
Давайте поговорим о том как нам обустроить Россию правильно нанимать людей и не задавать глупые вопросы на интервью.

Разработчик ПО/Teamlead
Давайте поговорим о том как нам обустроить Россию правильно нанимать людей и не задавать глупые вопросы на интервью.


Сразу признаюсь, что слово «хрущёвка» в этом тексте – скорее хук в заголовке. Правильнее было бы сказать, что я просто описываю свой опыт создания умного дома в обычной среднестатистической квартире городского жителя РФ, который я проживаю прямо сейчас.
Статья будет состоять из двух частей: первая – постановка задачи, ресерч, планы, выбор; вторая – реализация, опыт использования, ошибки и корректировки.
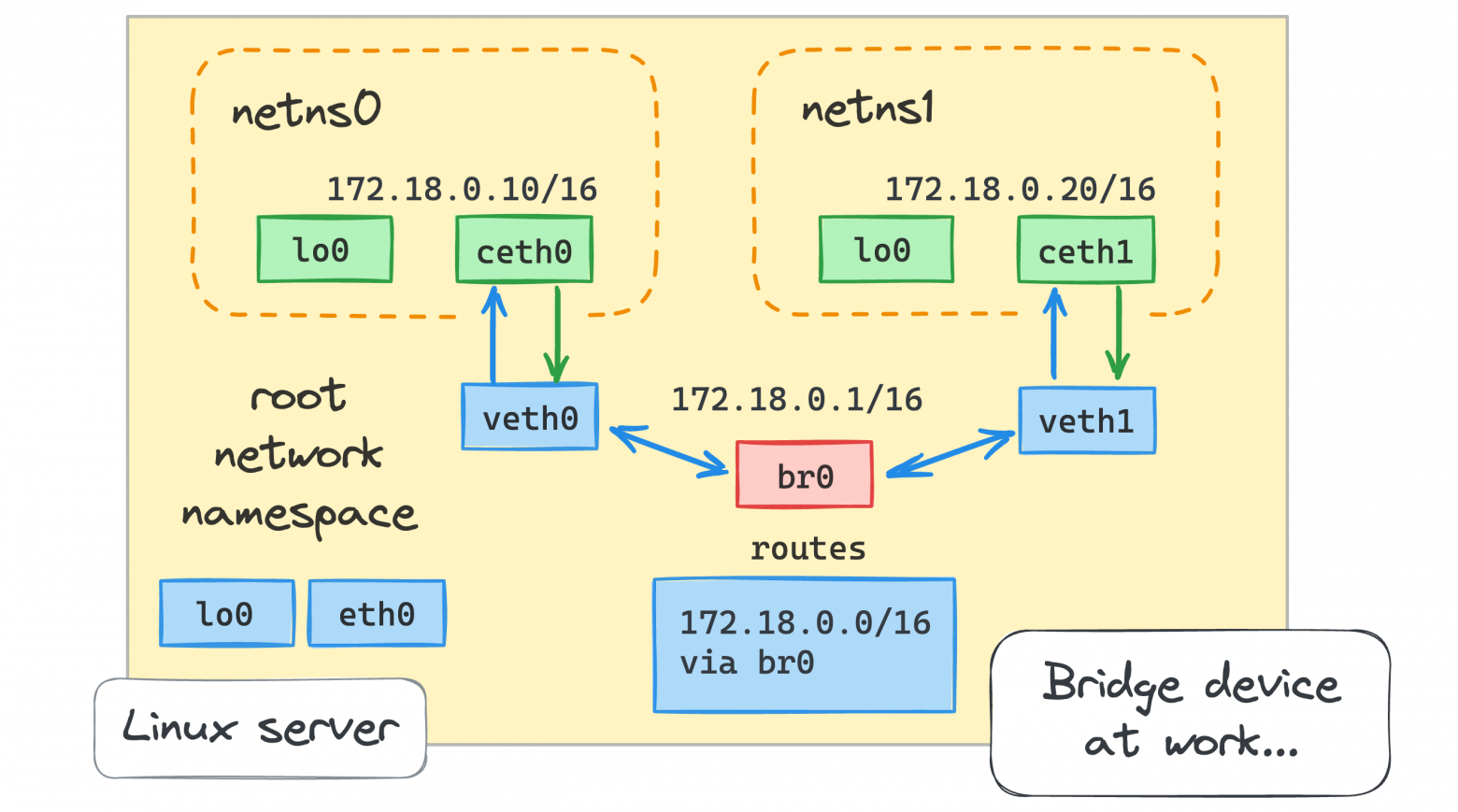
В этой статье мы собираемся разобраться со следующими вопросами:
* Как виртуализировать сетевые ресурсы, чтобы контейнеры думали, что у них есть отдельные сетевые среды?
* Как превратить контейнеры в дружелюбных соседей и научить общаться друг с другом?
* Как выйти во внешний мир (например, в Интернет) изнутри контейнера?
* Как связаться с контейнерами, работающими на хосте Linux, из внешнего мира?
* Как реализовать публикацию портов, подобную Docker?

