Привет, Хабр.
В предыдущей части была проанализирована посещаемость Хабра по основным параметрам — количеству статей, их просмотрам и рейтингам. Однако вопрос популярности разделов сайта остался не рассмотренным. Стало интересно рассмотреть это более подробно, и найти самые популярные и самые непопулярные хабы. Наконец, я рассмотрю «geektimes-эффект» более подробно, и в завершении читатели получат новую подборку лучших статей по новым рейтингам.
Кому интересно что получилось, продолжение под катом.
Еще раз напомню, что статистика и рейтинг не являются официальными, никакой инсайдерской информации у меня нет. Также не гарантируется, что я где-то не ошибся или что-то не пропустил. Но все же, думаю, получилось интересно. Мы приступим сначала к коду, кому это неактуально, первые разделы могут пропустить.
В первой версии парсера учитывались лишь число просмотров, комментариев и рейтинг статей. Это уже неплохо, но не позволяет делать более сложные запросы. Пора проанализировать тематические разделы сайта, это позволит делать достаточно интересные исследования, например, посмотреть как менялась популярность раздела «С++» за несколько лет.
Парсер статей был улучшен, теперь он возвращает хабы, к которым относится статья, а также ник автора и его рейтинг (тут тоже можно сделать много интересного, но это потом). Данные сохранены в csv-файле примерно такого вида:
