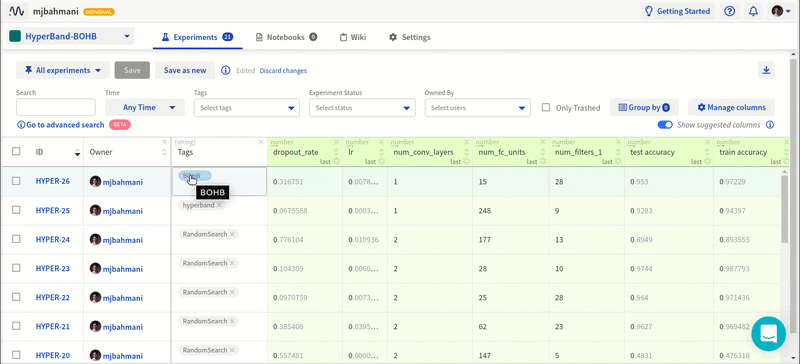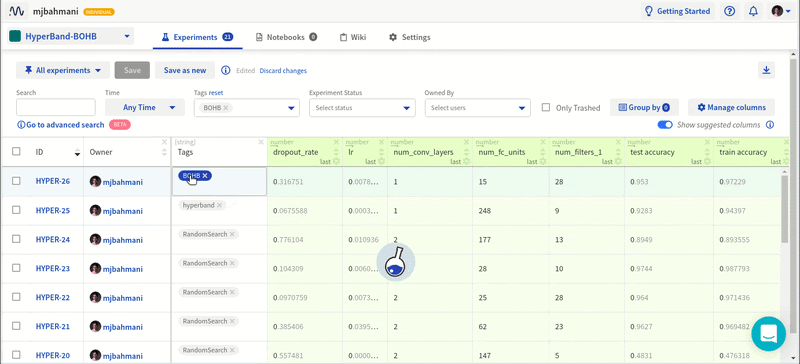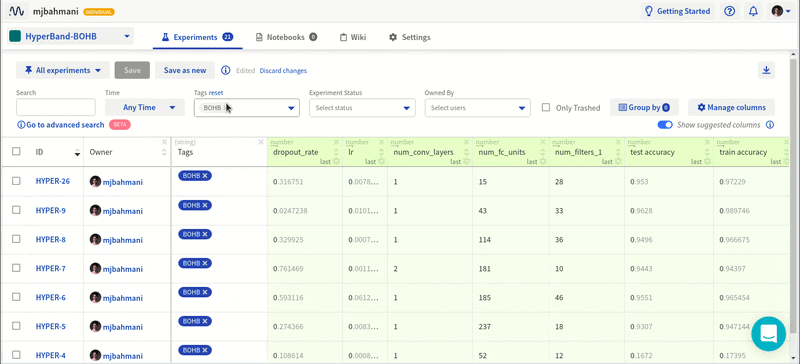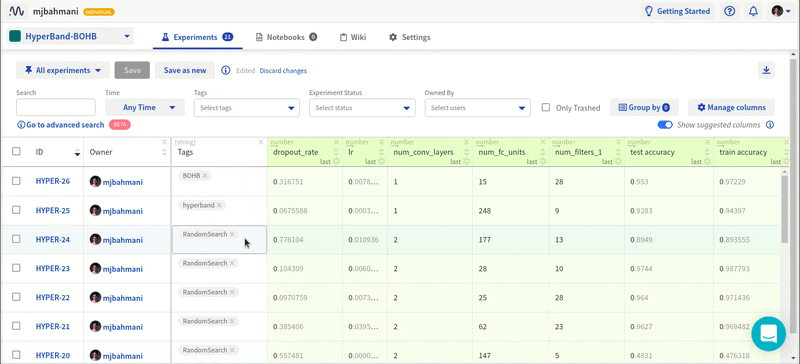
Я старый. При этом я в ладу с собой. Я не лежу ночью, беспокоясь о своей старости. Но прекрасно понимаю, что я определённо стар — по крайней мере в смысле программирования. Большинство непрограммистов посмеялись бы над мыслью о старости. Во многих сферах в середине пятого десятка лет означает, быть на вершине профессиональных навыков. Но в разработке программного обеспечения любой человек старше 40 часто рассматривается с некоторым подозрением. Люди старше 50 часто выпадают из пула резюме. Человеку за 60 хорошо иметь очень прочную стратегию выхода на пенсию. Но это статья не об определении «старости» или о предвзятости к старикам. Эта статья о том, что «более опытным» разработчикам часто труднее приспособиться к конкретной работе, задаче или среде.