Чтобы система долго работала без сбоев и перерывов, нужно поработать над отказоустойчивостью. В статье дадим несколько способов её построить и покажем готовое решение.

Команда Power BI рассказала, как она обеспечивает надёжную, производительную и масштабируемую работу своего сервиса. В этой статье вы узнаете, как в Power BI устроен мониторинг состояния сервиса, как SRE команды устраняют инциденты и принимают меры по улучшению сервисов.

Революция в области искусственного интеллекта переформатирует все отрасли нашей жизни, с одной стороны обещая невероятные инновации, а с другой ー сталкивая нас с новыми вызовами. В безумном потоке изменений эффективная обработка данных становится приоритетом для приложений, на основе больших языковых моделей, генеративного ИИ и семантического поиска. В основе этих технологий лежат векторные представления (embeddings, дальше будем называть их Эмбеддинги), сложные представления данных, пронизанные критической семантической информацией.
Эти вектора, созданные LLMs, охватывают множество атрибутов или характеристик, что делает управление ими сложной задачей. В области искусственного интеллекта и машинного обучения эти характеристики представляют различные измерения данных, необходимые для обнаружения закономерностей, взаимосвязей и базовых структур. Для удовлетворения уникальных требований к обработке этих вложений необходима специализированная база данных. Векторные базы данных специально созданы для обеспечения оптимизированного хранения и запросов векторов, сокращая разрыв между традиционными базами данных и самостоятельными векторными индексами, а также предоставляя ИИ-системам инструменты, необходимые для успешной работы в этой среде нагруженной данными.
 Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем.
Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем. 

Информация – одно из самых неоднозначных и неопределённых понятий в науке и философии. Для гуманитария это любые сведения, которые можно запомнить и передать в устной или письменной форме. Для математика это абстрактная сущность, сохраняющаяся при вычислительном изоморфизме. Для физика-теоретика это набор квантовых чисел, характеризующих состояние элементарной частицы. Для программиста это цифровые данные, которые можно представить в двоичном коде и измерить в битах. Для философа-материалиста это отражение многообразия окружающего мира с помощью знаков и сигналов. Для философа-идеалиста это нематериальная, неизмеримая и нелокальная сущность, что-то связанное с духом или сознанием. Для эзотериков это некая метафизическая субстанция или информационное поле. Что же такое информация на самом деле? В данной лекции я покажу, что информация – физическая, объективная, измеряемая величина, в которой нет ничего субъективного и мистического. Заодно мы разберёмся, что такое энтропия по Шеннону, насколько избыточен естественный язык, в чём заключается принцип Ландауэра и обладает ли информация массой.

