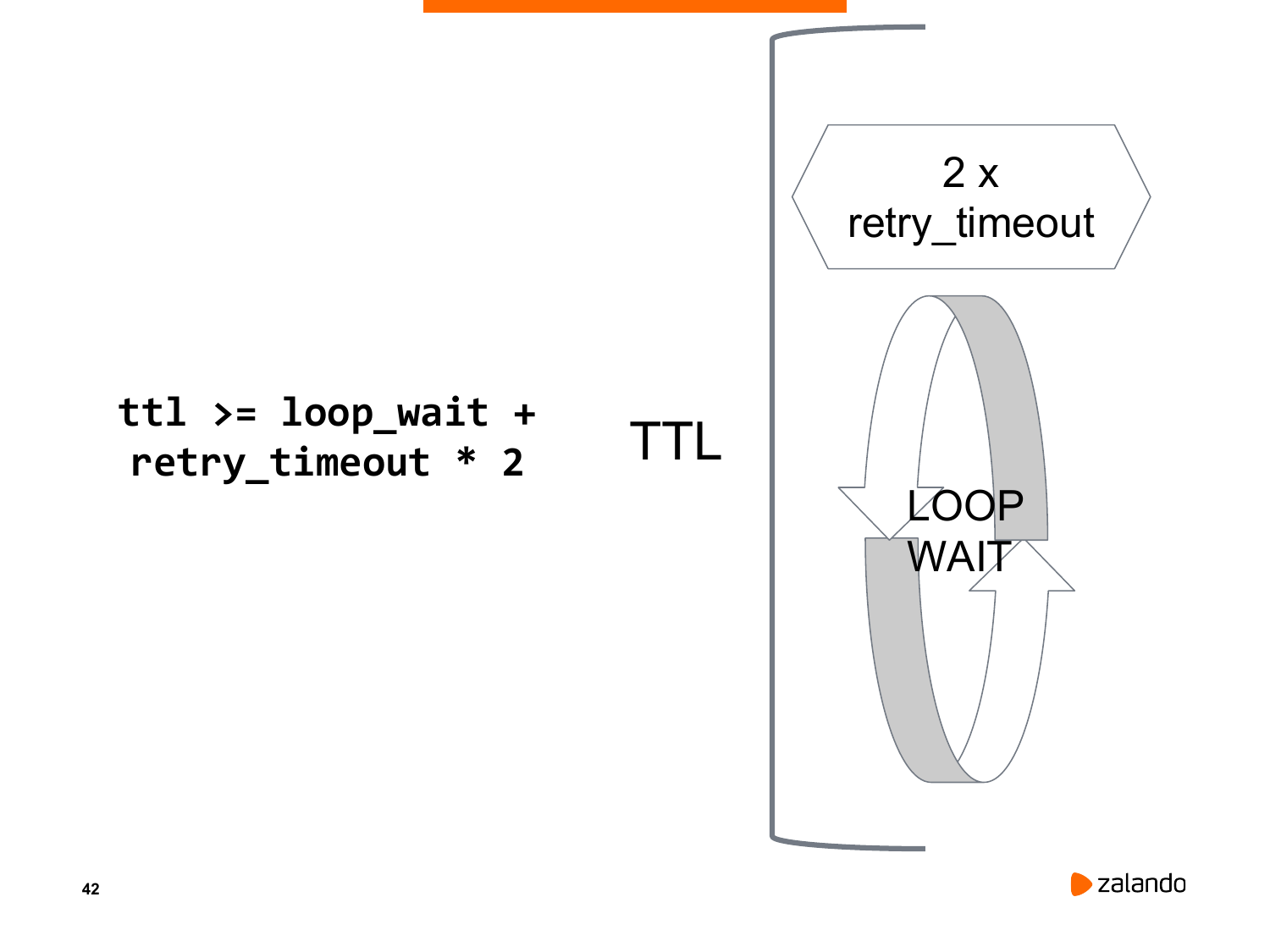
В статье «Почему всё ломается даже у хороших программистов?» (Часть 1 и Часть 2) был описан тип сотрудников: «золотая шестерёнка». Это способные люди, которые являются не только замечательными разработчиками, но ещё являются хорошими организаторами, имеют стратегическое мышление, могут проектировать архитектуру приложения либо даже ИТ-ландшафт. Встаёт закономерный вопрос, а почему «золотые шестерёнки» это плохо, почему бы из них не собрать сильную команду, чтобы всем было счастье. Давайте попробуем понять, почему «золотая шестерёнка» в итоге зачастую дестабилизирует ситуацию вокруг себя. Писать буду простым языком в расчёте на широкую аудиторию.