеко :)
Интересная штука, надо будет принять на вооружение.
Годится наверно только для локального применения, в качестве транспорта по сети будет несколько накладно. Каждую запись тщательно отсчитывать табы с начала строки… вот где засада может быть с производительностью парсинга на глубоких структурах.
Может все-таки добавить какой-то механизм сокращения глубины вложенности?
Я как-то тоже изобретал велосипед, в котором можно было бы обходится без парсинга, там тупо в строке имя параметра и после равно и до конца строки — это все данные. А уж разбить двоичные данные на блоки так чтобы они не вызывали ложный перевод строки — это дело более высокого уровня абстракции. Ну и опять же, приложение может запросто хранить эти данные в HEX представлении.
Насчет пробела после равно это зло — усложняет алгоритмы парсинга а играет чисто декоративную роль для человека, привыкнуть к такой несправедливости довольно просто.
Годится наверно только для локального применения, в качестве транспорта по сети будет несколько накладно. Каждую запись тщательно отсчитывать табы с начала строки… вот где засада может быть с производительностью парсинга на глубоких структурах.
Может все-таки добавить какой-то механизм сокращения глубины вложенности?
Я как-то тоже изобретал велосипед, в котором можно было бы обходится без парсинга, там тупо в строке имя параметра и после равно и до конца строки — это все данные. А уж разбить двоичные данные на блоки так чтобы они не вызывали ложный перевод строки — это дело более высокого уровня абстракции. Ну и опять же, приложение может запросто хранить эти данные в HEX представлении.
Насчет пробела после равно это зло — усложняет алгоритмы парсинга а играет чисто декоративную роль для человека, привыкнуть к такой несправедливости довольно просто.
Отсчитывать табы — это совсем не накладно на самом деле. Да, на больших глубинах, будет много накладных расходов на отступы, но у больших глубин есть не мало и других недостатков, из-за которых глубину лучше всё же минимизировать. И задача это не формата, а реализации приложения. Например, вместо того, чтобы передавать модель предметной области в виде развесистого дерева, лучше передавать его в виде плоского списка моделей с перекрёстными ссылками.
А вот создатели языка (не формата) Хаскеля посчитали, что табы полезны для людей, но неудобны для машин, которы будут генерировать код.
Поэтому для людей сделали табы, для машин — точки с запятой(;) и фигурные скобки({}).
Табы не совсем удобны для обработки, в том числе и для перл-подобных регулярных выражений.
Поэтому для людей сделали табы, для машин — точки с запятой(;) и фигурные скобки({}).
Табы не совсем удобны для обработки, в том числе и для перл-подобных регулярных выражений.
Что бы продвинуть подобный формат, надо создать удобную библиотеку, читающую/пишущую все форматы. Тогда пользователи смогут оценить удобство и, если он действительно удачный, перейти на него.
Для любителей командной строки: bat-формат(rem,md,cd,pushd,popd,rd,ren,\):
rem create
md first
pushd first
md child
popd
md second
pushd second
md param1\value1
md param2
cd param2
md value2
popd
rem patch
rd first\child
ren second\param1\value1 updated_value1
rem create
md first
pushd first
md child
popd
md second
pushd second
md param1\value1
md param2
cd param2
md value2
popd
rem patch
rd first\child
ren second\param1\value1 updated_value1
Почему это размер Tree в сериализованном виде меньше чем у JSON? Вы убрали фигурные скобки, но компенсировали их отсутствие табуляцией и символами переноса строки. В итоге ваш Tree по размерам может быть даже больше чем минимизированный JSON.
Тоже не всегда верно, иногда очень удобно представлять объекты списка в виде одной строки, получается своего рода таблица. Или попробуйте описать матрицу в JSON и в вашем Tree.
JSON и XML позволяют произвольно форматировать вывод пробелами и переносами строк. Однако, часто по различным причинам (основные — меньший объём, проще реализация) их форматируют в одну строку и тогда они становятся крайне не читаемыми.
Тоже не всегда верно, иногда очень удобно представлять объекты списка в виде одной строки, получается своего рода таблица. Или попробуйте описать матрицу в JSON и в вашем Tree.
Не совсем понял по какой причине XML и JSON не поддерживают поточную обработку? Имхо вполне можно ставить 3 из 5 как минимум. Никто не мешает начать обработку до полного получения документа, и завершить обработку в случае ошибки в полученных данных.
В чём по вашему заключается «обработка»? Похоже вы понимаете под ней исключительно парсинг. Но парсинг — это просто создание какой-то структуры. Но структура эта создаётся не просто так. Так вот, обработка может включать в себя необратимые действия типа «печать в поток вывода» или «посылка пакетов другому серверу».
Ну как бы поточность в основном и используется для необратимых действий. Зачем строить структуру, если она сразу же будет разрушена? А вот наличие обратных ссылок — вот это уже действительно проблема для поточной обработки, универсального решения для которой нет.
1. Парсинг тоже является частью обработки, поэтому не надо отбрасывать возможность поточного парсинга как таковую. Ваши представления о парсинге неверны, создавать структру необязательно. Например браузеры при рендеринге страниц начинают рандеринг элемента еще до построения полного DOM. +1 к поточной обработке
2. Нет никаких ограничений жестко накладываемых на обработку ни JSON ни XML их форматом. +1 к поточной обработке
3. qt-project.org/doc/qt-4.8/xml-streaming.html
github.com/dominictarr/JSONStream
+1 к поточной обработке
Итого я насчитал 3 по каждому из языков.
2. Нет никаких ограничений жестко накладываемых на обработку ни JSON ни XML их форматом. +1 к поточной обработке
3. qt-project.org/doc/qt-4.8/xml-streaming.html
github.com/dominictarr/JSONStream
+1 к поточной обработке
Итого я насчитал 3 по каждому из языков.
Вообще-то любой парсинг поточный.
1. XHTML браузеры рендерят по спецификации — когда документ полностью подгружен и проверен на соответствие синтаксису XML.
2. Вы не заметили, что кроме поточного чтения, есть ещё поточная запись. Логи, поток сообщений и тп.
1. XHTML браузеры рендерят по спецификации — когда документ полностью подгружен и проверен на соответствие синтаксису XML.
2. Вы не заметили, что кроме поточного чтения, есть ещё поточная запись. Логи, поток сообщений и тп.
2. Вы не заметили, что кроме поточного чтения, есть ещё поточная запись. Логи, поток сообщений и тп.
Ну так и что? Файл же (или куда вы там пишите) когда-нибудь закончится, и в конец запишутся все требуемые спецификацией окончания. Вы же все равно с другого конца тоже поточно читаете. Так какая разница, до начала чтения существовал весь файл или нет. А если чтение не поточное, так извольте дождаться, пока все данные будут записаны, в том числе и окончания (для читающего вообще нет надобности в этом случае ждать, что там пишется в данный момент — файл или записан или нет, это все, что его волнует).
Вы слишком преувеличиваете необходимость иметь структуру данных, точно соответствующую спецификации, в любой момент времени
Разница в интероперабельности. Если вы генерируете файл похожий на XML, но для работы с которым подойдут не любые XML парсеры, а только «особые», то вы не имеете права называть этот файл XML. Это некоторое расширение XML с нужными вам свойствами.
А логи никогда не завершатся — такая у них особенность, что всегда должна быть возможность что-то в них добавить.
А логи никогда не завершатся — такая у них особенность, что всегда должна быть возможность что-то в них добавить.
В нормальных системах файлы логов ротируются — прочитать за раз файл лога в несколько гигабайт несколько проблематично. А если читать частями, то какая разница, валидный у него конец или нет?
Любой парсер, пока разбирает файл, работает с неполной структурой — неважно, в памяти она уже вся или дочитывается по требованию. «Не особые» парсеры просто по окончании разбора имеют неотключаемую проверку валидности, без которой можно и обойтись. Опять же, эти «не особые» парсеры в принципе нельзя использовать для данных, которые постоянно дописываются — они работают только со статическими данными, а они подразумеваются корректными (лог закрывается, окончание, требуемое спецификацией, в него дописывается => он становится валидным).