Операционная система выполняет несколько процессов одновременно. ОС распределяет время работы с ресурсами компьютера между процессами. ОС даст каждому процессу шанс на выполнение, даже если число процессов больше числа процессоров.
ОС изолирует процессы друг от друга так, что ошибка в одном процессе не нарушит работу других.
ОС позволяет процессам взаимодействовать - обмениваться данными и работать совместно.
Глава 2 рассказывает, как xv6 выполняет эти требования, о процессах xv6 и как xv6 запускает первый процесс.
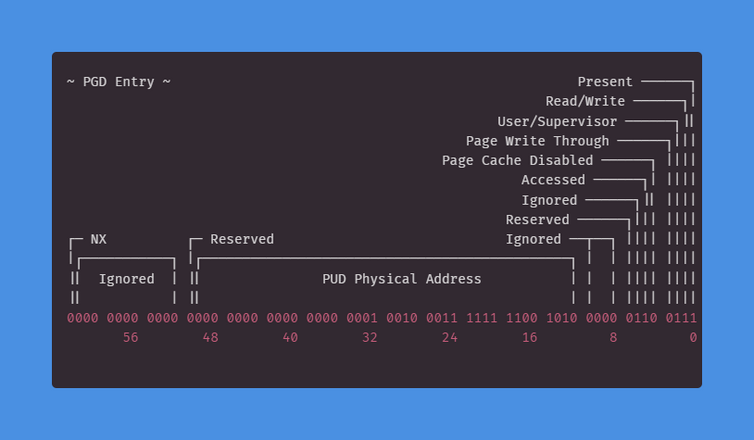
В этом посте я буду говорить о страничной организации только в контексте PML4 (Page Map Level 4), потому что на данный момент это доминирующая схема страничной организации x86_64 и, вероятно, останется таковой какое-то время.
Окружение
Это необязательно, но я рекомендую подготовить систему для отладки ядра Linux с QEMU + gdb. Если вы никогда этого не делали, то попробуйте такой репозиторий: easylkb (сам я им никогда не пользовался, но слышал о нём много хорошего), а если не хотите настраивать окружение самостоятельно, то подойдёт режим практики в любом из заданий по Kernel Security на pwn.college (вам нужно знать команды vm connect и vm debug).
Я рекомендую вам так поступить, потому что считаю, что самостоятельное выполнение команд вместе со мной и возможность просмотра страниц (page walk) на основании увиденного в gdb — хорошая проверка понимания.