Получим список основных тематических хабов сайта.
Функция find_between и класс Str выделяют строку между двух тегов, я использовал их ранее. Тематические хабы отмечены "*", так что их легко выделить, можно также раскомментировать соответствующие строки, чтобы получить разделы других категорий.
На выходе функции get_hubs получаем достаточно внушительный список, который сохраняем как dictionary. Специально привожу список целиком, чтобы можно было оценить его объем.
Для сравнения, разделы geektimes выглядят скромнее:
Аналогично были сохранены остальные хабы. Теперь несложно написать функцию, которая возвращает результат, относится статья к geektimes или к профильному хабу.
Аналогичные функции были сделаны для других разделов («разработка», «администрирование» и пр).
Пора приступать к анализу. Загружаем датасет и обрабатываем данные хабов.
Теперь мы можем сгруппировать данные по дням и вывести число публикаций по разным хабам.
Выводим количество опубликованных статей с помощью Matplotlib:

Я разделил в графике статьи «geektimes» и «geektimes only», т.к. статья может принадлежать к обеим разделам одновременно (например «DIY» + «микроконтроллеры» + «С++»). Обозначением «profile» я выделил профильные статьи сайта, хотя возможно, английский термин profile для этого не совсем верный.
В предыдущей части спрашивали про «geektimes-эффект», связанный с изменением правил оплаты статей для geektimes с этого лета. Выведем отдельно статьи geektimes:
Результат интересный. Примерное соотношение просмотров статей geektimes к общему где-то 1:5. Но если общее число просмотров заметно колебалось, то просмотр «развлекательных» статей держался примерно на одном уровне.
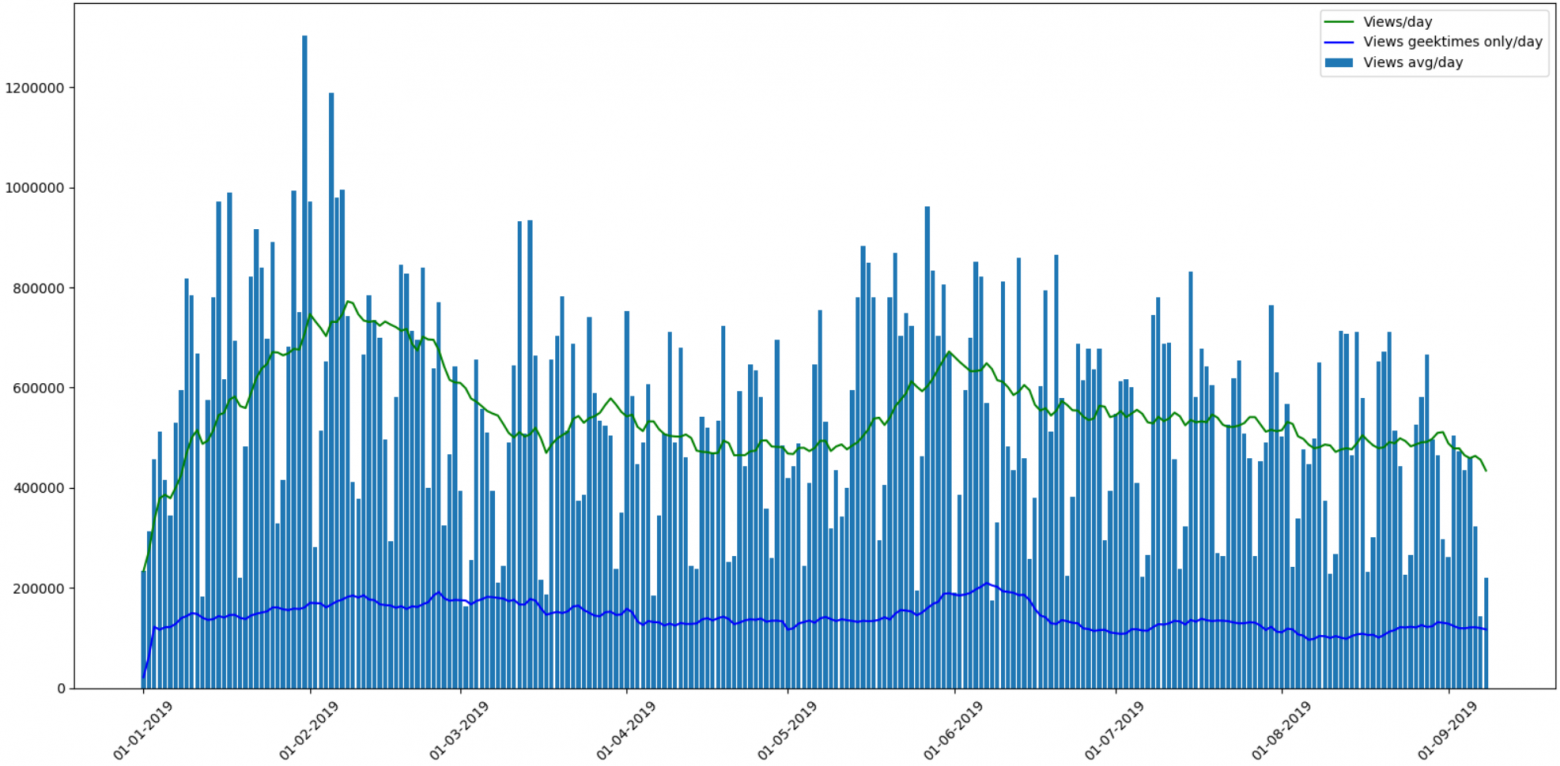
Также можно заметить, что общее число просмотров статей раздела «geektimes» после изменения правил все же упало, но «на глаз», не больше чем на 5% от общих значений.
Интересно посмотреть среднее число просмотров на статью:
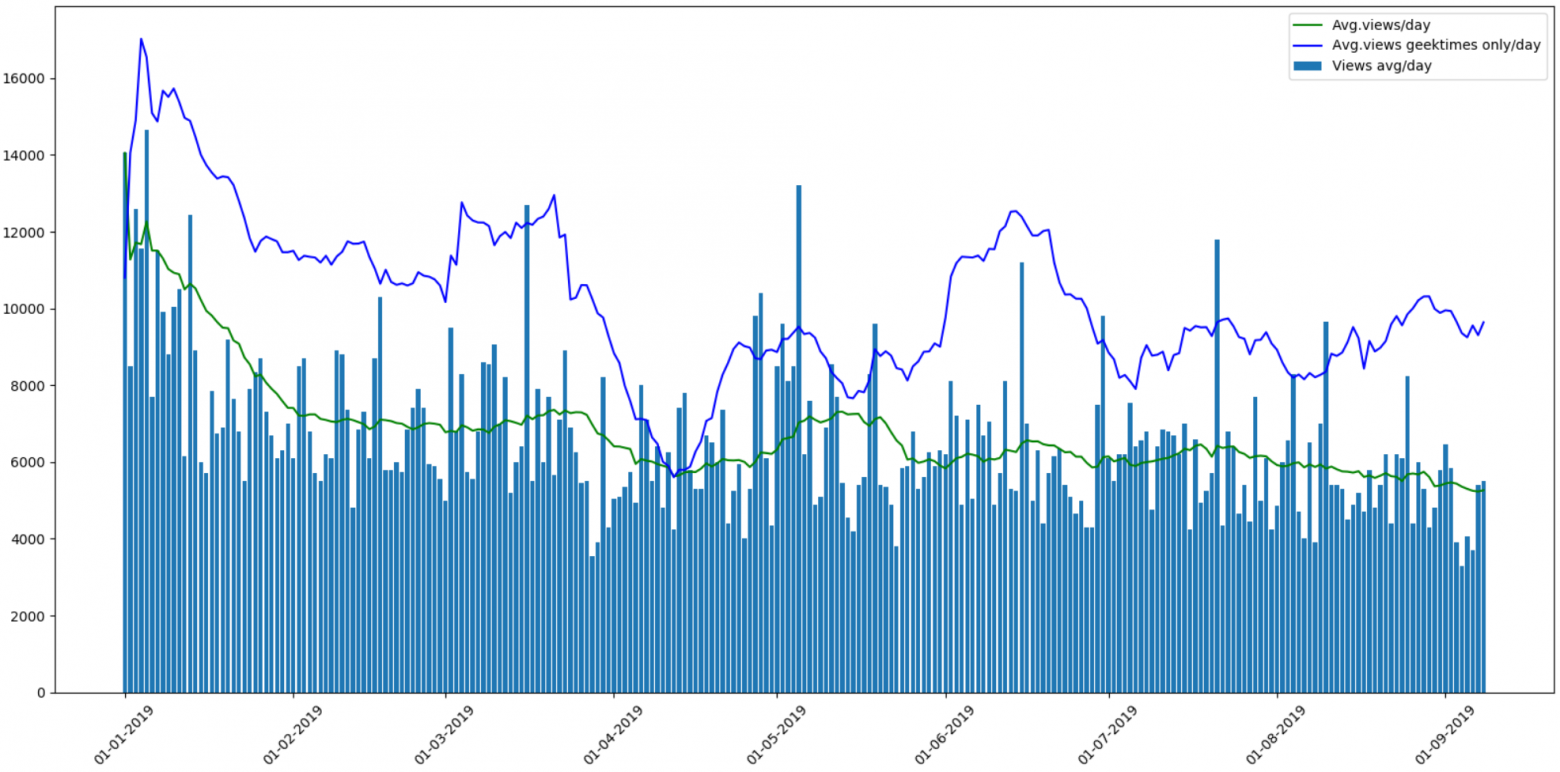
Для «развлекательных» статей оно примерно на 40% выше среднего. Наверно это неудивительно. Провал в начале апреля мне непонятен, может так и было, или это какая-то ошибка парсинга, а может кто-то из авторов geektimes ушел в отпуск ;).
Кстати, на графике видны еще два заметных пика числа просмотров статей — новогодние и майские праздники.
Перейдем к обещанному анализу хабов. Выведем топ 20 хабов по числу просмотров:
Результат:
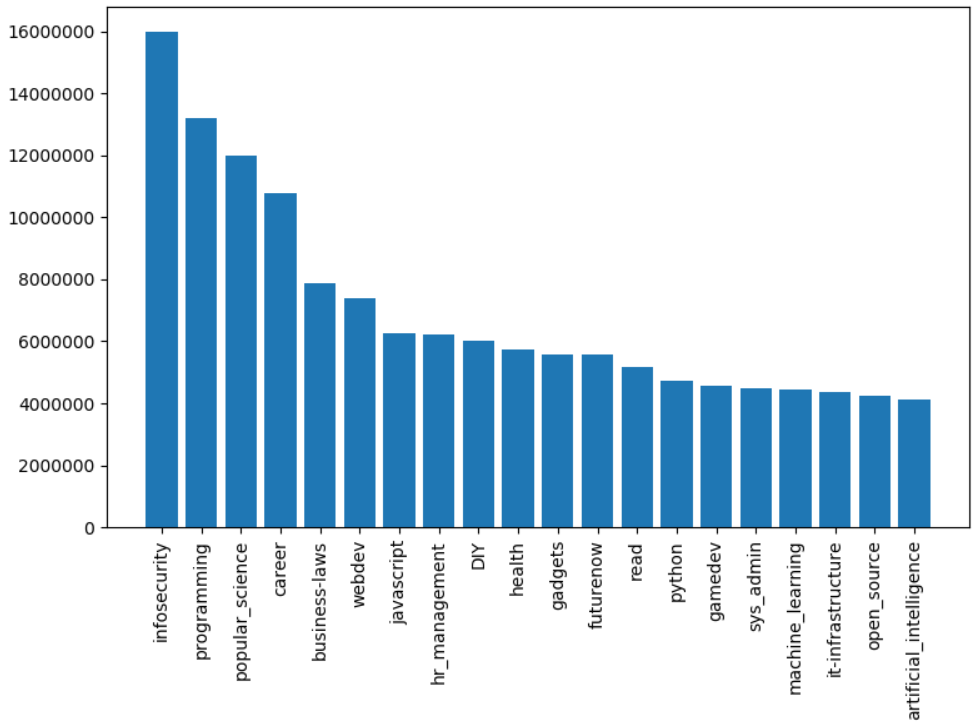
На удивление, самым популярным по просмотрам оказался хаб «Информационная безопасность», также в топ-5 лидеров входят «Программирование» и «Popular science».