Отличие от вашего формата только в том, что для него нельзя постоить «не особый» парсер — все будут «особыми». Ну как бэ к формату данных это отношение не имеет.
Говорить о том, можно ли называть файл XML или нет, можно только после того, как он будет сформирован полностью. А пока мы его не закончили, вопрос висит в воздухе (естественно, если мы пишем валидные части XML, если записали уже что-то невалидное то и результат будет невалидным). Поэтому вполне можно называть этот файл XML-ом.
Любой парсер, пока разбирает файл, работает с неполной структурой — неважно, в памяти она уже вся или дочитывается по требованию. «Не особые» парсеры просто по окончании разбора имеют неотключаемую проверку валидности, без которой можно и обойтись. Опять же, эти «не особые» парсеры в принципе нельзя использовать для данных, которые постоянно дописываются — они работают только со статическими данными, а они подразумеваются корректными (лог закрывается, окончание, требуемое спецификацией, в него дописывается => он становится валидным).
Отличие от вашего формата только в том, что для него нельзя постоить «не особый» парсер — все будут «особыми». Ну как бэ к формату данных это отношение не имеет.
Говорить о том, можно ли называть файл XML или нет, можно только после того, как он будет сформирован полностью. А пока мы его не закончили, вопрос висит в воздухе (естественно, если мы пишем валидные части XML, если записали уже что-то невалидное то и результат будет невалидным). Поэтому вполне можно называть этот файл XML-ом.
В чем отличие tree тогда? Задача парсера отыскать известные ему поля и интерпретировать их конечному пользователю, будь-то человек или 3-я(здесь читаем 3rd party) программа. И опять же не понимаю при чем тут поточность? Я привел вам 3 довода, которые позволяют сделать вывод, что поточная обработка XML и JSON возможна. И прошу добавить 3 к поточной обработке этих форматов. Не 5, я понимаю что они не идеальны, а 3. Просто для меня это выглядит сейчас так:
Максимальнообосрем польем грязью конкурентов, чтобы те, кто не понимает суть вопроса пришли к нам.
Максимально
Возможна, но не гарантирована. Я не могу в любой момент времени взять xml-log файл и скормить его любому xml-парсеру.
А по вашей логике любой формат поддерживает поточную обработку, что делает этот критерий сравнения бессмысленным.
А по вашей логике любой формат поддерживает поточную обработку, что делает этот критерий сравнения бессмысленным.
Зачем любому XML-парсеру это уметь? Если бы стояла такая задача — давно бы уже любой умел?
Мы же обсуждаем свойства форматов, а не используемых инструментов? Для Tree точно так же можно написать не поддерживающий поточную обработку парсер — просто возвращающий целиком спарсенный документ (и таких инструментов будет большинство).
Мы же обсуждаем свойства форматов, а не используемых инструментов? Для Tree точно так же можно написать не поддерживающий поточную обработку парсер — просто возвращающий целиком спарсенный документ (и таких инструментов будет большинство).
Затем, что если любой соответствующий спецификации инструмент не может прочитать ваш XML, то вы написали не XML. Можете назвать этот формат endless-xml и задекларировать все его особенности, как это сделали с HTML5, но не стоит вводить всех в заблуждение.
Наличие поддержки чего-то не требует её использовать.
Наличие поддержки чего-то не требует её использовать.
Затем, что если любой соответствующий спецификации инструмент не может прочитать ваш XML, то вы написали не XML.
Любой сможет. Мы же обсуждаем способы, которыми инструменты будут это делать, а не конечный результат.
Вопрос то в другом, для 99% использований это не нужно — поэтому спецификация такая. А для чего засовывать потребности 1% в каждый инструмент для формата?
ГОСТ по стиральной машине, а вдруг там паре человек понадобится резчик по плитке — давайте в стандарте предусмотрим возможность припихнуть его сзади?
Вообще-то, согласно спецификации, инструмент, встретив не-well-formed документ, должен прекратить обработку и выдать ошибку. Но это не означает, что он должен выкинуть все, что раньше прочитано.
(SAX правда существует)
(SAX правда существует)
Не нужно путать понятия «прочитал» и «еще читает» (а еще читает потому, что другая сторона еще пишет). Соответствие спецификации указывается для готовых документов, а ни как для их частей.
Назовите формат dotree (DOT-Tree)
Доработайте формат для случаев, которые вам описали участники…
Вообще, табуляция плохой знак, его истинный смысл был для создания колонок, и движения между колонками с заданной шириной…
почему бы не пробел просто и спец-символ для конца передачи, например, два переноса строки?
apple
color=red
size=large
orange
color=orange
etc
Доработайте формат для случаев, которые вам описали участники…
Вообще, табуляция плохой знак, его истинный смысл был для создания колонок, и движения между колонками с заданной шириной…
почему бы не пробел просто и спец-символ для конца передачи, например, два переноса строки?
apple
color=red
size=large
orange
color=orange
etc
У json'а есть поточная обработка. Я застрял в прокрастинации, но у меня написан работающий stream, парсящий и yield'ящий элементы по мере поступления. Используется библиотека github.com/dominictarr/JSONStream
А пока что я не понимаю, зачем оно нужно. То есть вы мне говорите «человекочитаемость 5», но я этого не вижу. А уж удобство редактирования… В json, по крайней мере, чуть-чуть лишних пробелов не сносят голову парсеру.
У JSON'а сложившаяся экосистема, и он не достаточно отвратительный, чтобы хотеть его выкинуть только за то, как он выглядит (прощай, xml).
А пока что я не понимаю, зачем оно нужно. То есть вы мне говорите «человекочитаемость 5», но я этого не вижу. А уж удобство редактирования… В json, по крайней мере, чуть-чуть лишних пробелов не сносят голову парсеру.
У JSON'а сложившаяся экосистема, и он не достаточно отвратительный, чтобы хотеть его выкинуть только за то, как он выглядит (прощай, xml).
Это ж лисповые символьные выражения, только с переносом строк и знаком «равно» вместо скобок.
> Если в Lisp всё описывается как списки, то в языке на основе Tree — всё есть деревья.
Вообще-то в лиспе даже список — это суть бинарное дерево. И угадайте, что такое список списков? Правильно — дерево.
> Если в Lisp всё описывается как списки, то в языке на основе Tree — всё есть деревья.
Вообще-то в лиспе даже список — это суть бинарное дерево. И угадайте, что такое список списков? Правильно — дерево.
Мне кажется в заголовке вы намутили: «убийца». У человека изначально возникают не самые приятные подсознательные процессы связанные с этим словом, если бы была самоирония, думаю большему кол-ву людей понравилось бы.
П.С. Ваш диванный аналитик.
П.С. Ваш диванный аналитик.
То есть вы утверждаете, что большинство людей не способно пользоваться верхним полушарием мозга и любую новую идею воспринимают исключительно эмоционально?
Ну я такого не утверждал и вообще говорил о заголовке и его восприятии (ведь вначале мы читаем заголовок). + Покажите мне такого человека который вообще не испытывает эмоций (тем у кого отрезали часть мозга — не всчет), а что значит «исключительно эмоционально» я не знаю, эмоции испытываются в принципе всегда. Вон Сталлман например, скажите ему что вы пропогандируете проприетарщину, ставите виндоус и т.д., волна эмоций гарантирована.
Вы пришли убить все остальные стандарты, как бы «гарантируя» то что Tree лучше чем JSON, XML, YAML и др. Но не всем он понравился, в силу разных причин. Есть люди в треде кому он понравился (их минусуют), некоторым нет (их плюсуют), какие выводы из всего этого можно сделать? Над Tree надо ещё работать и пилить, но самое главное что никто не остался к Tree равнодушен, это хорошо если он вызывает бурные дискуссии, в спорах рождается правда.
Мне Tree не кажется удобным, особенно раздражает 1 пробел перед "=", дело привычки, да, но заставлять себя уже не удобно. Лично мне нравятся: TOML и YAML.