Hello world!
Представляю вашему вниманию первую часть большой шпаргалки по Rust.
Другой формат, который может показаться вам более удобным.
Обратите внимание: шпаргалка рассчитана на людей, которые хорошо знают любой современный язык программирования, а не на тех, кто только начинает кодить 😉
Также настоятельно рекомендуется хотя бы по диагонали прочитать замечательный Учебник по Rust (на русском языке).
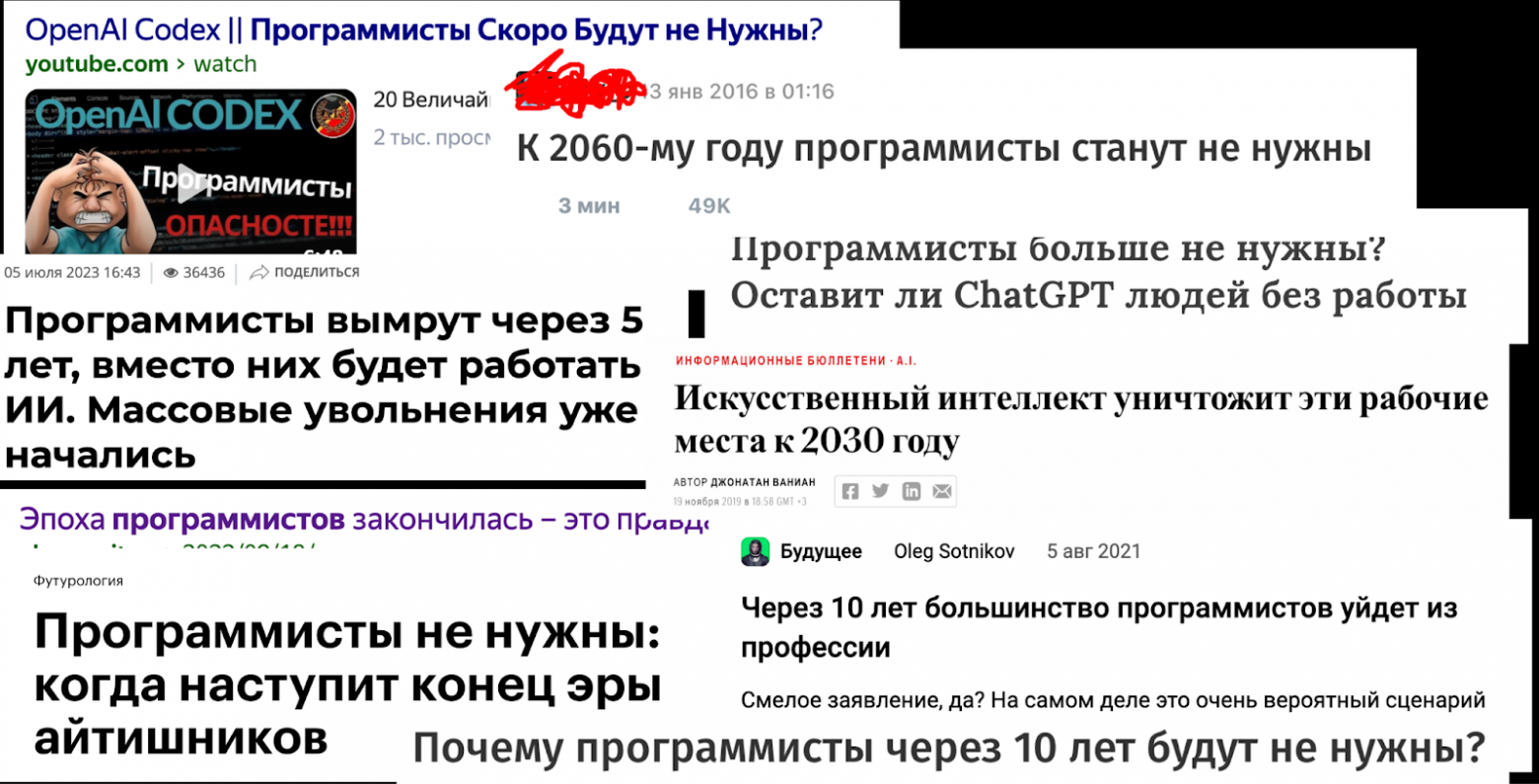
Да вымереть не могут.
Откуда это всё пошло? Чем так условные «программисты» не угодили? И почему именно программисты?
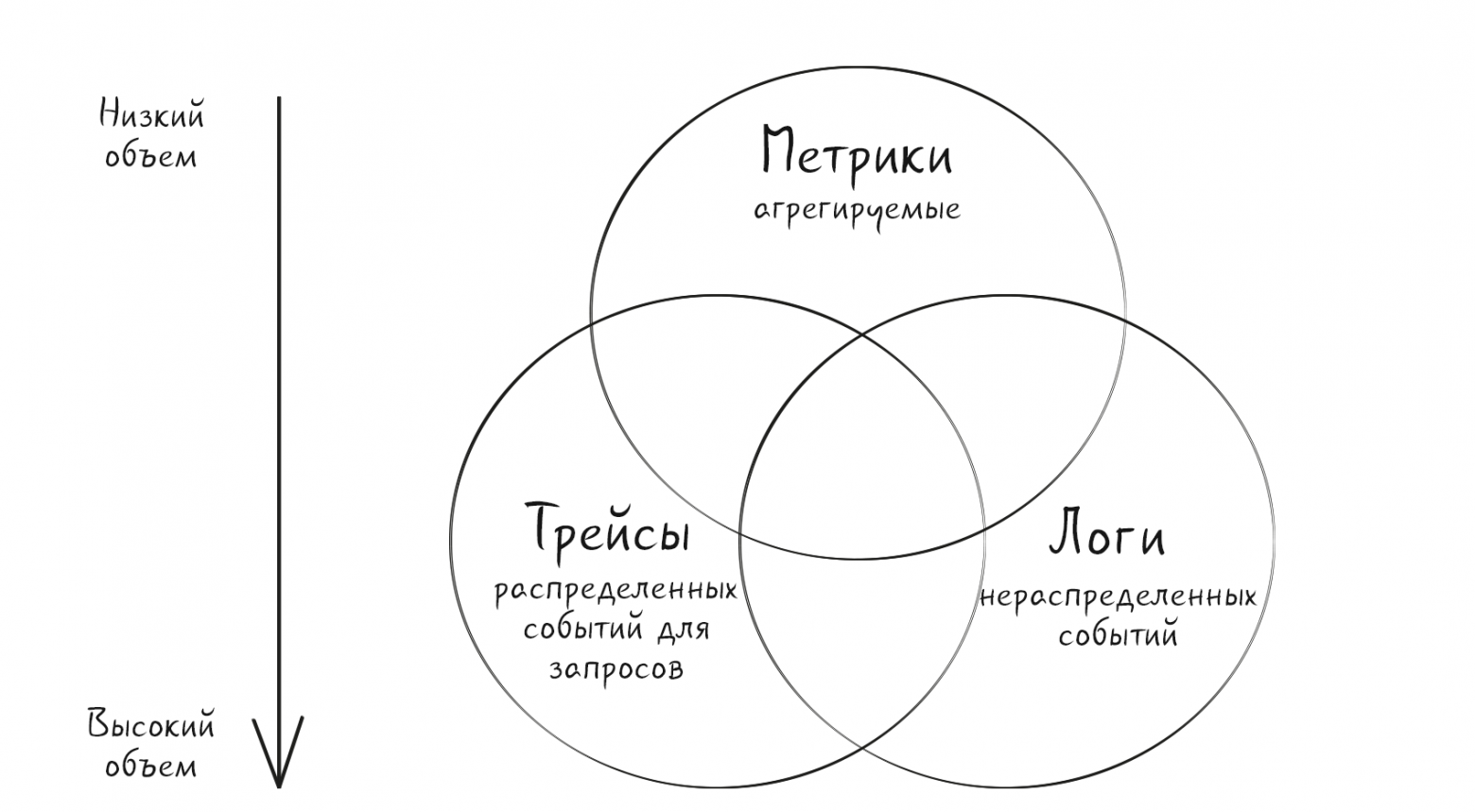
В августе 2023 года под руководством группы TAG Observability в экосистеме CNCF была выпущена версия 1.0 документа по наблюдаемости (observability). CNCF — флагман развития и продвижения облачных технологий. Организация объединяет в себе множество компаний, разработчиков и специалистов с огромным опытом и экспертизой, которые упаковали в этот документ. Наш материал является его переводом.

