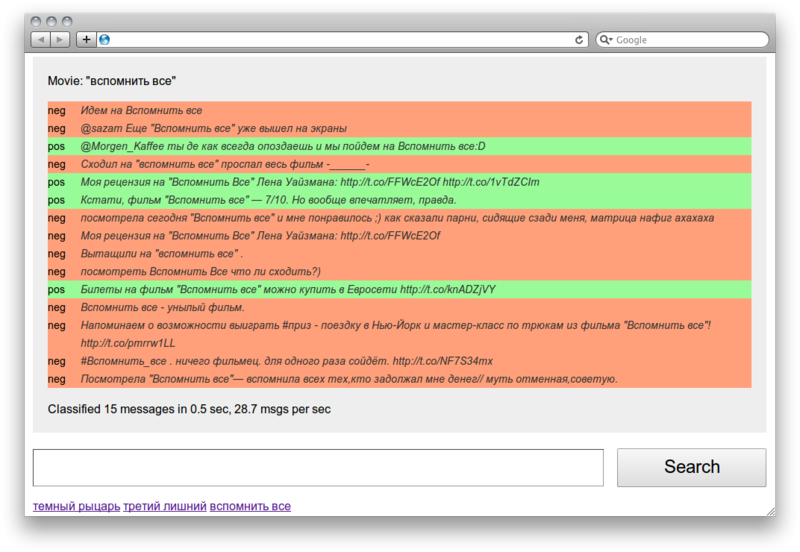
Сегодня, дорогой Хабр, я расскажу тебе историю о комбинаторной оптимизации.
Издревле (как минимум, с начала прошлого века) математики задавались вопросом, как оптимально разместить некоторое количествопива нужных и полезных предметов в рюкзаке. Была сформулирована задача о ранце и ее подзадачи — тысячи их! — которые заинтересовали информатиков, криптографов и даже лингвистов.
От задачи о ранце отпочковалась задача об упаковке в контейнеры (Bin Packing Problem), одной из разновидностей которых является задача двумерной упаковки (2-Dimensional Bin Packing). Снова отбросив несколько вариаций, мы наконец придем к двумерной упаковке в полуограниченную полосу (2-Dimensional Strip Packing, 2DSP). Чувствуете, сколько интересного уже осталось за кадром? Но мы еще не закончили продираться сквозь классификацию. У 2DSP есть два варианта входных данных: когда набор упаковываемых объектов известен заранее (offline-проблема) и когда данные поступают порциями (online-проблема).
В этой статье рассматриваются алгоритмы решения offline-варианта 2DSP. Под катом немного матчасти и много картинок с цветными квадратиками.
Издревле (как минимум, с начала прошлого века) математики задавались вопросом, как оптимально разместить некоторое количество
От задачи о ранце отпочковалась задача об упаковке в контейнеры (Bin Packing Problem), одной из разновидностей которых является задача двумерной упаковки (2-Dimensional Bin Packing). Снова отбросив несколько вариаций, мы наконец придем к двумерной упаковке в полуограниченную полосу (2-Dimensional Strip Packing, 2DSP). Чувствуете, сколько интересного уже осталось за кадром? Но мы еще не закончили продираться сквозь классификацию. У 2DSP есть два варианта входных данных: когда набор упаковываемых объектов известен заранее (offline-проблема) и когда данные поступают порциями (online-проблема).
В этой статье рассматриваются алгоритмы решения offline-варианта 2DSP. Под катом немного матчасти и много картинок с цветными квадратиками.



 Об экспериментах с компьютерной голографией писалось неоднократно. [
Об экспериментах с компьютерной голографией писалось неоднократно. [
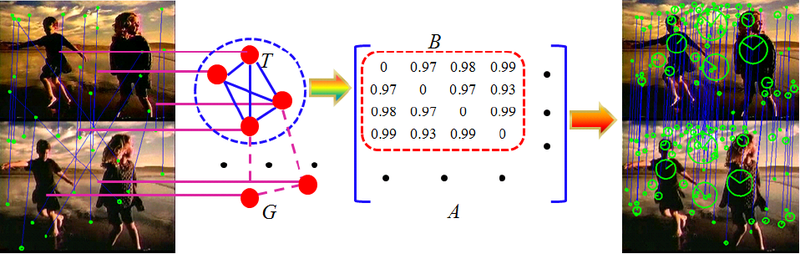
 Обнаружение пешеходов используется главным образом в исследованиях, посвященных беспилотным автомобилям. Общая цель обнаружения пешеходов — предотвращение столкновения автомобиля с человеком. На Хабре недавно был топик про «
Обнаружение пешеходов используется главным образом в исследованиях, посвященных беспилотным автомобилям. Общая цель обнаружения пешеходов — предотвращение столкновения автомобиля с человеком. На Хабре недавно был топик про «