Для Tree я бы поставил удобность: 3.5 — 4, ну уж точно не 5
Вы пришли убить все остальные стандарты, как бы «гарантируя» то что Tree лучше чем JSON, XML, YAML и др. Но не всем он понравился, в силу разных причин. Есть люди в треде кому он понравился (их минусуют), некоторым нет (их плюсуют), какие выводы из всего этого можно сделать? Над Tree надо ещё работать и пилить, но самое главное что никто не остался к Tree равнодушен, это хорошо если он вызывает бурные дискуссии, в спорах рождается правда.
Мне Tree не кажется удобным, особенно раздражает 1 пробел перед "=", дело привычки, да, но заставлять себя уже не удобно. Лично мне нравятся: TOML и YAML.
Для Tree я бы поставил удобность: 3.5 — 4, ну уж точно не 5
Кстати, полезно периодически менять свои привычки. Это позволяет мозгу оставаться в форме и не стагнировать. Привычки — это как сидячий образ жизни для мозга.
Все ли нюансы языка YAML вы знаете? ;-)
Все ли нюансы языка YAML вы знаете? ;-)
Абсолютно все ньюансы знать и не обязательно (неужели все изучают всё только по спецификации? Не верю), вопрос в другом, как часто с ними встречаются. Если конфиг файлы какие-нибудь, переводы и т.п. то там ньюансов много не надо. Или я не прав?
Ну, вон выше подсказывают некоторые нюансы, чтобы понять которые нужно внимательно почитать спеку (которая, впрочем, довольно хороша — формальная грамматика богато иллюстрированная примерами)
И чтобы прочитать данные, например, в яваскрипт, нужно исполнить их в виртуальной машине луа?
Да. Для JavaScript и других языков есть способы исполнить Lua (интерпретаторы, трансляторы, виртуальные машины). Реализация Lua занимает 100 килобайт — меньше, чем jquery.
100кб — это очень дофига для «библиотеки чтения конфигов». И по скорости она, уверен, та ещё черепаха.
Луа — не черепаха. Скорость загрузки Lua-файла с данными доходит до десятка мегабайт в секунду. 100 кб на чтение конфига — расточительно, а для организации хранения всех данных уже вполне нормально смотрится. Особенно это хорошо, если у вас на сервере тоже Lua. (А если сервер на JavaScript и nodejs, то не вижу смысла рыпаться — используйте JSON.)
А я вот имею смысл рыпаться.
MongoQuery:
MongoQueryTree:

MongoQuery:
{
$or: [
{ qty: { $gt: 100 } },
{ price: { $lt: 9.95 } }
]
}
MongoQueryTree:
Первый вариант не так уж плох. Точнее, скажем так: он не так плох, чтобы изобретать замену.
В конце концов, если станет неприятно писать такое руками, всегда можно сделать генератор.
Есть ещё кое-что: JSON не позволяет ошибаться. Забыл кавычку и парсинг не проходит. А в вашем формате пропади хоть полфайла и всё распарсится. Мне кажется, что надёжность в этом месте важнее, чем человекочитаемость.
В конце концов, если станет неприятно писать такое руками, всегда можно сделать генератор.
Есть ещё кое-что: JSON не позволяет ошибаться. Забыл кавычку и парсинг не проходит. А в вашем формате пропади хоть полфайла и всё распарсится. Мне кажется, что надёжность в этом месте важнее, чем человекочитаемость.

Стоп, где тут знак =, с которого начинается узел-значение?
В данном языке числа записываются в узлы-имена.
Так мне что, самому теперь эти выражения парсить? Но это же (цензура).
Знаете, я вот только что придумал новый формат. На нем можно писать что угодно и как угодно, парсер такого формата занимает ноль байт, а интерпретация результата парсинга — это уже задача прикладного уровня. Мне кажется, такой формат получился еще проще вашего, не правда ли?
Кстати, мой формат, в отличие от вашего, действительно бинарно безопасен.
Знаете, я вот только что придумал новый формат. На нем можно писать что угодно и как угодно, парсер такого формата занимает ноль байт, а интерпретация результата парсинга — это уже задача прикладного уровня. Мне кажется, такой формат получился еще проще вашего, не правда ли?
Кстати, мой формат, в отличие от вашего, действительно бинарно безопасен.
однозначно — 0 паттернов! Это рекорд )))
AnyData — вот название. Вскоре смотрите код на Гитхабе!
AnyData — вот название. Вскоре смотрите код на Гитхабе!
vintage, У вас есть недопонимание к тому, что вам говорят.
Когда вам говорят, что типы ваш формат не поддерживает, это не значит, что нельзя сэмулировать подобное поведение. Но эта эмуляция не является частью вашего формата.
Когда говорят, что нужно экранировать бинарные данные от перевода строки — это означает обработку перед тем, как записать. И это правда. Не понятно, почему вы отрицаете это, если вы сами об этом пишите.
Чего вы ваш формат защищаете как тяжело больного? Учитывайте критику.
Когда вам говорят, что типы ваш формат не поддерживает, это не значит, что нельзя сэмулировать подобное поведение. Но эта эмуляция не является частью вашего формата.
Когда говорят, что нужно экранировать бинарные данные от перевода строки — это означает обработку перед тем, как записать. И это правда. Не понятно, почему вы отрицаете это, если вы сами об этом пишите.
Чего вы ваш формат защищаете как тяжело больного? Учитывайте критику.
Я прекрасно понимаю о чём вы говорите, но вы упорно игнорируете мой тезис о том, что формат должен быть отделён от языков, как это сделано в XML, а не навязывать 6 типов данных, «которых хватит всем», как JSON.
А обработка нужна не перед тем как записать, а перед тем как поместить в дерево. И обработка минимальная, а не как у JSON или XML.
А обработка нужна не перед тем как записать, а перед тем как поместить в дерево. И обработка минимальная, а не как у JSON или XML.
Минимальная обработка — это та, которая делается в одну строчку. И никому не интересно, сколько строчек библиотеки скрыто за этой одной.
А с другой стороны, когда у вас куча никак не связанных между собой типов данных, начинается каша, начиная от банального, «как их сравнивать?» (читай — упорядочивать); как определить, это одно и то же значение или нет (читай — как проверять эквивалентность).
Кому-то не хватает этих пресловутых 6 типов данных (хотя согласен, разделение int/float было бы уместно)?
Кому-то не хватает этих пресловутых 6 типов данных (хотя согласен, разделение int/float было бы уместно)?
Да, например, мне очень не хватает «дат» и «ссылок». А также наличия не только предиката «равно», а ещё и предикатов «больше», «меньше» и других.
С датами соглашусь, а что в вашем понимании ссылки? Ссылка — по определению непредставимая сущность в человекочитаемом формате. Так как она означает «пойди туда, куда я показываю, и прочитай то, что там написано, а потом вернись сюда». Не человекочитаемо ни разу. Все ссылки эмулируются через другой тип данных — будь то номер или мнемоническое имя в определенном массиве.
Что-то не очень понимаю, о чем вы. Какие в формате данных могут быть предикаты? Предикат — это поведение, определяемое конкретными типами выражения в предикате. А есть такие типы в JSON, где есть предикат «равно», но нет «больше» и «меньше» и каких-то «других» (каких?)?
А также наличия не только предиката «равно», а ещё и предикатов «больше», «меньше» и других.
Что-то не очень понимаю, о чем вы. Какие в формате данных могут быть предикаты? Предикат — это поведение, определяемое конкретными типами выражения в предикате. А есть такие типы в JSON, где есть предикат «равно», но нет «больше» и «меньше» и каких-то «других» (каких?)?
Через строки можно сэмулировать вообще любой формат. Не только даты и ссылки.
В JSON это совершенно не наглядно эмулируется в духе MongoQuery.
{
"age" : 30
}
age : 30
age > 30
age < 30
age $between
20
40
age $odd
В JSON это совершенно не наглядно эмулируется в духе MongoQuery.
Для себя я давно уже выбрал YAML.
Единственное что в нем не хватает — возможность работать к другим свойствам объекта, т.е.:
Единственное что в нем не хватает — возможность работать к другим свойствам объекта, т.е.:
object:
a: 1
b: a + 1
посмотрите на «человеческий» JSON: hjson.org
А зря, почитайте.