Днем рождения транзистора считается 23 декабря 1947 года. Тогда Уолтер Браттейн и Джон Бардин продемонстрировали первый в мире транзистор с точечным контактом. Оба физика были членами исследовательской группы Bell Labs, искавшей новое средство усиления электрических сигналов.
В первой половине XX века для решения этой задачи инженеры-электрики полагались на вакуумные лампы, но устройства были громоздкими, хрупкими и потребляли много энергии. Руководитель Бардина и Браттейна — Уильям Шокли — предположил, что можно разработать более совершенный усилитель, используя ранее не изученные электрические свойства полупроводников.
В этой статье вспомним историю транзистора и посмотрим, какие новые прорывы готовят нам производители.

Привет! Меня зовут Павел Ахметчанов, я руководитель направления улучшения процессов разработки. В статье расскажу про часто используемые методики оценок задач и есть ли в них ошибки. Посмотрим, как правильно ставить вопросы при оценке. Узнаем, что собой представляет время решения задач, а это далеко не очевидная вещь. Попробуем изменить свое мышление и получим рецепт для определения времени решения задач.
Если спросить любого начинающего исследователя этой темы «А зачем нам оценка?», он скажет, что постоянно задают вопрос «Когда вы выполните эту задачу?», на который и надо ответить с помощью этой оценки. А что, если сам вопрос задан неверно?

Всем привет меня зовут Максим, я SRE инженер в группе компаний Тинькофф.
Но сегодня я здесь по другой причине.
Я уже давно собираю и публикую подборки видео, от которых есть толк, с разных каналов SRE направленности в телеграмм канале https://t.me/sre_pub и спасибо им большое за то что позволяют мне это делать.
Но я не видел подобных подборок на хабре и для меня до сих пор загадка почему.
Лично для меня Хабр является основной площадкой для получения информации.
Вы можете это понять по 1500+ моих закладок в профиле.
Так вот я просмотрел все доклады с SREcon23 составил для вас подборку из докладов вырезав все доклады в которых было больше болтовни или рекламы чем пользы.

Хотя уменьшение сегодня уже необязательно, оно всё равно лучше.