Антитоп занимает Gtk и Cocoa.

Скажу по секрету, топ хабов также можно увидеть и здесь, хотя число просмотров там не показано.
И наконец, обещанный рейтинг. Используя данные анализа хабов, мы можем вывести самые популярные статьи по самым популярным хабам за этот 2019 год.
Информационная безопасность
Программирование
Научно-популярное
Карьера
Законодательство в IT
Веб-девелопмент
GTK
И наконец, чтобы никому не было обидно, приведу рейтинг самого малопосещаемого хаба «gtk». В нем за год была опубликована одна статья, она же «автоматом» занимает первую строчку рейтинга.
Заключения не будет. Всем приятного чтения.
В предыдущей части была проанализирована посещаемость Хабра по основным параметрам — количеству статей, их просмотрам и рейтингам. Однако вопрос популярности разделов сайта остался не рассмотренным. Стало интересно рассмотреть это более подробно, и найти самые популярные и самые непопулярные хабы. Наконец, я рассмотрю «geektimes-эффект» более подробно, и в завершении читатели получат новую подборку лучших статей по новым рейтингам.
Кому интересно что получилось, продолжение под катом.
Еще раз напомню, что статистика и рейтинг не являются официальными, никакой инсайдерской информации у меня нет. Также не гарантируется, что я где-то не ошибся или что-то не пропустил. Но все же, думаю, получилось интересно. Мы приступим сначала к коду, кому это неактуально, первые разделы могут пропустить.
Сбор данных
В первой версии парсера учитывались лишь число просмотров, комментариев и рейтинг статей. Это уже неплохо, но не позволяет делать более сложные запросы. Пора проанализировать тематические разделы сайта, это позволит делать достаточно интересные исследования, например, посмотреть как менялась популярность раздела «С++» за несколько лет.
Парсер статей был улучшен, теперь он возвращает хабы, к которым относится статья, а также ник автора и его рейтинг (тут тоже можно сделать много интересного, но это потом). Данные сохранены в csv-файле примерно такого вида:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/,"Мессенджер Slack — причины выбора, косяки при внедрении и особенности сервиса, облегчающие жизнь",votes:7,votesplus:8,votesmin:1,bookmarks:32,
views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft
...
Получим список основных тематических хабов сайта.
def get_as_str(link: str) -> Str:
try:
r = requests.get(link)
return Str(r.text)
except Exception as e:
return Str("")
def get_hubs():
hubs = []
for p in range(1, 12):
page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
# page_html = get_as_str("https://habr.com/ru/hubs/geektimes/page%d/" % p) # Geektimes
# page_html = get_as_str("https://habr.com/ru/hubs/develop/page%d/" % p) # Develop
# page_html = get_as_str("https://habr.com/ru/hubs/admin/page%d" % p) # Admin
for hub in page_html.split("media-obj media-obj_hub"):
info = Str(hub).find_between('"https://habr.com/ru/hub', 'list-snippet__tags')
if "*</span>" in info:
hub_name = info.find_between('/', '/"')
if len(hub_name) > 0 and len(hub_name) < 32:
hubs.append(hub_name)
print(hubs)Функция find_between и класс Str выделяют строку между двух тегов, я использовал их ранее. Тематические хабы отмечены "*", так что их легко выделить, можно также раскомментировать соответствующие строки, чтобы получить разделы других категорий.
На выходе функции get_hubs получаем достаточно внушительный список, который сохраняем как dictionary. Специально привожу список целиком, чтобы можно было оценить его объем.