Что ж, если не хотите читать статью, то повторю в коментарии.
При помещении в дерево данные разрезаются на куски с выпиливанием символов перевода строк, после чего дерево может быть сериализовано.
После парсинга, восстанавливается то же самое дерево, и, при необходимости, данные могут быть восстановлены в исходном виде, путём соединения кусков, с символом перевода строки в качестве разделителя.
Примерно так выглядит всё это в сериализованном виде:
При помещении в дерево данные разрезаются на куски с выпиливанием символов перевода строк, после чего дерево может быть сериализовано.
После парсинга, восстанавливается то же самое дерево, и, при необходимости, данные могут быть восстановлены в исходном виде, путём соединения кусков, с символом перевода строки в качестве разделителя.
Примерно так выглядит всё это в сериализованном виде:
Ну так это и есть экранирование — просто вы экранируете только переводы строк (и знаки =).
Нет, данные просто разрезаются. Содержимое int-10 представляется в виде 2 узлов — одного пустого и второго состоящего из трёх нулей.
Условно можно сказать, что используется экранирование вида «после каждого перевода строки вставляется некоторое число табов, зависящее от контекста, после которых вставляется символ равенства», но это какое-то странное получается «экранирование» :-)
Экранирование всё же — это специальная управляющая конструкция, которая предотвращает работу другой управляющий конструкции. В данном же случае все (аж целая одна!) управляющая конструкция работает неизменно, создавая соответствующую структуру. И вот в этой структуре и прячется информация и вырезанных переводах строк.
Условно можно сказать, что используется экранирование вида «после каждого перевода строки вставляется некоторое число табов, зависящее от контекста, после которых вставляется символ равенства», но это какое-то странное получается «экранирование» :-)
Экранирование всё же — это специальная управляющая конструкция, которая предотвращает работу другой управляющий конструкции. В данном же случае все (аж целая одна!) управляющая конструкция работает неизменно, создавая соответствующую структуру. И вот в этой структуре и прячется информация и вырезанных переводах строк.
Какой формат — такое и экранирование. Суть в том, что я не могу просто встать в потоке на конкретное место и читать байтики вперед, я должен обязательно учитывать, что если мне попадется конкретная последовательность, то я должен поступить так-то и так-то, причем это поведение еще и зависит от того, что было до места, откуда я начал читать. Так что нет, ни о какой бинарной безопасности в вашем формате речи не идет (в отличие, кстати, от ASN.1 BER).
Нет. Конкретно после каждого байта, обозначающего перевод строки в вашем формате надо добавлять произвольное количество табов(зависит от контекста) и =, то есть если в адекватных форматах вроде json нагрузка в виде простейшего слеша, которую можно убрать простым replace, у вас экранируование идет с помощью строки неизвестной длины, которую кроме как регуляркой никак нормально не распарсить.
Экранирование всё же — это специальная управляющая конструкция, которая предотвращает работу другой управляющий конструкции.
Нет.
"\0\r\n\t\\\"" — кто здесь кого предотвращает?
На самом деле:
Экранирование символов — замена в тексте управляющих символов на соответствующие текстовые подстановки.(с) Wikipedia
Вы описали много плюсов. Но минусов технических я не видел в статье. То, что они есть уже все поняли. Может вы опишите их в статье, что бы каждый читающий до прочтения комментариев задумался над ними?
Суть большинства комментариев сводится к «чё-то как-то не привычно» :-)
Ну не правда же.
Вот вы говорите, что преимуществом хранения бинарных данных в вашем формате перед base64 является то, что для хранения декодированного base64 кода надо отдельно место выделять при парсинге и нельзя просто дать указатель на блок данных в документе.
Но дело в том, что у вас тоже нельзя просто дать указатель на блок данных.
Потому что блок бинарных данных в вашем формате разделен на части.
Один хрен надо выделять память отдельно и там собирать бинарные данные в цельный кусок.
Вы просто не хотите видеть очевидные проблемы вашего формата. Что характерно — ровно теже самые проблемы в других форматах вами выцепляются.
Вот вы говорите, что преимуществом хранения бинарных данных в вашем формате перед base64 является то, что для хранения декодированного base64 кода надо отдельно место выделять при парсинге и нельзя просто дать указатель на блок данных в документе.
Но дело в том, что у вас тоже нельзя просто дать указатель на блок данных.
Потому что блок бинарных данных в вашем формате разделен на части.
Один хрен надо выделять память отдельно и там собирать бинарные данные в цельный кусок.
Вы просто не хотите видеть очевидные проблемы вашего формата. Что характерно — ровно теже самые проблемы в других форматах вами выцепляются.
Нет, достаточно хранить ссылки на участки памяти. Но да, если вам нужно передать данные в функцию, которая требует именно непрерывного массива байт (а не список ссылок, например), то придётся пройтись пачкой memcpy для выстраивания данных в одну линию.
Ну ок.
Довод «в других парсерах нужно отдельно выделять память» — отменяется, т.к. в этом пункте отличия вашего парсера от «других» нет никакого. Что там, что там придется выделять память и проводить определенные операции чтобы преобразовать данные представленные в формате в рабочие данные.
Довод «в других парсерах нужно отдельно выделять память» — отменяется, т.к. в этом пункте отличия вашего парсера от «других» нет никакого. Что там, что там придется выделять память и проводить определенные операции чтобы преобразовать данные представленные в формате в рабочие данные.
Мы можете работать и с данными представленными в формате через соответствующие декораторы.
Я могу сделать декоратор, который позволит читать и записывать в поточном режиме бинарные данные, закодированные в base64, без использования дополнительной памяти. Такой декоратор позволит хранить бинарные данные в файле любого формата. Чем такой способ принципиально отличается от того, что предлагаете вы?
А мне больше всего нравится формат сериализованных данных PHP. Я его воспринимаю как «человекопонятный» ASN.1. И никаких проблем с экранированием.
vintage — убийца Tree…
Всегда не любил, когда критикуя xml пишут следующие:
《user》《name》Bob《/name》《age》32《/age》《/user》
Конечно это не читаемо. Любой нормальный человек напишет:
《/user name=«Bob» age=«32»》
А это даже очень человекочитаемо
P.s. < заменил на 《 из за парсера хабра
《user》《name》Bob《/name》《age》32《/age》《/user》
Конечно это не читаемо. Любой нормальный человек напишет:
《/user name=«Bob» age=«32»》
А это даже очень человекочитаемо
P.s. < заменил на 《 из за парсера хабра
а слэш в начале для чего?
Тоже хотел про это написать, но вылетело из головы.
Касаемо парсера, а почему не использовать тег source?
Касаемо парсера, а почему не использовать тег source?
<source lang="xml"><user name="Bob" age="32" /></source>Можно использовать для этих целей > как > и < как <
как насчет этих пунктов критики:?
- нужно выбирать между атрибутами и дочерними узлами:
<size><width>100</width><height>100</height></size> <size width=100 height=100 /> - невалидность атрибутов без значений:
<input type='checkbox' checked /> <select multiple /> - нет простого способа задать порядок элементов
нет простого способа задать порядок элементовЭлементы, сюрприз, в файле идут в некотором порядке. Какой еще порядок элементов нужен?
>Какой еще порядок элементов нужен?
гарантированное сохранение порядка от входа в сериализатор до выхода из парсера
имел ввиду, что
Первый случай тут, чтобы побороть рекомендуют xsd:sequence, а тут поясняется, что таким способом можно задать порядок только для первого случая.
Цитата отсюда:
«The XML 1.0 Spec does not say anything about the order of elements with equal names as children of the same parent element. So it seems, the issue is undefined.» подтверждает наличие проблемы во втором случае. Знаю, что это, конечно, не тянет на пруфлинк, но как можно доказать отсутствие упоминания в стандарте. Поэтому, если кто найдет, пожалуйста напишите.
Для решения второго случая вроде бы подходит relax_ng.
Знаю, что обычно подобных проблем не возникает, но тут наблюдается нечто похожее на неопределенное поведение.
гарантированное сохранение порядка от входа в сериализатор до выхода из парсера
имел ввиду, что
<first>somevalue</first>
<second>somevaue</second>
<second>somevaue</second>
<first>somevalue</first>
<element>fist</element>
<element>second</element>
<element>second</element>
<element>fist</element>
Первый случай тут, чтобы побороть рекомендуют xsd:sequence, а тут поясняется, что таким способом можно задать порядок только для первого случая.
Цитата отсюда:
«The XML 1.0 Spec does not say anything about the order of elements with equal names as children of the same parent element. So it seems, the issue is undefined.» подтверждает наличие проблемы во втором случае. Знаю, что это, конечно, не тянет на пруфлинк, но как можно доказать отсутствие упоминания в стандарте. Поэтому, если кто найдет, пожалуйста напишите.
Для решения второго случая вроде бы подходит relax_ng.
Знаю, что обычно подобных проблем не возникает, но тут наблюдается нечто похожее на неопределенное поведение.
Это все верно в том случае, если вы читаете в DOM, а не потоковой читалкой. Потоковая прекрасно сохраняет порядок ровно в том виде, в котором он в файле.
Ситуация тут не такая печальная, как в C/C++ с неопределенным поведением. Если там мы порой вынуждены писать так, чтобы программа компилировалась любым компилятором — то в случае с XML нет никакой необходимости работать с любой библиотекой: можно выбрать одну любимую и использовать ее. Таким образом, если нам важен порядок элементов — надо просто выбрать такую библиотеку для работы с XML, которая нам этот порядок сохранит.
Кстати, вы ошибаетесь, говоря фразу «семантически некорректно» в контексте XML. Дело в том, что XML определяет лишь синтаксис, семантика же лежит уровнем выше.
Кстати, вы ошибаетесь, говоря фразу «семантически некорректно» в контексте XML. Дело в том, что XML определяет лишь синтаксис, семантика же лежит уровнем выше.
Вы не ту спеку читаете. XML — это формат представления. DOM — объектная модель. www.w3.org/TR/DOM-Level-2-Core/core.html#ID-1451460987
где это вы увидели у меня упоминание о DOM.
а за ссылку спасибо.
а за ссылку спасибо.
Вы его подразумеваете, говоря, что XML что-то там не гарантирует. XML — это синтаксис, у него есть один единственный порядок — порядок следования в документе. Интерпретация XML — это уже объектная модель. В ней уже появляются структуры в памяти, которые могут хранить данные упорядоченными, не упорядоченными или даже отсортированными.
Про порядок уже написали, а различие между атрибутами и дочерними узлами — это не проблема. Если вам нужна эта семантика, вы ей пользуетесь, если нет — используете везде дочерние элементы.
А еще в xml есть пространства имен, о которых tree ни слухом, ни духом.
А еще в xml есть пространства имен, о которых tree ни слухом, ни духом.
В XML это тоже отдельная спецификация
<user
name="Alice"
name_2="Mary"
age="20"
>
<like id="1233">book</like>
<like id="1234">movie</like>
</user>
Половина свойств юзера находится в атрибутах, половина в элементах. Атрибуты не могут повторяться, а вот свойства — вполне. Когда атрибутов много — их приходится выстраивать в столбик.
Если бы я создавал свой подобный формат, я бы вообще обошелся без знака равенства. Первый пробел — вот вам и разделитель. И всё.
В частности, на удобство формата структурированного текста можно смотреть по крайней мере с двух сторон: а) удобство написания (куска) текста на нём и б) удобство чтения текста на нём (в том числе и с помощью специализированных редакторов типа как с подсветкой соответствующих закрывающих скобок). И это, в общем, также нередко во многом противоположные вещи…
«Набивать» явно проще табами, читать иногда компактнее и удобнее с подсветкой скобок…
«Набивать» явно проще табами, читать иногда компактнее и удобнее с подсветкой скобок…
Чаще можно найти разумный компромис не впадая в крайности.
Знаете, я то и дело получаю то тут, то там JSON в одну строку и приходится копировать его и бьютифицировать отдельным инструментом. И вот таким «удобством» я очень хочу пожертвовать в пользу формата, в котором нельзя сделать какашку. А с какой стороны пробел ставить — это мелочи, к которым привыкаешь за один день.
Попробую переписать табличку из поста с учётом обсуждения:
Человекопонятность — 3 (есть проблемы с пониманием, где ключ, а где значение, почему нужен пробел перед равенством, а после не нужен и т. п. — требует довольно строгого парсера в голове. Плюс, бинарные данные не человекопонятны, в отличие от конкурентов)
Удобство редактирования — 2 (для редактирования человеком требуется предварительная специальная настройка текстового редактора, да ещё и не всякий редактор позволит редактировать произвольные бинарные данные. Ни у одного конкурента таких проблем нет.)
Бинарная безопасность — 1 (теоретически формат поддерживает бинарные данные, на практике их очень легко «сломать», а какие-либо проверки целостности отсутствуют)
Произвольная иерархия — 5
Простота реализации — 5
Скорость парсинга/сериализации — 5 (на уровне конкурентов)
Размер в сериализованном виде — 5 (на уровне конкурентов)
Поддержка поточной обработки — 5 (на уровне конкурентов)
Распространённость — 0 (не имеет смысла, формат новый)
Поддержка редакторами — 1 (не имеет смысла, формат новый)
Поддержка языками программирования — 1 (не имеет смысла, формат новый)
Человекопонятность — 3 (есть проблемы с пониманием, где ключ, а где значение, почему нужен пробел перед равенством, а после не нужен и т. п. — требует довольно строгого парсера в голове. Плюс, бинарные данные не человекопонятны, в отличие от конкурентов)
Удобство редактирования — 2 (для редактирования человеком требуется предварительная специальная настройка текстового редактора, да ещё и не всякий редактор позволит редактировать произвольные бинарные данные. Ни у одного конкурента таких проблем нет.)
Бинарная безопасность — 1 (теоретически формат поддерживает бинарные данные, на практике их очень легко «сломать», а какие-либо проверки целостности отсутствуют)
Произвольная иерархия — 5
Простота реализации — 5
Скорость парсинга/сериализации — 5 (на уровне конкурентов)
Размер в сериализованном виде — 5 (на уровне конкурентов)
Поддержка поточной обработки — 5 (на уровне конкурентов)
Распространённость — 0 (не имеет смысла, формат новый)
Поддержка редакторами — 1 (не имеет смысла, формат новый)
Поддержка языками программирования — 1 (не имеет смысла, формат новый)
Вы всё же путаете человекопонятность и привычность. Пробел слева, а не справа — не привычно, но понятность одна и та же. И какая может быть проблема с пониманием, если в спеке чёрным по белому написано — всё, что начинается с символа равенства — значения? А бинарные данные и не должны быть понятны человеку, они должны не теряться из-за шибко гибкого формата, не различающего различные переводы строк и отступы.
Если требуется настройка редактора — это всё же проблема редактора, а не формата. Не путайте курицу и яйцо. Проблема не шибко значительная и одноразовая. Не преувеличивайте её значимость. Бинарные данные в другие форматы вообще нельзя вставить, а тут видите ли редактировать не в каждом редакторе можно. Политика двойных стандартов? К тому же, никто не заставляет пихать бинарные данные в Tree. Если планируется ручное редактирование, то лучше использовать base64 или даже base128.
Если требуется настройка редактора — это всё же проблема редактора, а не формата. Не путайте курицу и яйцо. Проблема не шибко значительная и одноразовая. Не преувеличивайте её значимость. Бинарные данные в другие форматы вообще нельзя вставить, а тут видите ли редактировать не в каждом редакторе можно. Политика двойных стандартов? К тому же, никто не заставляет пихать бинарные данные в Tree. Если планируется ручное редактирование, то лучше использовать base64 или даже base128.
> К тому же, никто не заставляет пихать бинарные данные в Tree. Если планируется ручное редактирование, то лучше использовать base64 или даже base128.