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
Для сравнения, разделы geektimes выглядят скромнее:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
Аналогично были сохранены остальные хабы. Теперь несложно написать функцию, которая возвращает результат, относится статья к geektimes или к профильному хабу.
def is_geektimes(hubs: List) -> bool:
return len(set(hubs) & hubs_gt) > 0
def is_geektimes_only(hubs: List) -> bool:
return is_geektimes(hubs) is True and is_profile(hubs) is False
def is_profile(hubs: List) -> bool:
return len(set(hubs) & hubs_profile) > 0
Аналогичные функции были сделаны для других разделов («разработка», «администрирование» и пр).
Обработка
Пора приступать к анализу. Загружаем датасет и обрабатываем данные хабов.
def to_list(s: str) -> List[str]:
# "user:popular_science+astronomy" => [popular_science, astronomy]
return s.split(':')[1].split('+')
def to_date(dt: datetime) -> datetime.date:
return dt.date()
df = pd.read_csv("habr_2019.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#')
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ')
dates += datetime.timedelta(hours=3)
df['date'] = dates.map(to_date, na_action=None)
hubs = df["hubs"].map(to_list, na_action=None)
df['hubs'] = hubs
df['is_profile'] = hubs.map(is_profile, na_action=None)
df['is_geektimes'] = hubs.map(is_geektimes, na_action=None)
df['is_geektimes_only'] = hubs.map(is_geektimes_only, na_action=None)
df['is_admin'] = hubs.map(is_admin, na_action=None)
df['is_develop'] = hubs.map(is_develop, na_action=None)
Теперь мы можем сгруппировать данные по дням и вывести число публикаций по разным хабам.
g = df.groupby(['date'])
days_count = g.size().reset_index(name='counts')
year_days = days_count['date'].values
grouped = g.sum().reset_index()
profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean()
geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean()
geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean()
admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean()
develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
Выводим количество опубликованных статей с помощью Matplotlib:
Я разделил в графике статьи «geektimes» и «geektimes only», т.к. статья может принадлежать к обеим разделам одновременно (например «DIY» + «микроконтроллеры» + «С++»). Обозначением «profile» я выделил профильные статьи сайта, хотя возможно, английский термин profile для этого не совсем верный.
В предыдущей части спрашивали про «geektimes-эффект», связанный с изменением правил оплаты статей для geektimes с этого лета. Выведем отдельно статьи geektimes:
df_gt = df[(df['is_geektimes_only'] == True)]
group_gt = df_gt.groupby(['date'])
days_count_gt = group_gt.size().reset_index(name='counts')
grouped = group_gt.sum().reset_index()
year_days_gt = days_count_gt['date'].values
view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
Результат интересный. Примерное соотношение просмотров статей geektimes к общему где-то 1:5. Но если общее число просмотров заметно колебалось, то просмотр «развлекательных» статей держался примерно на одном уровне.
Также можно заметить, что общее число просмотров статей раздела «geektimes» после изменения правил все же упало, но «на глаз», не больше чем на 5% от общих значений.
Интересно посмотреть среднее число просмотров на статью:
Для «развлекательных» статей оно примерно на 40% выше среднего. Наверно это неудивительно. Провал в начале апреля мне непонятен, может так и было, или это какая-то ошибка парсинга, а может кто-то из авторов geektimes ушел в отпуск ;).
Кстати, на графике видны еще два заметных пика числа просмотров статей — новогодние и майские праздники.
Хабы
Перейдем к обещанному анализу хабов. Выведем топ 20 хабов по числу просмотров:
hubs_info = []
for hub_name in hubs_all:
mask = df['hubs'].apply(lambda x: hub_name in x)
df_hub = df[mask]
count, views = df_hub.shape[0], df_hub['views'].sum()
hubs_info.append((hub_name, count, views))
# Draw hubs
hubs_top = sorted(hubs_info, key=lambda v: v[2], reverse=True)[:20]
top_views = list(map(lambda x: x[2], hubs_top))
top_names = list(map(lambda x: x[0], hubs_top))
plt.rcParams["figure.figsize"] = (8, 6)
plt.bar(range(0, len(top_views)), top_views)
plt.xticks(range(0, len(top_names)), top_names, rotation=90)
plt.ticklabel_format(style='plain', axis='y')
plt.tight_layout()
plt.show()
Результат:
На удивление, самым популярным по просмотрам оказался хаб «Информационная безопасность», также в топ-5 лидеров входят «Программирование» и «Popular science».
Антитоп занимает Gtk и Cocoa.
Скажу по секрету, топ хабов также можно увидеть и здесь, хотя число просмотров там не показано.
Рейтинг
И наконец, обещанный рейтинг. Используя данные анализа хабов, мы можем вывести самые популярные статьи по самым популярным хабам за этот 2019 год.
Информационная безопасность
- Как я год не работал в Сбербанке 304000 просмотров, 599 комментариев, рейтинг +457.0/-14.0
- Выброшенные на помойку умные лампочки — ценный источник личной информации 232000 просмотров, 147 комментариев, рейтинг +75.0/-11.0
- Мошенники и ЭЦП — всё очень плохо 176000 просмотров, 778 комментариев, рейтинг +356.0/-0.0
- Как Мегафон спалился на мобильных подписках 166000 просмотров, 676 комментариев, рейтинг +624.0/-2.0
- Взлом вк, двухфакторная аутентификация не спасет 148000 просмотров, 332 комментария, рейтинг +124.0/-17.0
- Как браузер помогает товарищу майору 132000 просмотров, 321 комментарий, рейтинг +246.0/-19.0
- Крупнейший дамп в истории: 2,7 млрд аккаунтов, из них 773 млн уникальных 123000 просмотров, 154 комментария, рейтинг +86.0/-5.0
- Дорогая, мы убиваем Интернет 121000 просмотров, 933 комментария, рейтинг +392.0/-83.0
- 'Мобильный контент' бесплатно, без смс и регистраций. Подробности мошенничества от Мегафона 114000 просмотров, 478 комментариев, рейтинг +488.0/-8.0
- Сканер портов в личном кабинете Ростелекома 111000 просмотров, 194 комментария, рейтинг +300.0/-8.0
Программирование
- Про одного парня 167000 просмотров, 249 комментариев, рейтинг +239.0/-33.0
- Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ 129000 просмотров, 1271 комментарий, рейтинг +131.0/-63.0
- Почему Senior Developer'ы не могут устроиться на работу 119000 просмотров, 901 комментарий, рейтинг +151.0/-14.0
- Старикам здесь не место? Программируем после тридцати пяти 116000 просмотров, 649 комментариев, рейтинг +222.0/-16.0
- Новые языки программирования незаметно убивают нашу связь с реальностью 106000 просмотров, 764 комментария, рейтинг +164.0/-52.0
- Чему я научился на своём горьком опыте (за 30 лет в разработке ПО) 101000 просмотров, 128 комментариев, рейтинг +178.0/-9.0
- Самые редкие и самые дорогие языки программирования 82900 просмотров, 119 комментариев, рейтинг +38.0/-10.0
- Курс лекций по JavaScript и Node.js в КПИ 80300 просмотров, 14 комментариев, рейтинг +34.0/-2.0
- ІТ термины на примере процесса выращивания картошки 78000 просмотров, 86 комментариев, рейтинг +84.0/-14.0
- 256 строчек голого C++: пишем трассировщик лучей с нуля за несколько часов 77600 просмотров, 124 комментария, рейтинг +241.0/-0.0
Научно-популярное
- Что курил конструктор: необычное огнестрельное оружие 236000 просмотров, 123 комментария, рейтинг +119.0/-9.0
- Учёные нашли самое старое живое позвоночное на Земле 234000 просмотров, 212 комментариев, рейтинг +82.0/-14.0
- Сериал 'Чернобыль': смотреть и думать 173000 просмотров, 803 комментария, рейтинг +164.0/-25.0
- 12-летний подросток провёл реакцию ядерного синтеза в домашней лаборатории 145000 просмотров, 280 комментариев, рейтинг +126.0/-29.0
- Сказ о сплаве Розе и отвалившейся КРЕНке 134000 просмотров, 244 комментария, рейтинг +217.0/-1.0
- Увеличь это! Современное увеличение разрешения 134000 просмотров, 235 комментариев, рейтинг +377.0/-1.0
- Софт для Boeing-737 Max писался аутсорсерами, зарабатывающими $9 в час 126000 просмотров, 560 комментариев, рейтинг +153.0/-6.0
- Не нервничай, не спеши, не перебивай: история одной трагедии 121000 просмотров, 384 комментария, рейтинг +242.0/-4.0
- Математики обнаружили идеальный способ перемножения чисел 108000 просмотров, 222 комментария, рейтинг +173.0/-10.0
- Новые языки программирования незаметно убивают нашу связь с реальностью 106000 просмотров, 764 комментария, рейтинг +164.0/-52.0