С ума сойти, всего три дня коллективных усилий Хабражителей — и Вы сдвинули свою точку зрения на два микрона. Значит, есть надежда:)
С ума сойти, всего три дня коллективных усилий Хабражителей — и Вы сдвинули свою точку зрения на два микрона. Значит, есть надежда:)
Бинарная безопасность — это возможность, которой можно пользоваться (вставлять нетекстовые символы), а можно и не пользоваться (ограничиваться только текстовыми символами). Именно на бинарной безопасности основано отсутствие необходимости экранирования. Всё, что вы набираете с клавиатуры будет записано как есть, без необходимости вставлять по среди текста какие-то левые символы. Единственное ограничение — так как формат иерархический и эту иерархию показывают отступы, то необходимо вставлять спецсимвол перед каждой строкой, показывающий, где заканчивается структура и начинаются данные. А хабражители любят бороться с ветряными мельницами, да.
>отсутствие необходимости экранирования
>необходимо вставлять спецсимвол перед каждой строкой
лол, просто лол) как же тяжело быть настолько не признающим критики, наверное ))
>необходимо вставлять спецсимвол перед каждой строкой
лол, просто лол) как же тяжело быть настолько не признающим критики, наверное ))
У вас есть три объективные проблемы:
1. Ограничение на ключи
С этим явно нужно что-то делать. Думаю, объяснять почему смысла нет.
2. Разделитель ключа и значения " ="
Вам, почему-то, кажется, что это совершенно неважная вещь. Но, я думаю, вы уже заметили, что многим это совершенно не нравится. Не потому, что это не привычно, а потому, что на это больно смотреть. Вы, наверняка, знаете это чувство, когда смотришь на код, который делает все как нужно, но выглядит «не так».
Кроме того, вы обосновываете это решение тем, что «это целый лишний пробел». Но, во-первых, в современных реалиях удобство программиста ставится выше эффективности кода (не могу сказать хорошо это или плохо, но это так). А во-вторых, вы все равно не сделаете здесь более эффективно, чем чисто бинарные форматы.
Так есть ли смысл ставить под удар «юзабельность», ради выигрыша нескольких байт?
3. Необходимость экранирования переноса строки в сырых данных.
Расходы на экранирование будут возрастать пропорционально объему этих данных. То же самое при извлечении этих данных. Здесь, кстати, есть и другая проблема: придется перевыделять память каждый раз, как мы дойдем до предела буффера, потому, что не известно сколько нужно еще считать
Решить это можно, например, введя спецификатор размера значения.
1. Ограничение на ключи
С этим явно нужно что-то делать. Думаю, объяснять почему смысла нет.
2. Разделитель ключа и значения " ="
Вам, почему-то, кажется, что это совершенно неважная вещь. Но, я думаю, вы уже заметили, что многим это совершенно не нравится. Не потому, что это не привычно, а потому, что на это больно смотреть. Вы, наверняка, знаете это чувство, когда смотришь на код, который делает все как нужно, но выглядит «не так».
Кроме того, вы обосновываете это решение тем, что «это целый лишний пробел». Но, во-первых, в современных реалиях удобство программиста ставится выше эффективности кода (не могу сказать хорошо это или плохо, но это так). А во-вторых, вы все равно не сделаете здесь более эффективно, чем чисто бинарные форматы.
Так есть ли смысл ставить под удар «юзабельность», ради выигрыша нескольких байт?
3. Необходимость экранирования переноса строки в сырых данных.
Расходы на экранирование будут возрастать пропорционально объему этих данных. То же самое при извлечении этих данных. Здесь, кстати, есть и другая проблема: придется перевыделять память каждый раз, как мы дойдем до предела буффера, потому, что не известно сколько нужно еще считать
Решить это можно, например, введя спецификатор размера значения.
Как же тяжело разговаривать с людьми, для которых все шурупы — гвозди :-)
В Tree нет ключей. Всё, что есть в Tree — узлы. Каждый узел имеет некоторый тип, выраженный именем. Узлы с пустым именем типа могут содержать некоторый поток байт данных. Постарайтесь понять эту простую модель, а не смотреть на неё через призму json модели данных.
Символ равенства — это не разделитель ключа и значения. Помидитируйте над следующим кодом:
В Tree нет ключей. Всё, что есть в Tree — узлы. Каждый узел имеет некоторый тип, выраженный именем. Узлы с пустым именем типа могут содержать некоторый поток байт данных. Постарайтесь понять эту простую модель, а не смотреть на неё через призму json модели данных.
Символ равенства — это не разделитель ключа и значения. Помидитируйте над следующим кодом:
>В Tree нет ключей
Вы прекрасно поняли что я имел ввиду имена узлов.
Я отлично понимаю что представляет из себя то, что вы показываете и ни через какую призму не смотрю.
Почему вы, вместо того, чтобы обратить внимание на то, что вам говорят, думаете, что вас не понимают и пытаетесь объяснить мне древовидную структуру мне не ясно.
Вы прекрасно поняли что я имел ввиду имена узлов.
Я отлично понимаю что представляет из себя то, что вы показываете и ни через какую призму не смотрю.
Почему вы, вместо того, чтобы обратить внимание на то, что вам говорят, думаете, что вас не понимают и пытаетесь объяснить мне древовидную структуру мне не ясно.
Я прекрасно понял, что имели ввиду вы именно то, что сказали — ключи. Которые в общем случае могут иметь произвольные данные. И именно поэтому у вас возникли претензии к узлам-именам, так как они в общем случае не годятся в качестве ключей. Хотя ограниченно их в качестве ключей использовать можно. Например, когда известно, что ключи не могут содержать пробел, таб, перевод строки и символ равенства.
Вы упорно продолжаете. Не нужно мне навязывать ваше понимание того, что я сказал,
так же как и не нужно мне навязывать какие символы я могу использовать, а какие нет.
так же как и не нужно мне навязывать какие символы я могу использовать, а какие нет.
Как можно записать такой объект в tree?
{
"website parser logic": {
"priority": 2,
"subitems": [14, 15, 16, 0]
}
}
Представление json модели данных в tree формате может выглядеть, например, так: json, json.tree, реализация.
Конкретно ваш пример, при требовании совместимости с json, выглядел бы так:

Но, куда лучше, конечно, что-то типа этого:

Правда в json это уже автоматом не преобразовать
Но, куда лучше, конечно, что-то типа этого:
Правда в json это уже автоматом не преобразовать
Кстати, к разговору о читаемости. Как бишь, в вашем формате будет выглядеть строковое значение, заканчивающееся одним символом перевода строки?

Вы правда думаете, что это интуитивно читаемая запись? Ладно, это еще мелочи.
А как в вашем формате записать коллекцию значений (не вообще узлов, а только значений)?
А как в вашем формате записать коллекцию значений (не вообще узлов, а только значений)?
\n конечно куда интуитивней, да. Часто вам приходится, например, в конфигах использовать одиночные переводы строк в качестве значений?
Это и есть коллекция из двух пустых значений
Это и есть коллекция из двух пустых значений
\n конечно куда интуитивней
Его видно, и он находится в ожидаемом месте.
Часто вам приходится, например, в конфигах использовать одиночные переводы строк в качестве значений?
Мне приходится использовать значения, которые заканчиваются переводом строки (и именно так я и сформулировал задачу).
Это и есть коллекция из двух пустых значений
Так вы определитесь — это коллекция двух пустых значений, или строковое значение, заканчивающееся одним символом перевода строки?
Я прямо даже переформулирую вопрос, для очевидности: ваш формат позволяет записывать значения, содержащие знак перевода строки? Если да, то как в вашем формате различается «abc\ndef» и [«abc»; «def»]?
Никак, при приведении списка к строке элементы списка склеиваются через перевод строки.
Значит, один из этих двух вариантов (судя по всему — коллекцию) ваш формат не поддерживает.
Поддерживает, но не различает. Различают уже языки, основанные на данном формате.
У нас с вами разное понимание слова «поддерживает». В моем понимании, когда формат поддерживает некий примитив (в нашем примере — коллекцию), его самый базовый парсер способен этот примитив прочитать и отдать.
Список узлов вполне себе поддерживает. А вот значения с переводами строк — нет. Именно поэтому, когда надо записать такое значение — оно превращается в коллекцию из значений не содержащих переводов строк.
Окей, не поддерживает значения с переводами строк. Значит, утверждение «формат Tree бинарно-безопасен» ложно — вы не можете записать в значение (как и в имя) произвольный бинарный поток.
Или-или. Вы не можете сохранить оба утверждения истинными.
Или-или. Вы не можете сохранить оба утверждения истинными.
Давайте отставим споры о том, можно ли multipart/* кодирование называть бинарно безопасным, а вернёмся к истоками.
Что такое бинарная безопасность? Как вы правильно заметили, это гарантия, что какие бы данные мы не отправили, получим мы точно такие же данные, не перепутав биты по пути.
Например, семейство text/* форматов не является бинарно безопасным, потому, что при передаче данных из системы с одним типом переводов строк в систему с другим, эти самые переводы строк могут быть преобразованы к тому виду, что приняты в целевой системе. По этой причине и есть разделение файлов на текстовые (где неизменность переводов строк не гарантирована) и бинарные (где соответственно гарантируется отсутствие подобного преобразования).
Из этих соображений INI, YAML и XML из числа бинарно безопасных выпадают сразу же, так как переводы строк в них записываются как есть. И хотя, тот же XML можно передавать как application/xml (что гарантирует бинарную безопасность при передаче по http), но в общем случае использования и передачи это гарантировать не удается, ибо XML — текстовый формат.
JSON же хоть и тоже текстовый, но изменение переводов строк в нём не приводит к печальным последствиям, потому как переводы строк в его строках запрещены — они представляются специальной эскейп-последовательностью. Более того, всего по спецификации такому экранированию должны подвергаться 36 байт из 256. Благодаря такому экранированию, JSON действительно становится бинарно безопасным и заслуживает 3 балла из 5. Так мало, потому что довольно много символов требуют специальной обработки перед сериализацией и после. В Tree же такой символ только один — перевод строки.
Что такое бинарная безопасность? Как вы правильно заметили, это гарантия, что какие бы данные мы не отправили, получим мы точно такие же данные, не перепутав биты по пути.
Например, семейство text/* форматов не является бинарно безопасным, потому, что при передаче данных из системы с одним типом переводов строк в систему с другим, эти самые переводы строк могут быть преобразованы к тому виду, что приняты в целевой системе. По этой причине и есть разделение файлов на текстовые (где неизменность переводов строк не гарантирована) и бинарные (где соответственно гарантируется отсутствие подобного преобразования).
Из этих соображений INI, YAML и XML из числа бинарно безопасных выпадают сразу же, так как переводы строк в них записываются как есть. И хотя, тот же XML можно передавать как application/xml (что гарантирует бинарную безопасность при передаче по http), но в общем случае использования и передачи это гарантировать не удается, ибо XML — текстовый формат.
JSON же хоть и тоже текстовый, но изменение переводов строк в нём не приводит к печальным последствиям, потому как переводы строк в его строках запрещены — они представляются специальной эскейп-последовательностью. Более того, всего по спецификации такому экранированию должны подвергаться 36 байт из 256. Благодаря такому экранированию, JSON действительно становится бинарно безопасным и заслуживает 3 балла из 5. Так мало, потому что довольно много символов требуют специальной обработки перед сериализацией и после. В Tree же такой символ только один — перевод строки.
Как вы правильно заметили, это гарантия, что какие бы данные мы не отправили, получим мы точно такие же данные, не перепутав биты по пути.
Нет, я этого не замечал.
Для меня бинарно-безопасный формат — это такой, в котором можно записать произвольные бинарные данные без конверсии. Вообще без. Вот в ASN.1 DER есть бинарная безопасность. А у вас — нет.
И дальше уже не важно, сколько символов надо экранировать — если нужно экранировать хотя бы один, то формат не является бинарно-безопасным.
В таком случае любой современный накопитель данных не является бинарно безопасным, ибо хранит эти самые данные не по порядку байт :-)
Ну, не любой. Но даже если вы имеете дело с таким накопителем, то над ним есть абстракция в виде контроллера, которая дает бинарно-безопасный вывод, а затем — в виде файловой системы, которая тоже дает бинарно-безопасный вывод.
Ну и самое главное, что на правдивость вашего же заявления о бинарной безопасности tree это никак не влияет.
Ну и самое главное, что на правдивость вашего же заявления о бинарной безопасности tree это никак не влияет.
Все же рискну спросить: в вашем понимании слова «поддерживает», существует ли вообще хоть один формат, который что бы то ни было не поддерживает?..
Поддерживает, но не различает. Различают уже языки, основанные на данном формате.
Стоп. А как, в таком случае, можно объявить и различить коллекцию из нескольких строк, каждая из которых может содержать символ(ы) перевода строки? Ну, скажем, вот такое:
[ "one", "two\nthree", "four\nfive\nseven" ]
Канонично так:
{ "words" : [ "one", "two\nthree", "four\nfive\nseven" ] }
word =one
word
=two
=three
word
=four
=five
=seven
Ох. Даже так. А если в коллекции несколько сотен значений? А если несколько тысяч? А если название переменной при этом что-то вроде mySuperSettingsOptionWithVeryLongVariableName?
И вы все еще оцениваете «человекочитаемость», «удобство редактирования» и «размер в сериализованном виде» в 5 баллов, против 3 баллов для JSON?
И вы все еще оцениваете «человекочитаемость», «удобство редактирования» и «размер в сериализованном виде» в 5 баллов, против 3 баллов для JSON?
Такая запись особенно удобна, если сотня-тысяча значений, когда имя массива в json уехало бы далеко за пределы экрана.
Не стоит давать узлам такие длинные имена. Безотносительно формата. Тем не менее автодополнение никто не отменял.
Да, попробуйте попользоваться таким подходом и поймёте, что он куда удобнее.
Не стоит давать узлам такие длинные имена. Безотносительно формата. Тем не менее автодополнение никто не отменял.
Да, попробуйте попользоваться таким подходом и поймёте, что он куда удобнее.
Надеюсь, что ваша поделка не получит никакого распространения. Но на всякий случай попрошу. Пишите БНФ!!! БНФ! БНФ! А то придумают очередной маркдавн с 25ю различными реализациями.
Вообще, спасибо автору за то, что инициировал интереснейшую дискуссию! Даже диагональное чтение комментов пополнило мои познания двумя любопытными очеловеченными вариантами JSON'а, а также сформировало у меня некоторое понимание того, каким действительно должен быть формат для людей.
И, кстати, сама идея древовидного формата с однотипными узлами нравится мне всё больше и больше. Причесать спецификацию (или придумать что-нибудь новое на базе этой идеи) — и можно использовать. Только, естественно, не как формат универсальный, а скорее что-нибудь нишевое для отдельных областей применения. Безо всяких речей о каких бы то ни было убийствах ;)
И, кстати, сама идея древовидного формата с однотипными узлами нравится мне всё больше и больше. Причесать спецификацию (или придумать что-нибудь новое на базе этой идеи) — и можно использовать. Только, естественно, не как формат универсальный, а скорее что-нибудь нишевое для отдельных областей применения. Безо всяких речей о каких бы то ни было убийствах ;)
Не знаю, говорили об этом здесь, или нет, но я тут обнаружил, что поточность форматом не так-то легко и просто поддерживается, как заявлено.
Представьте поток (для наглядности возьмем WebSocket, или просто TCP socket). В этом потоке мы получаем строку, заканчивающуюся как положено, символом \n:
Что означает эта строка? Что мы имеем некую переменную v1 со значением «blabla», и уже можем дальше этим пользоваться? Представим теперь, что при следующем чтении из потока нам прилетает такая строка (тоже заканчивающаяся на \n):
Очевидно, что это продолжение нашего значения v1. Не менее очевидно, что теперь мы должны склеить blabla и blibli, вставив между ними перевод строки, и здесь выясняется, что наше v1 теперь на самом деле должно иметь значение «blabla\nblibli». То есть, читая построчно поток, для каждой прочтенной строки мы должны забегать немного вперед, чтобы знать, есть ли там еще одна строка (или там конец файла), и является ли следующая строка продолжением предыдущего значения, или она объявляет новое значение.