Карьера
- Как я год не работал в Сбербанке 304000 просмотров, 599 комментариев, рейтинг +457.0/-14.0
- I ruin developers' lives with my code reviews and I'm sorry 187000 просмотров, 21 комментарий, рейтинг +37.0/-3.0
- Король разработки 179000 просмотров, 668 комментариев, рейтинг +315.0/-60.0
- Про одного парня 167000 просмотров, 249 комментариев, рейтинг +239.0/-33.0
- На пенсию в 22 158000 просмотров, 927 комментариев, рейтинг +259.0/-100.0
- Как заменить лампочку на рабочем месте так, чтобы тебя не уволили? 139000 просмотров, 762 комментария, рейтинг +200.0/-20.0
- Инновации по-русски 128000 просмотров, 612 комментариев, рейтинг +480.0/-33.0
- Почему Senior Developer'ы не могут устроиться на работу 119000 просмотров, 901 комментарий, рейтинг +151.0/-14.0
- 'Сгоревшие' сотрудники: есть ли выход? 117000 просмотров, 398 комментариев, рейтинг +210.0/-14.0
- Старикам здесь не место? Программируем после тридцати пяти 116000 просмотров, 649 комментариев, рейтинг +222.0/-16.0
Законодательство в IT
- Мошенники и ЭЦП — всё очень плохо 176000 просмотров, 778 комментариев, рейтинг +356.0/-0.0
- Как Мегафон спалился на мобильных подписках 166000 просмотров, 676 комментариев, рейтинг +624.0/-2.0
- Инновации по-русски 128000 просмотров, 612 комментариев, рейтинг +480.0/-33.0
- 'Мобильный контент' бесплатно, без смс и регистраций. Подробности мошенничества от Мегафона 114000 просмотров, 478 комментариев, рейтинг +488.0/-8.0
- Как власти Казахстана пытаются прикрыть свой провал с внедрением сертификата 111000 просмотров, 77 комментариев, рейтинг +122.0/-14.0
- Как Protonmail блокируется в России 102000 просмотров, 398 комментариев, рейтинг +418.0/-7.0
- Закон об изоляции Рунета принят Госдумой в трех чтениях 88200 просмотров, 878 комментариев, рейтинг +73.0/-18.0
- Как программист банк выбирал и договора читал 87200 просмотров, 611 комментариев, рейтинг +166.0/-9.0
- Минкомсвязи одобрило законопроект об изоляции рунета 83600 просмотров, 364 комментария, рейтинг +79.0/-9.0
- Развёрнутый ответ на комментарий, а также немного о жизни провайдеров в РФ 74700 просмотров, 389 комментариев, рейтинг +290.0/-1.0
Веб-девелопмент
- Старикам здесь не место? Программируем после тридцати пяти 116000 просмотров, 649 комментариев, рейтинг +222.0/-16.0
- Как делать сайты в 2019 году 110000 просмотров, 278 комментариев, рейтинг +233.0/-11.0
- Изучаем Docker, часть 1: основы 91300 просмотров, 24 комментария, рейтинг +52.0/-10.0
- Курс лекций по JavaScript и Node.js в КПИ 80300 просмотров, 14 комментариев, рейтинг +34.0/-2.0
- Стажёр Вася и его истории об идемпотентности API 68900 просмотров, 160 комментариев, рейтинг +216.0/-3.0
- Понимание джойнов сломано. Это точно не пересечение кругов, честно 65900 просмотров, 223 комментария, рейтинг +138.0/-41.0
- Почему не нужно тратить свое время на создание нишевых тематических сайтов 62700 просмотров, 243 комментария, рейтинг +179.0/-13.0
- Делаем современное веб-приложение с нуля 62200 просмотров, 122 комментария, рейтинг +56.0/-8.0
- Темный день для Vue.js 60800 просмотров, 133 комментария, рейтинг +77.0/-6.0
- Зачем современную веб-разработку так усложнили? Часть 1 57700 просмотров, 319 комментариев, рейтинг +101.0/-6.0
GTK
И наконец, чтобы никому не было обидно, приведу рейтинг самого малопосещаемого хаба «gtk». В нем за год была опубликована одна статья, она же «автоматом» занимает первую строчку рейтинга.
- Использование GtkApplication. Особенности отрисовки librsvg 1700 просмотров, 9 комментариев, рейтинг +9.0/-1.0
Заключение
Заключения не будет. Всем приятного чтения.