Если представить какой-то web-socket, по которому в формате tree раз в минуту будет приходить некое текущее значение некоей переменной, то это значение мы (без костылей) не сможем использовать аж до следующей посылки через минуту, так как мы не имеем возможности знать наверняка, дошло значение целиком, или оно было многострочным и где-то в сети застрял еще один кусок, который нужно подождать.
Представьте поток (для наглядности возьмем WebSocket, или просто TCP socket). В этом потоке мы получаем строку, заканчивающуюся как положено, символом \n:
v1 =blabla
Что означает эта строка? Что мы имеем некую переменную v1 со значением «blabla», и уже можем дальше этим пользоваться? Представим теперь, что при следующем чтении из потока нам прилетает такая строка (тоже заканчивающаяся на \n):
=blibli
Очевидно, что это продолжение нашего значения v1. Не менее очевидно, что теперь мы должны склеить blabla и blibli, вставив между ними перевод строки, и здесь выясняется, что наше v1 теперь на самом деле должно иметь значение «blabla\nblibli». То есть, читая построчно поток, для каждой прочтенной строки мы должны забегать немного вперед, чтобы знать, есть ли там еще одна строка (или там конец файла), и является ли следующая строка продолжением предыдущего значения, или она объявляет новое значение.
Если представить какой-то web-socket, по которому в формате tree раз в минуту будет приходить некое текущее значение некоей переменной, то это значение мы (без костылей) не сможем использовать аж до следующей посылки через минуту, так как мы не имеем возможности знать наверняка, дошло значение целиком, или оно было многострочным и где-то в сети застрял еще один кусок, который нужно подождать.
Поток сообщений от сервера в чате
Специальный разделитель "---" говорит клиенту о том, что завершилась пересылка очередной порции данных.
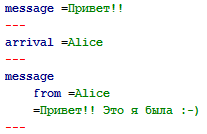
Еще одно расширение формата, которое надо обрабатывать на прикладном уровне? Мне все больше нравится мой AnyData…
Ну то есть с XML так поступать нельзя, потому что он сразу становится не XML и не каждый инструмент его потом поймет. А с Tree можно.
Именно так, этот кусок лога вы можете распарсить любым tree-парсером.
«Любой» tree-парсер не сможет читать в поточном режиме.
Ну ок, распарсить вроде бы могу. Но только специализированный парсер получит в результате одни данные, а любой другой — другие. Во втором случае данные будут «пестреть» элементами "---" после каждого сообщения, в то время как специализированный парсер их будет просто выбрасывать из полученной модели данных. Даже не знаю, что лучше выбрать: невозможность распарсить xml без закрывающего финального тега некоторыми исключительно строгими парсерами, или захламленность модели данных произвольными управляющими конструкциями в результате парсинга любым парсером, кроме специализированного.
Никакой парсер не будет их выбрасывать. Просто игнорируйте их.
В таком случае это еще одна заявленная «поддерживаемая форматом возможность», реализация которой на самом деле ложится на приложение.
Логика обработки данных — это всегда дело приложения.
Ну в общем-то отлично все складывается. Для использования великолепного формата Tree я сначала должен разработать какой-то диалект этого формата, который будет понимать только мое приложение, потом обучить пользователей диалекту, чтобы они нормально смогли писать конфиги, потом реализовать «логику обработки данных» этого диалекта, чтобы прочитать конфиг и понять, что там имел в виду пользователь: массив или строку или это вообще бинарные данные, а потом уже думать о логике самого приложения (если на нее все еще останется время, силы и средства). А если я соберусь передавать этот формат поточно по сети — мне нужно добавить в диалект одну специальную сущность, чтобы сообщать приложению о конце пересылки порции данных. И удостовериться, что в передающем и в получающем приложении эти сущности совпадают. Но это все фигня, мелочи и не важно, ведь главное — это таблица, в которой заявлено, что формат поддерживает все возможности «из коробки» на твердую пять, исключительно прост в реализации, универсален и пригоден для всего, а все остальные форматы по сравнению с ним — просто сосунки.
Подумайте, пожалуйста, на тезисом, что в информационных системах существует гораздо больше типов данных, чем те 6, которые есть в JSON. И логика двунаправленного отображения на/из JSON находится либо в приложении, либо в используемом им фреймворке. И нет практически никакой разницы отображать ли бесчисленное множество типов на 6 типов или на 1.
иногда различение типов может быть полезным, например, когда нужен какой-нибудь универсальный union сервис. Пока пришел к выводу, что нужно различать:
упорядоченность:
в json:
массив, пара ключ:значение
объект
в xml:
элементы(приблизительно)
атрибуты
множественность: один дочерний узел или несколько:
в json:
массив, объект
одно значение, соответствующее ключу в объекте
в xml:
множества элементов и атрибутов
одно значение атрибутаТипы, используемые в информационных системах, обычно комплексные. Поэтому то, сколько элементарных типов поддерживает формат, важно.
почему-то нигде не было упомянуто главное(и возможно единственное) преимущество этого формата: удобство работы с вложенными форматами:
Можно, например, задать области действия форматов, и не зависеть от контекста. Для вышестоящего формата вложенный в него — всего лишь данные, то есть при разборе его можно пропустить или отдать другому парсеру. Отсюда же и особенности экранирования: оно есть, но на весь нижележащий формат, а не на отдельные символы. Мне кажется, это настолько важная особенность, что стоит это отразить в названии, что то вроде multi format tree.
html
head
title :(тут мы уже имеем дело с новым форматом, строкой)
script
:var x
: object
: :id :123
: :url
: : schema :http
: : login :user
: : password :pass
: : host :localhost
: : port :80
: : path
: : :recent
: : :today
: : file
: : name :tree
: : extension :php
: : parameters
: : sort
: : date ascending
: : name ascending
: : top 10
: :array name =arr1 value
: : :first
: : :second
body
Можно, например, задать области действия форматов, и не зависеть от контекста. Для вышестоящего формата вложенный в него — всего лишь данные, то есть при разборе его можно пропустить или отдать другому парсеру. Отсюда же и особенности экранирования: оно есть, но на весь нижележащий формат, а не на отдельные символы. Мне кажется, это настолько важная особенность, что стоит это отразить в названии, что то вроде multi format tree.
двоеточия вместо равно
Всё ж, на мой взгляд, лучше если вложенные языки будут представленны в том же дереве:

Это даёт больше гибкости к обработке оного.
Но для non-tree языков это действительно годится — не приходится дополнительно экранировать символы вложенного языка.
Это даёт больше гибкости к обработке оного.
Но для non-tree языков это действительно годится — не приходится дополнительно экранировать символы вложенного языка.
<script>alert("foo < bar")</script>
Но для non-tree языков это действительно годится — не приходится дополнительно экранировать символы вложенного языка.
Неправда, теперь вам придется экранировать символы уже обоих языков. Без экранирования можно обойтись только в одном случае — когда перед данными идет их длина. Но это сразу делает формат человеконередактируемым (чтобы исправить что-то в одном месте нужно внести как минимум одну правку еще в другом).
В конце статьи появился апдейт с описанием изменений в формате. Думаю это должно снизить недопонимание и неприятие сего "странного синтаксиса". Реализации я уже обновил.
… а напомните, пожалуйста, что такое семантическое дерево?
Потому, что концепция JSON ущербна и требует постоянных костылей.
Ваш AST крайне не удобен для программного анализа — чтобы узнать тип узла, нужно проитерироваться по словарю.
В tree это будет выглядеть так:
sub
mult
get \c
sum
get \a
int \5
mult
get \k
sub
get \d
int \5А что такое ОПЗ?
Я там в статье описал все пункты по которым JSON проигрывает :-) Обработчик выражений ещё не реализован, но я работаю над этим: https://github.com/nin-jin/jack.d
Да, порядок сохраняется.
Tree — убийца JSON, XML, YAML и иже с ними